Known log formats in benchmarks
bripkens opened this issue · comments

The repository's readme makes it seem like the benchmarks evaluate both parsing to structured logs and template identification.
An example of log parsing
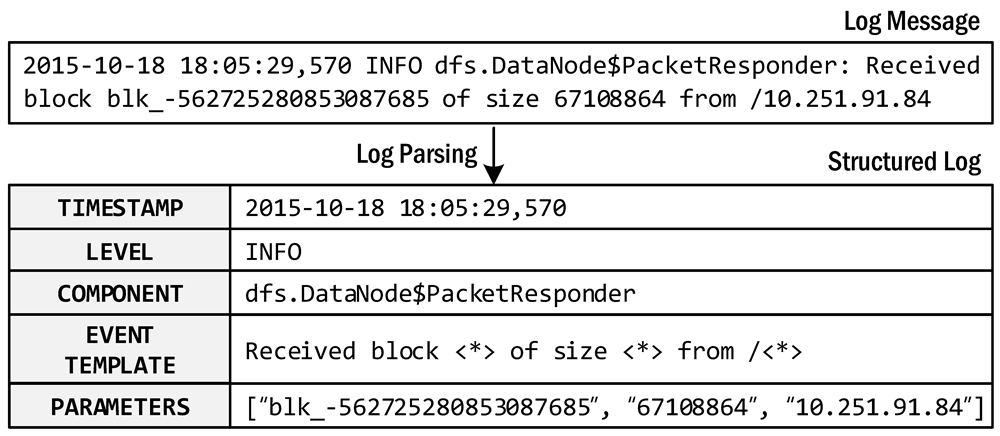
[…] By applying logparser, users can automatically extract event templates from unstructured logs and convert raw log messages into a sequence of structured events […]
However, when looking at the actual benchmarks, it can be seen that the implementations work based on known log formats per input file, e.g., in the Brain benchmark.
logparser/logparser/Brain/benchmark.py
Line 32 in 18dcd31
Am I missing some details, or do the algorithms really not concern themselves with the automatic identification of common logging fields, i.e., the conversion to structured logs without any prior knowledge? To clarify, I expected a native notion of time, severity etc. Which arguably requires some defined semantics that may or may not be shared across logs.
This is not meant to question the value of this project or the algorithms. I only mean to resolve my expectation mismatch :)

The logparser is aimed to identify the structure in the <Content>, since the format you provided is already easy to define by a line of regrex. It is unnesseary to use other tools to do so.
Interesting. In my space, it is common to have raw log lines of unknown format – and consequently, no regular expression to parse those log lines.
Hence, the image in the readme caused this confusion. From my perspective, it is showing (at least) two steps:
- Extraction of semantic values from character sequences to identify
- time
- severity
- …
- log bodies
- Identifying patterns in the log bodies
I am not proposing that you change anything. Just making you aware of step 1) which is a continuous industry challenge :)