LayoutLMv3 document layout train error
yuumiin opened this issue · comments

Describe
Model I am using LayoutLMv3
after running object_detection/train_net.py
cuda error RuntimeError: CUDA out of memory
Error occurred after adjusting IMS_PER_BATCH in cascade_layoutlmv3.yaml
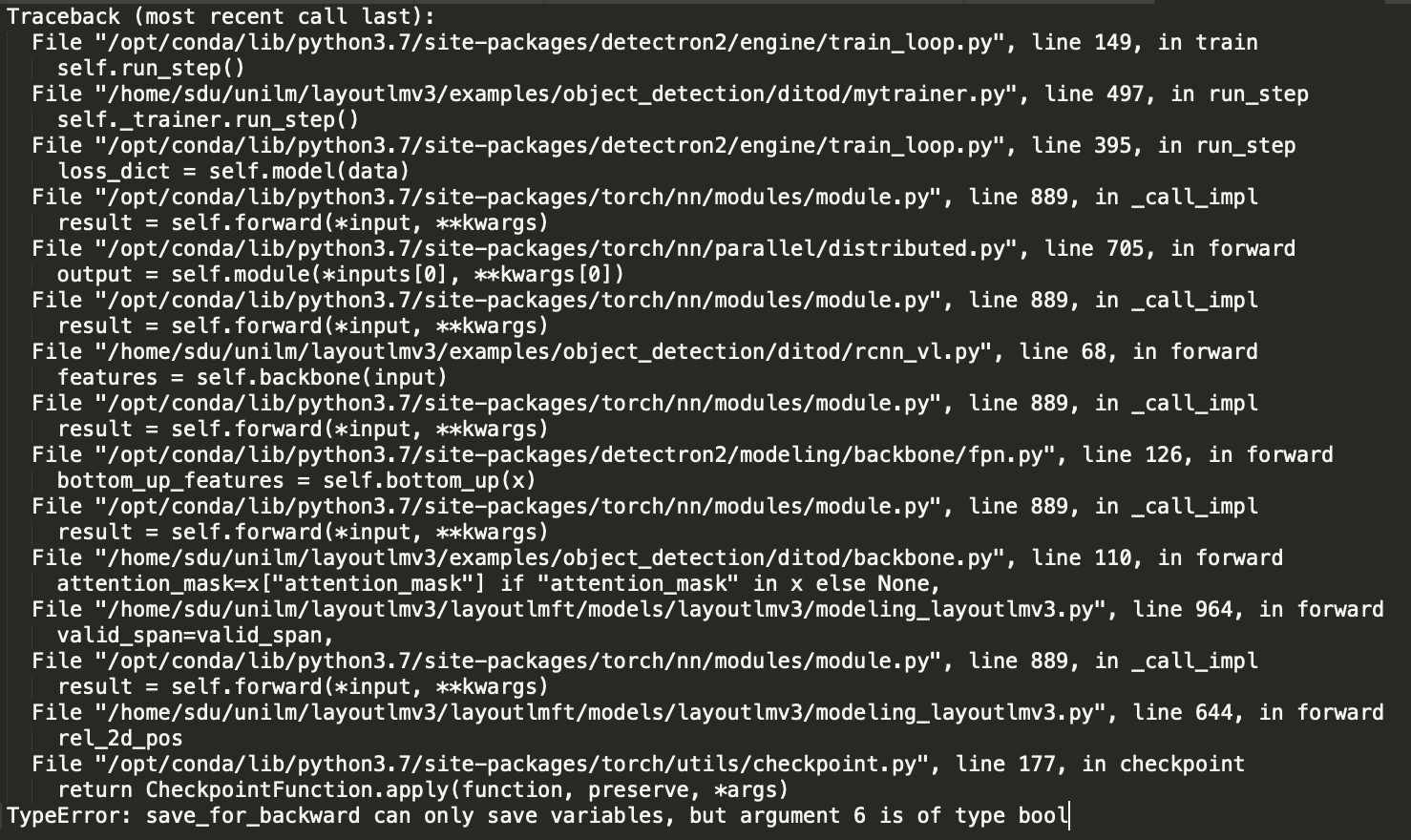
TypeError: save_for_backward can only save variables, but argument 6 is of type bool
How to solve it???

It is hard to locate the cause of errors and debug without error stack traces.
Have you set IMS_PER_BATCH to a multiple of your GPU size? For example, if you are using 8 GPUs, then you could set IMS_PER_BATCH to 8, 16, etc.

@HYPJUDY
I also encountered this problem,How can I solve it?

Same here, interesting..
I am using PyTorch 1.8.0 and I suspect there can be issues with this version.
This problem happens inside gradient checkpointing function in Torch.
In PyTorch 1.8.0, the gradient checkpointing function saves everything in the input for backward, which must be torch.tensors. This can be problematic if there are non-tensor input as function input (layer_module.forward in this case). Below is the source code of CheckPointFunction in Torch 1.8.0:
class CheckpointFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, run_function, preserve_rng_state, *args):
check_backward_validity(args)
ctx.run_function = run_function
ctx.preserve_rng_state = preserve_rng_state
ctx.had_autocast_in_fwd = torch.is_autocast_enabled()
if preserve_rng_state:
ctx.fwd_cpu_state = torch.get_rng_state()
# Don't eagerly initialize the cuda context by accident.
# (If the user intends that the context is initialized later, within their
# run_function, we SHOULD actually stash the cuda state here. Unfortunately,
# we have no way to anticipate this will happen before we run the function.)
ctx.had_cuda_in_fwd = False
if torch.cuda._initialized:
ctx.had_cuda_in_fwd = True
ctx.fwd_gpu_devices, ctx.fwd_gpu_states = get_device_states(*args)
ctx.save_for_backward(*args)
with torch.no_grad():
outputs = run_function(*args)
return outputsHowever, this issue is fixed in PyTorch 1.10.0, as also explained in this blog. The difference lies in L27-L41.
So update your PyTorch version should fix the issue.

Windows: set 'PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:512'
Linux: export 'PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:512'