Tacotron2 + WaveRNN experiments
erogol opened this issue · comments

Tacotron2: https://arxiv.org/pdf/1712.05884.pdf
WaveRNN: https://github.com/erogol/WaveRNN forked from https://github.com/fatchord/WaveRNN
The idea is to add Tacotron2 as another alternative if it is really useful then the current model.
- Code boilerplate tracotron2 architecture.
- Train Tacotron2 and compare results (Baseline)
- Train TTS current model in a comparable size with T2. (Current TTS model has 7M and Tacotron2 has 28M parameters)
- Add TTS specific architectural changes to T2 and compare with the baseline.
- Train WaveRNN a vocoder on generated spectrograms
- Train a better stopnet. Stopnet sometimes misses the prediction that leads to unstable predictions. Maybe it is better to use a RNN as previous TTS version.
- Release LJspeech Tacotron 2 model. (soon)
- Release LJSpeech WaveRNN model. (https://github.com/erogol/WaveRNN)
Best result so far: https://soundcloud.com/user-565970875/ljspeech-logistic-wavernn
Some findings:
- Adding an entropy loss for the attention seems to improve the cases hard to learn the alignment. It forces network to learn more sparse and noise free alignment weights.
entropy = torch.distributions.Categorical(probs=alignments).entropy()
entropy_loss = (entropy / np.log(alignments.shape[1])).mean()
loss += 1e-4 * entropy_loss
Here is the alignment with entropy loss. However, if you keep the loss weight high, then it degrades the model's generalization for new words.
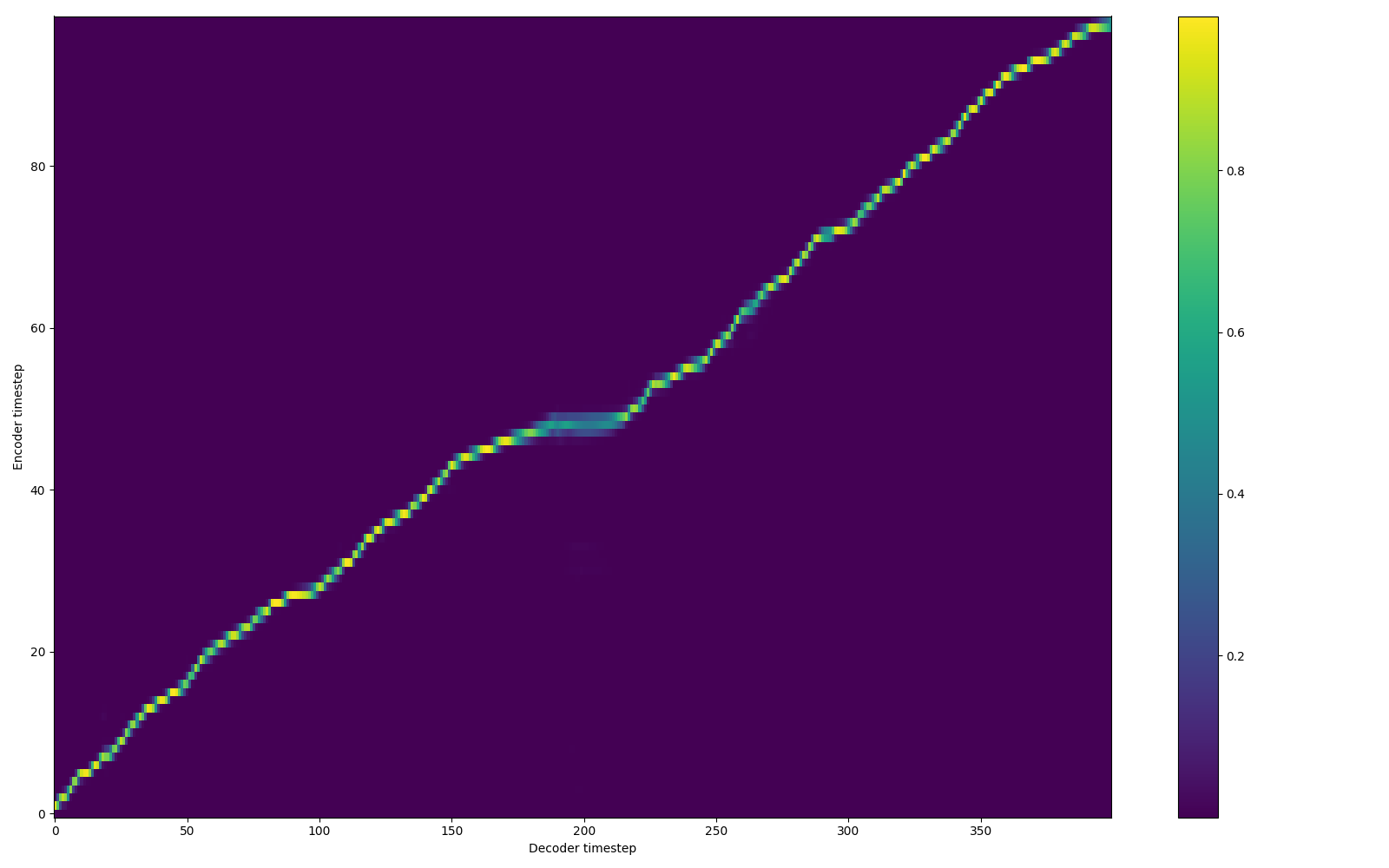
- Replacing Prenet with a BatchNorm version ehnace the performance quite a lot.
- A network with BN Prenet is harder to learn the attention. It looks like the network needs a level of noise onto autoregressive connection to relate encoder output to network output. Otwerwise, in teacher forcing mode, network does not need encoder output since it finds previous prediction frame enough to generate the next frame.
- Forward attention seems more robust to longer sequences and faster to align. (https://arxiv.org/abs/1807.06736)
Tacotron2 baseline implementation aligns after 35K iterations.

Also it gives better melspectrograms L1 loss compared to Tacotron1. Tacotron2 trained 150K iters and Tacotron trained 320K,
Tacotron1 loss: 0.34
Decoder loss: 0.3115
Postnet loss: 0.2985
Tacotron2 + TTS updates aligns much faster after 14K. It also reaches the same loss values of the baseline implementation which it gets after 100K

Here is the attention alignment after 14K


Here is a pocket article read by the mode WaveRNN + Tacotron2
Tacotron2 - 90k iterations
WaveRNN - 550K iterations
https://soundcloud.com/user-565970875/pocket-article-wavernn-and-tacotron2

@erogol Awesome results. Did you train tacotron2 with batch size of 32 and r=1? Was it done on multi-gpu or just one?

@erogol Fatcord's wavernn works very well with 10 bit audio as well, which helps to eliminate quite a bit of the background static.
@ZohaibAhmed I trained it with 4 GPUs with 16 batch size per GPU which is the max I can fit into a 1080ti. Much better results are coming through with couple of architectural changes.
@G-Wang thx for pointing. I am going to try. I just trained WaveRNN once and now I plan to discover some model updates and quantization schemes. I ll let you know here

I'm currently pretty happy with https://github.com/h-meru/Tacotron-WaveRNN/blob/master/README.md
I struggled some time when I integrated a similar model (something between that and the amazon universal vocoder architecture) but in the end I found the reason was just the Noam LR scheme performed much worse than just the fixed LR with Adam which in the worst case I could just reduce a little bit manually when the loss starts to behave funny.
But for LJ the loss function is decreasing textbook-like.
Training WaveRNN with 10bit quantization. Also the final solution in #50 improved the model performance significantly. Results soon to be shared...
@erogol I've tried a few variants such as mu-law, gaussian/beta output, mixture logistics, but I found 9 and 10-bit at the end of the day gave the best result and fastest training, you can hear some samples here: https://github.com/G-Wang/WaveRNN-Pytorch

@erogol There is also a highly optimized pytorch and C++ implementation which I am training on the output of TTS extract_features script: https://github.com/geneing/WaveRNN-Pytorch

@erogol thanks erogol. When could we use the tacotron2 + WaveRNN model to train on our datasets?

Is any pretrained wavernn model available for test?
This is the latest result.
10 bit WaveRNN trained for 400K initiazlied from 9 bit model
Tacotron2 trained for 170K - postnetloss: 0.019 decoderloss: 0.023
Problems:
- There is high peak with "s" sound due to the dataset quality
- Static background noise due to 10 bit quantization
- Some intonation problems due to false Tacotron2 alignment. Maybe it is better to use an earlier checkpoint.
Below is the comparison of BN vs Dropout prenets as explain in #50

Audio Sample:
https://soundcloud.com/user-565970875/commonvoice-1
Audio Sample with the best GL based model:
https://soundcloud.com/user-565970875/sets/ljspeech-model-185k-iters-commit-db7f3d3
Interesting results!
Do you use ground truth aligned mel specs generated by tacotron for training the neural vocoder, or do you train it from features extracted from the recordings?
@m-toman I don't see what you mean by the second option
I trained it with the specs from tacotron with teacher forcing.
Thanks, with the second option I mean just calculating Mel specs from the recordings and then training on those, without using Tacotron at all.
This had a lower MOS in the WaveNet paper so I wondered which approach you used.
In the Amazon universal vocoder paper they did that (I assume) because they train from lots of data from many different speakers and recording conditions, so it's a trickier to use GTA mel specs (although you could do it with a very large multispeaker model I suppose)
@m-toman I was not aware that they show better results by using ground-truth mels specs. However, it does not really make sense to me (without any experimentation) since I believe vocoder is able to learn to obviate the mistakes done by the first network as it is trained with synthesized specs. But I guess to be sure, I need to try first.
No, they were worse (lower MOS 1-5 with 5 as the best score) as expected.
Just checked, it wasn't in the Wavenet paper, it was in the Taco2 paper:
https://arxiv.org/pdf/1712.05884.pdf in 3.3.1
"As expected, the best performance is obtained when the features
used for training match those used for inference. However, when
trained on ground truth features and made to synthesize from predicted features, the result is worse than the opposite. This is due to
the tendency of the predicted spectrograms to be oversmoothed and
less detailed than the ground truth – a consequence of the squared
error loss optimized by the feature prediction network. When trained
on ground truth spectrograms, the network does not learn to generate
high quality speech waveforms from oversmoothed features."
So that's fine.
Is there a script in the repo to produce the teacher forced data for the training set?

@erogol is that using @fatchord's Alternative Model (from their 4a/4b Jupyter notebooks)? From my limited understanding it's quite different from the model described in the WaveRNN paper. So if Fatchord's Alternative Model is being used, perhaps it's a good idea to refer to it as such (or something similar) to both avoid confusing it with the one from the WaveRNN paper and to attribute the model to the correct individual.
Here is WaveRNN trained with single Gaussian output with 16bit. It looks promising but it is buzzing in the silence parts and the tone of the generated speech is somehow different than the training set.
WaveRNN with a mixture of logistic distribution output. Best result so far.
https://soundcloud.com/user-565970875/ljspeech-logistic-wavernn
@erogol what could i say... The result is so good that astonished me...
@erogol nice quality. How many training step is this? Are you using r9r9's mixture logistics implementation? Or your own?
@G-Wang I've not tried all the checkpoints, but the final is after almost 4 days of training.
Yes it is from wavenet.

@Raza25 Are you trying to deploy TTS model to production environment ?

@tsungruihon yes I am looking forward to it, but the overhead lies in the inference time. I want to quantize model weights, for efficient and speedy inference.
@Raza25 Tacotron (from https://github.com/Rayhane-mamah/Tacotron-2) without any quantizations is able to synthesize about 2x faster than real time on a laptop CPU. I tested TTS inference too and I was getting odd results. For some sentences it would also synthesize at 2x faster than real time, but I would add a word and suddenly it would take 5 times longer. I haven't had time to debug the problem, but it may be pytorch related.
Also, note that quantization doesn't really improve inference time - overhead of de-quantizing is usually higher than reduction in memory transfer overhead (except for mobile processors). Quantization allows you to compress the weight file. Pruning of weights does improve performance, but for a complex network like this one it will be a very significant project. There are tools that automate the process, if you are up to the task: https://nervanasystems.github.io/distiller/index.html
@Raza25 https://nervanasystems.github.io/distiller/index.html is a good option. @reuben was looking into it.
To my experience, TTS with Tacotron2 is real-time with GL in use. Tacotron1 is much faster. However, I cannot say x2 faster for an encoder-decoder model since the execution time does not scale linearly with the number of inputs due to the attention computation each time.
You can also have a faster execution if you train the model with graphemes since you bypass the phoneme extraction phase.
Right now my emphasis is the model quality but after a while, I should also worry about the speed.
@Raza25 hello my friend, have you succeed in converting TTS to ONNX format ?
@tsungruihon I managed to get a speedy inference by reducing the param griffin_lim_iters.
Even reducing the param griffin_lim_iters, the speed is still too slow. I noticed that maybe we could try simultaneously inference
@tsungruihon too slow? Please give some values.
@erogol From my preliminary observation, if voice length is 2s, then the griffin lim (60 iterations) takes about 4s (running under the CPU) to synthesis. And i also found that the most time consuming parts are istft and stft function. Now i am trying to rewrite the istft and stft functions to make it faster. Also i am trying to implement PyTorch version Griffin Lim that used in Nvidia-Tacotron2.
| > denormalize time is 0.003355264663696289
| > db to amp time is 0.03660082817077637
| > [GL]angles_process time is 0.04900026321411133
| > [GL]S_complex time is 0.0009238719940185547
[GL Loop]istft time is 0.030443668365478516
[GL Loop]stft time is 0.013958930969238281
[GL Loop]istft time is 0.03080582618713379
[GL Loop]stft time is 0.014487028121948242
[GL Loop]istft time is 0.029745101928710938
[GL Loop]stft time is 0.013957023620605469
[GL Loop]istft time is 0.029639005661010742
[GL Loop]stft time is 0.01421809196472168
[GL Loop]istft time is 0.031349897384643555
[GL Loop]stft time is 0.014335870742797852
[GL Loop]istft time is 0.029827594757080078
[GL Loop]stft time is 0.013972997665405273
[GL Loop]istft time is 0.0298464298248291
[GL Loop]stft time is 0.014226436614990234
[GL Loop]istft time is 0.031313419342041016
[GL Loop]stft time is 0.014191865921020508
[GL Loop]istft time is 0.029798269271850586
[GL Loop]stft time is 0.013937950134277344
[GL Loop]istft time is 0.029771089553833008
[GL Loop]stft time is 0.014278888702392578
[GL Loop]istft time is 0.031336307525634766
[GL Loop]stft time is 0.014403581619262695
[GL Loop]istft time is 0.029837846755981445
[GL Loop]stft time is 0.014051198959350586
[GL Loop]istft time is 0.02977585792541504
[GL Loop]stft time is 0.014191150665283203
[GL Loop]istft time is 0.031352996826171875
[GL Loop]stft time is 0.014346599578857422
[GL Loop]istft time is 0.02975296974182129
[GL Loop]stft time is 0.013957977294921875
[GL Loop]istft time is 0.029794931411743164
[GL Loop]stft time is 0.01423788070678711
[GL Loop]istft time is 0.03129386901855469
[GL Loop]stft time is 0.014327526092529297
[GL Loop]istft time is 0.02969503402709961
[GL Loop]stft time is 0.013976335525512695
[GL Loop]istft time is 0.029783964157104492
[GL Loop]stft time is 0.014190196990966797
[GL Loop]istft time is 0.03152155876159668
[GL Loop]stft time is 0.014451265335083008
[GL Loop]istft time is 0.029730558395385742
[GL Loop]stft time is 0.014001131057739258
[GL Loop]istft time is 0.030199527740478516
[GL Loop]stft time is 0.01990532875061035
[GL Loop]istft time is 0.03429985046386719
[GL Loop]stft time is 0.016082763671875
[GL Loop]istft time is 0.0323333740234375
[GL Loop]stft time is 0.015165090560913086
[GL Loop]istft time is 0.032227516174316406
[GL Loop]stft time is 0.015252113342285156
[GL Loop]istft time is 0.03358316421508789
[GL Loop]stft time is 0.01581430435180664
[GL Loop]istft time is 0.03247833251953125
[GL Loop]stft time is 0.015254497528076172
[GL Loop]istft time is 0.032896995544433594
[GL Loop]stft time is 0.015406370162963867
[GL Loop]istft time is 0.0332186222076416
[GL Loop]stft time is 0.01576089859008789
[GL Loop]istft time is 0.03214073181152344
[GL Loop]stft time is 0.015218973159790039
[GL Loop]istft time is 0.03234124183654785
[GL Loop]stft time is 0.015447616577148438
[GL Loop]istft time is 0.03349947929382324
[GL Loop]stft time is 0.015758275985717773
[GL Loop]istft time is 0.032239437103271484
[GL Loop]stft time is 0.014933586120605469
[GL Loop]istft time is 0.03233647346496582
[GL Loop]stft time is 0.015312910079956055
[GL Loop]istft time is 0.03323841094970703
[GL Loop]stft time is 0.015830278396606445
[GL Loop]istft time is 0.032492876052856445
[GL Loop]stft time is 0.015219926834106445
[GL Loop]istft time is 0.03234577178955078
[GL Loop]stft time is 0.01543736457824707
[GL Loop]istft time is 0.03332233428955078
[GL Loop]stft time is 0.015685319900512695
[GL Loop]istft time is 0.03240370750427246
[GL Loop]stft time is 0.015158653259277344
[GL Loop]istft time is 0.028655529022216797
[GL Loop]stft time is 0.015448570251464844
[GL Loop]istft time is 0.03339052200317383
[GL Loop]stft time is 0.015659332275390625
[GL Loop]istft time is 0.03241872787475586
[GL Loop]stft time is 0.015098333358764648
[GL Loop]istft time is 0.03223848342895508
[GL Loop]stft time is 0.01533651351928711
[GL Loop]istft time is 0.03340649604797363
[GL Loop]stft time is 0.01568770408630371
[GL Loop]istft time is 0.032482147216796875
[GL Loop]stft time is 0.01512002944946289
[GL Loop]istft time is 0.03219318389892578
[GL Loop]stft time is 0.015479803085327148
[GL Loop]istft time is 0.03386235237121582
[GL Loop]stft time is 0.01563882827758789
[GL Loop]istft time is 0.03231453895568848
[GL Loop]stft time is 0.015221357345581055
[GL Loop]istft time is 0.03237199783325195
[GL Loop]stft time is 0.015403032302856445
[GL Loop]istft time is 0.033153533935546875
[GL Loop]stft time is 0.015544414520263672
[GL Loop]istft time is 0.03223085403442383
[GL Loop]stft time is 0.014986991882324219
[GL Loop]istft time is 0.032294511795043945
[GL Loop]stft time is 0.015444755554199219
[GL Loop]istft time is 0.03322863578796387
[GL Loop]stft time is 0.015750646591186523
[GL Loop]istft time is 0.03272223472595215
[GL Loop]stft time is 0.015097618103027344
[GL Loop]istft time is 0.032248497009277344
[GL Loop]stft time is 0.015348196029663086
[GL Loop]istft time is 0.033106088638305664
[GL Loop]stft time is 0.015611886978149414
[GL Loop]istft time is 0.03232169151306152
[GL Loop]stft time is 0.01518559455871582
[GL Loop]istft time is 0.03037881851196289
[GL Loop]stft time is 0.013576984405517578
[GL Loop]istft time is 0.030075788497924805
[GL Loop]stft time is 0.014576911926269531
[GL Loop]istft time is 0.02974987030029297
[GL Loop]stft time is 0.013988256454467773
[GL Loop]istft time is 0.029740095138549805
| > Griffin_lim_total time is 4.830284118652344
@tsungruihonI think pytorch version is not faster in CPU, which is I guess the main concern for most of the deployed systems. You can also test it before going on further.
Have tried 30 iterations with GL? In my system both 30 and 60 iterations are shorter than the audio length.
It is also better to move this discussion to #19 to keep this thread clear.

Hi erogol,
I am currently trying your BN solution for the Prenet in Tacotron-2. I posted also in #50, sorry for the duplicate. I had some doubts regarding BN/LN:
- Is this applied after each Prenet layer?
- What is the activation function of your BN Prenet?
You say it is harder to learn the attention if you apply BN. I wonder wether this is or not a good solution for learning more robust alignments (in the sense of attention not getting lost for some sentences), or it is just good in terms of sound quality.
Thanks!
- yes it is applied after each layer
- relu applied after BN layer.
It is hard to learn the attention with BN yes. My solution so far is to train the original model (dropout prenet) after attention gets aligned, I switch to BN prenet. Here is the difference between two models. Red is the original model continues to train and orange is the BN model.

WaveRNN checkpoints are amateurishly released. https://github.com/erogol/WaveRNN
Hi erogol,
In your initial post you mention:
- Train a better stopnet. Stopnet sometimes misses the prediction that leads to unstable predictions. Maybe it is better to use a RNN as previous TTS version.
I see you have it checked. What did you do regarding this to better predict the stop token?
Thanks!
@alexdemartos my solution is a bit tricky and model specific. However, if you need to solve it once and for all, then I suggest you replace the stopnet layer with RNN. That'd seal the deal :)

The pretrained wavernn only works with Taco2 right now, correct? Tried the Benchmark ipynb with the pretrained WaveRNN and my Taco1 model, and I am getting some dimensionality errors when using the WaveRNN. Coudl be because Taco1 returns linear postnet outputs and taco2 returns mel.
@twerkmeister you can try to use the melspectrogram output (decoder output) but I'd guess, the quality would not be on par.
Hi again! Just a question on the stop token issue again.
I noticed you're not adding eos token and you're using s_i and y_i (decoder hidden + mel projection) as input to the stopnet instead of s_i and c_i (decoder hidden + context vector):
stopnet_input = torch.cat((self.decoder_hidden, decoder_output), dim=1)
Just wondering: have you find any improvements by doing it this way? What is your intuition behind this?
Thanks again! :)
PD: This worked like a charm
@alexdemartos my solution is a bit tricky and model specific. However, if you need to solve it once and for all, then I suggest you replace the stopnet layer with RNN. That'd seal the deal :)

Hi erogol,
Have you considered the option to use LPCNet for synthesis instead of WaveRNN?
I've managed to use plain Tacotron implementation (r=5) with WaveRNN, the results are relatively good, however there is a specific 'clicking' in the WaveRNN output at some 320k iterations (waveRNN is trained only on the wavs, without extracting gta mels from Tacotron). Will the clicking go away with more training, should I train with gta mels from Tacotron, or should I try Tacotron with r=1?
I've also changed the WaveRNN code to save best model based on the evaluation, it gives better results than from checkpoints.
@ljackov I like to try LPCNet but I've no workspace for it for now. And it is keras adding one more dependency/
I'd say training with generated mels would improve it. It might work with r=5 but as you go lower it generates better mel spectrograms but takes more time and makes attention more sensitive. So there is a trade-off needs to be set wisely.
Is tacotron from TTS or another library?
Makes sense to keep the best model. I prefer to check checkpoints manually to pick the best one. Sometimes loss does not correspond to real voice performance.
Hi Erogol,
Thanks for the prompt reply!
Tacotron is your implementation (dev-tacotron2, plain Tacotron, not 2), as well as WaveRNN. r=1 is really slow for me, I guess I'd give it a go some time later. I feed in the decoder output into WaveRNN. I've also tried it with mels from the linear spectrum (postnet output), but it's not as good.
An interesting thing is that I train Tacotron on large TTS-generated speech corpus, and then I switch it to train on a real speaker small corpus. The results are pretty good, and I wonder if even bigger speech corpus would be beneficial for the initial Tacotron training. Currently I'm using one with the size of LJSpeech (23k sentences, 50-150 chars). All this is for Bulgarian :)
What I've noticed about WaveRNN is that keeping the best model after epoch end usually outperforms the checkpoints (I also check them manually). Maybe it's because usually the checkpoint is in the middle of the epoch. I also keep multiple best models so that I can compare them.
Also, is there any benefit in training Tacotron2 with r=5 (say 100k iter) and then switching to r=1?
I didn't not try progressive training with Tacotron2. It is though not implemented. However, you can try with your Tacotron model. You can reduce r=1 and init the model with your previous model r=5. I suppose it would be faster to converge in relation to bottom-up r=1 training.
In short, bigger the dataset, better the results.
Linear spectrogram has a lot of redundancy for WaveRNN. Therefore maybe it is harder to train. Also it is killing the memory. However, you can reduce the final output dimension to 80 and predict mel spectrograms with tacotron. I don't know if you use decoder outputs or postnet outputs for your WaveRNN?
I didn't try to train WaveRNN from linear spectrogram, I just used the linear spectrogram (postnet_out of Tacotron) to create mel spectrogram to be fed into WaveRNN. However, it proved worse than using decoder_out of Tacotron.
I didn't modify the Tacotron1 model, I just used the decoder output for WaveRNN (i.e. modified the synthesizer not to use GL but WaveRNN, taking data from the decoder_out variable (not the postnet_out as in Tacotron2)
I've just chanced upon WaveGlow (https://github.com/NVIDIA/waveglow). Do you think it might be good to try instead of WaveRNN?
Might be slow to train but can also work. It'd be interesting to see your results.
I was attracted by the synthesis speed (i.e. probably suitable for mobile devices), however the model size is not very appropriate for such devices :( I may give it a go some time later.
Can you give me any hints on porting the Tacotron model to OpenCV?
sorry, no idea.
Hi again,
Is there a reason to pad externally with ConstantPad1d and not use the Conv1d padding in Tacotron/CBHG/BatchNorm1d? If there is no difference, I think using the Conv1d padding would be faster.
Conv1d does not support asymmetric padding. And please don't place random questions to random places.
I have tested tacotron2 + wavernn models on CPU, I have checked np.sum(mel_specs) and np.sum(waveform) and it gives me different output each run, tacotron2 results are consistent, so wavernn results different across runs.
As I understand source of randomness is in sample_from_discretized_mix_logistic
So I added
torch.manual_seed(0)
torch.cuda.manual_seed_all(0)
to https://github.com/erogol/WaveRNN/blob/master/utils/distribution.py
And this fixes reproducibility issue.
But still if I call same model on same input twice in a row I don't get the same result, does it have some internal state that should be release before second run?
As I can see here:
https://github.com/erogol/WaveRNN/blob/master/models/wavernn.py#L108
Model uses nn.GRU layers
I'm not sure why is nn.GRU converted to nn.GRUCell here:
https://github.com/erogol/WaveRNN/blob/master/models/wavernn.py#L227
Also seems here hidden state is setted to zeros, so do I need it to set it to zeros before call generate function?
https://github.com/erogol/WaveRNN/blob/master/models/wavernn.py#L117
Update:
The problem was in random seed, to fix it:
def generate(self, mels, batched_inference, target, overlap):
# Fix random seed for reproducible results
seed = 42
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(seed)

al model (dropout prenet) after attention gets aligned, I switch to BN prenet. Here is the difference be
hey Eren,
when you 'switch to BN prenet' and continue training, any changes to the lr or you just use the restored lr?
Hey! ... no change.
I'm trying to reproduce WaveRnn results on single GPU and it's quite slow(i.e. days of training).
Here is my samples at checkpoint_230000 vs checkpoint_433000 (provided by @erogol) for same predicted mel spectrogram from tacotron2: examples.zip
I wonder this meaningless speech is normal and is just due to smaller number of steps or something is really broken?
something is really broken. I guess the char symbol order in the code does not match with the model.
Yes, it still broken at 600k steps, but I'm training WaveRnn model only (on mel-spectrograms prepared by tacotron2 model), so as I understand char symbol order is not relevant here, because I only have mel spectrograms and wav files.
https://github.com/erogol/WaveRNN/blob/master/dataset.py#L17
Also I have checked prepared mel-spectrogram *.npy file by griffin-lim and by checkpoint_433000 model and in both cases it works fine.
In ExtractTTSpectrogram.ipynb for LJspeech data preparation I have used config.json from ljspeech-260k tacotron2 model that can affect AudioProcessor, however the only difference that I can see is do_trim_silence parameter, can it cause problems?
In Tacotron2 config:
"do_trim_silence": true // enable trimming of slience of audio as you load it. LJspeech (false), TWEB (false), Nancy (true)
In WaveRNN config:
"do_trim_silence": false // KEEP ALWAYS FALSE
https://github.com/erogol/WaveRNN/blob/master/config.json#L25
Also I have tried just to clone master of WaveRnn and use pretrained model:
git clone https://github.com/erogol/WaveRNN.git WaveRNN-master-test
In models/wavernn.py
#from ..utils.distribution import sample_from_gaussian, sample_from_discretized_mix_logistic
from utils.distribution import sample_from_gaussian, sample_from_discretized_mix_logistic
CUDA_VISIBLE_DEVICES=1 python train.py --data_path /data_large/tts-datasets/LJSpeech-1.1-wavernn/ --output_path experiment_temp --restore_path ./mold_ljspeech_best_model/checkpoint_433000.pth.tar --config_path ./mold_ljspeech_best_model/config.json
Next saved checkpoint checkpoint_434000.pth.tar is producing garbage, but ./mold_ljspeech_best_model/checkpoint_433000.pth.tar works fine.
Yes, seems problem was in do_trim_silence and running from pretrained model gives sensible results now, loss is about 5.2
But why WaveRnn have problems with do_trim_silence? as I understand predicted mel-spectrogram from tacotron2 not obliged to be 'aligned' to wav file.
I am finalizing this thread since we solved Tacotron2 + WaveRNN
Seems about 300k steps is sufficient:
wavernn_samples.zip
@erogol Can you elaborate on do_trim_silence parameter?
trims silences at the beginning and the end by thresholding.

When training WaveRNN with mels from Tacotron2, which wavs do you use, the ground truth wavs file or the wavs generated by Tacotron2?
When I use the ground truth wavs, there are some bugs in MyDataset.collate, coarse = np.stack(coarse).astype(np.float32). The items in coarse have different shape. I think this is due to the wrong sig_offsets. The slicing operation x[1][sig_offsets[i] : sig_offsets[i] + seq_len + 1] is outside the range of x[1] sometimes.
But I don't know how to fix it.
May i ask how much time that cost you to train 300k steps using wavernn?
@chynphh I faced that problem too. Have you solved it yet ?

When training WaveRNN with mels from Tacotron2, which wavs do you use, the ground truth wavs file or the wavs generated by Tacotron2?
When I use the ground truth wavs, there are some bugs in
MyDataset.collate,coarse = np.stack(coarse).astype(np.float32). The items in coarse have different shape. I think this is due to the wrongsig_offsets. The slicing operationx[1][sig_offsets[i] : sig_offsets[i] + seq_len + 1]is outside the range of x[1] sometimes.But I don't know how to fix it
When training WaveRNN with mels from Tacotron2, which wavs do you use, the ground truth wavs file or the wavs generated by Tacotron2?
When I use the ground truth wavs, there are some bugs in
MyDataset.collate,coarse = np.stack(coarse).astype(np.float32). The items in coarse have different shape. I think this is due to the wrongsig_offsets. The slicing operationx[1][sig_offsets[i] : sig_offsets[i] + seq_len + 1]is outside the range of x[1] sometimes.But I don't know how to fix it.
I am facing the same issue. Is it solved yet?
it might be about triming the noise. Try diabling it if it is enabled or the otherway around.

Hi @ethanstan what branches are you using? I found out that you need to use Tacotron 2 from the branch https://github.com/mozilla/TTS/tree/Tacotron2-iter-260K-824c091 and I think I used the WaveRNN from the Master branch.
@Ivona221 I'm using the current TTS tacotron 2 master branch. Does this mean I need to retrain from that branch? I'm pretty happy with the output from Tacotron2 right now. Do you know if it was something in the config or what changed? Thank you!
@Ivona221 I'm using the current TTS tacotron 2 master branch. Does this mean I need to retrain from that branch? I'm pretty happy with the output from Tacotron2 right now. Do you know if it was something in the config or what changed? Thank you!
Yes when i was training I needed to change to that branch and train another model. The results are a bit worst, at least for my dataset (Macedonian language) but it is the only way I made it work.