Aural
Aural is a simple, elegant ASR framework not like Kaldi style, it's more clean and pythonic, can be easily used and understandable, supports both English and Chinese. You can also train on it. Then using the output model to driven more applications which need ASR.
We hoping for u join us, if you are interested in:
- Keywords spotting task for Chinese;
- ASR model inference on NCNN, WNN or ONNXRuntime.
- An AI assistence which can understand your voice in REALTIME speed;
For instance, we can using aural model to listen command, just by saying, let your AI can understand what you saying.
We will exporting the ASR model and inference via WNNX.
Aural is build based on k2, and mostly reconstructed from icefall.
Be note:
Due to it need kaldifeat and kaldialign for data process, Windows not support for now, working on it.
Aural is much more simpler than icefall or wenet.
Install
Before runing aural, there are some deps need to install:
pip install pydub
pip install kaldifeat
pip install kaldialign
pip install alfred-py
pip install sentencepiece
In addition, k2 is better install from source:
git clone https://github.com/k2-fsa/k2/
cd k2
python setup.py install
Demo
demo for English librispeech data:
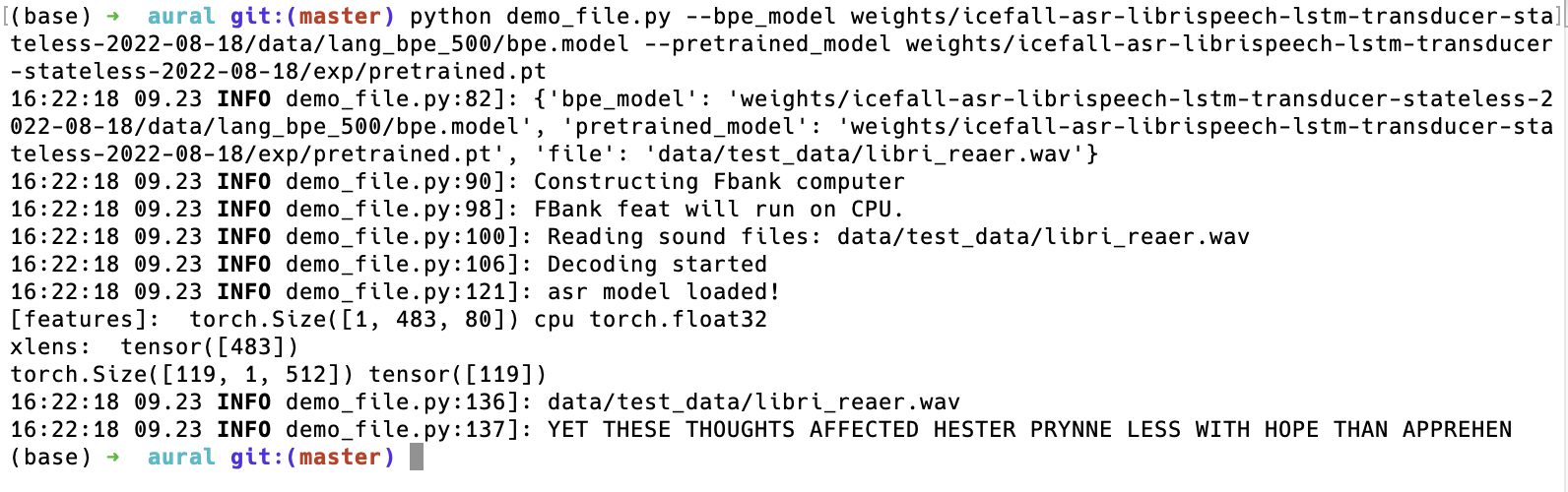
Before training, we can test on the correctness of the mode, using a pretrained model which comes from icefall:
git clone https://huggingface.co/csukuangfj/icefall-asr-librispeech-lstm-transducer-stateless2-2022-09-03
git clone https://huggingface.co/Zengwei/icefall-asr-librispeech-lstm-transducer-stateless-2022-08-18/
this should download token, bpe, pretrained_model which we need enough to inference it. Be note that, Aural doesn't need any icefall code, it can run itself, compatible with icefall trained model.
Move your cloned file to weights, then run:
python demo_file.py --bpe_model weights/icefall-asr-librispeech-lstm-transducer-stateless-2022-08-18/data/lang_bpe_500/bpe.model --pretrained_model weights/icefall-asr-librispeech-lstm-transducer-stateless-2022-08-18/exp/pretrained.pt
demo for Chinese wenetspeech data:
Download wenet pretrained model:
git clone https://huggingface.co/luomingshuang/icefall_asr_wenetspeech_pruned_transducer_stateless2
git lfs pull
Then, using command line to inference on a wav file:
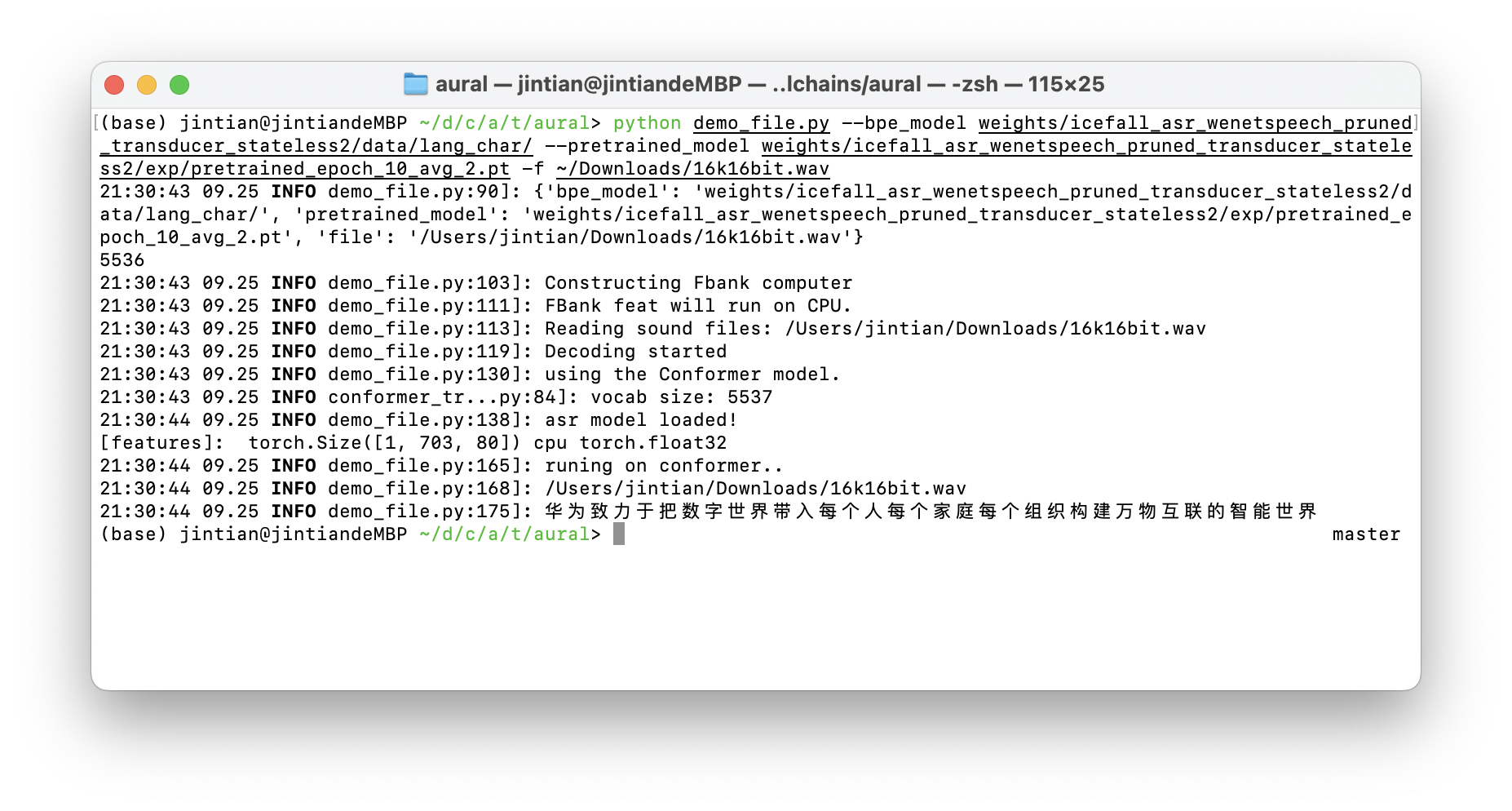
python demo_file.py --bpe_model weights/icefall_asr_wenetspeech_pruned_transducer_stateless2/data/lang_char/ --pretrained_model weights/icefall_asr_wenetspeech_pruned_transducer_stateless2/exp/pretrained_epoch_10_avg_2.pt -f data/test_data/16k16bit.wav
You will get output:
21:26:18 09.25 INFO demo_file.py:119]: Decoding started
21:26:18 09.25 INFO demo_file.py:130]: using the Conformer model.
21:26:18 09.25 INFO conformer_tr...py:84]: vocab size: 5537
21:26:19 09.25 INFO demo_file.py:138]: asr model loaded!
[features]: torch.Size([1, 703, 80]) cpu torch.float32
21:26:19 09.25 INFO demo_file.py:165]: runing on conformer..
21:26:19 09.25 INFO demo_file.py:168]: /Users/jintian/Downloads/16k16bit.wav
21:26:19 09.25 INFO demo_file.py:175]: 华为致力于把数字世界带入每个人每个家庭每个组织构建万物互联的智能世界
Using following to convert to onnx:
git clone https://huggingface.co/luomingshuang/icefall_asr_wenetspeech_pruned_transducer_stateless2
python export_onnx.py --pretrained_model weights/icefall_asr_wenetspeech_pruned_transducer_stateless2/exp_trained_with_M/pretrained_epoch_29_avg_11.pt --bpe_model weights/icefall_asr_wenetspeech_pruned_transducer_stateless2/data/lang_char/
python export_test.py -p weights/icefall_asr_wenetspeech_pruned_transducer_stateless2/exp/pretrained_epoch_10_avg_2.pt -l weights/icefall_asr_wenetspeech_pruned_transducer_stateless2/data/lang_char/ --onnx true
Export JIT ONNX
export to jit pnnx
To export the model for JIT for onnx:
python export.py --pretrained_model weights/icefall-asr-librispeech-lstm-transducer-stateless-2022-08-18/exp/pretrained.pt --bpe_model weights/icefall-asr-librispeech-lstm-transducer-stateless-2022-08-18/data/lang_bpe_500/bpe.model
export to onnx
Currently only tested Chinese version:
python export_onnx.py --bpe_model weights/icefall_asr_wenetspeech_pruned_transducer_stateless2/data/lang_char/ --pretrained_model weights/icefall_asr_wenetspeech_pruned_transducer_stateless2/exp/pretrained_epoch_10_avg_2.pt
You will get 3 models inside weights/onnx
Inference using NCNN
Run:
python demo_file_ncnn.py \
--bpe-model-filename ./weights/icefall-asr-librispeech-lstm-transducer-stateless-2022-08-18/data/lang_bpe_500/bpe.model \
--encoder-param-filename ./weights/encoder_jit_trace-pnnx.ncnn.param \
--encoder-bin-filename ./weights/encoder_jit_trace-pnnx.ncnn.bin \
--decoder-param-filename ./weights/decoder_jit_trace-pnnx.ncnn.param \
--decoder-bin-filename ./weights/decoder_jit_trace-pnnx.ncnn.bin \
--joiner-param-filename ./weights/joiner_jit_trace-pnnx.ncnn.param \
--joiner-bin-filename ./weights/joiner_jit_trace-pnnx.ncnn.bin \
./data/test_data/1221-135766-0001.wav
You should using customized ncnn branch with some modification.
https://github.com/jinfagang/ncnn/tree/merge_xx
C++ Deployment
The exported model can also using C++ to inference. See this project:
https://github.com/jinfagang/sherpa_ort.git
References
Copyright
all rights reserverd by Lucas Jin.