Use this template to rapidly bootstrap a DL project:
- Write code in Pytorch Lightning's
LightningModuleandLightningDataModule. - Run code from composable
yamlconfigurations with Hydra. - Manage packages in
environment.yamlwith conda. - Log and visualize metrics + hyperparameters with Tensorboard.
- Sane default with best/good practices only where it makes sense for small-scale research-style project.
Have an issue, found a bug, know a better practice? Feel free to open an issue, pull request or discussion thread. All contribution welcome.
I hope to maintaining this repo with better deep learning engineering practices as they evolve.
Click to expand/collapse
# clone project or create a new one from GitHub's template
git clone https://github.com/lkhphuc/lightning-hydra-template new-project
cd new-project
rm -rf .git
git init # Start of a new git history- Edit
setup.pyand add relevant information. - Rename the directory
project/to the your project name.
- Name your environment and add packages in
environment.yaml, then create/update the environment with:
# Run this command every time you update environment.yaml
conda env update -f environment.yamlLightningModules are organized underproject/model/.LightningDataModules are organized underproject/data/.
Each Lightning module should be in one separate file, while each file can contain all the relevant nn.Modules for that model.
Each .py file has its own corresponding .yaml file, such as project/model/autoencoder.py and configs/model/autoencoder.yaml.
All yaml files are stored under configs/ and the structure of this folder should be identical to the structure of the project/.
$ tree project $ tree configs
project configs
├── __init__.py ├── defaults.yaml
├── data ├── data
│ ├── cifar.py │ ├── cifar.yaml
│ └── mnist.py │ └── mnist.yaml
└── model ├── model
├── autoencoder.py │ ├── autoencoder.yaml
├── classifier.py │ └── classifier.yaml
└── optim
├── adam.yaml
└── sgd.yamlconfigs/defaults.yaml contains all the defaults modules and arguments, including that for the Trainer().
# This will run with all the default arguments
python main.py
# Override defaults from command line
python main.py model=autoencoder data=cifar trainer.gpus=8This section will provide a brief introduction on how these components all come together. Please refer to the original documents of Pytorch Lightning, Hydra and TensorBoard for details.
Click to expand/collapse
The launching point of the project is main.py located in the root directory.
The main() function takes in a DictConfig object, which is prepared by hydra based on the yaml files and command line arguments provided at runtime.
This is achieved by decorating the script main() function with hydra.main(), which requires a path to all the configs and a default .yaml file as follow:
@hydra.main(config_path="configs", config_name="defaults")
def main(cfg: DictConfig) -> None: ...This allow us to define multiple entry points for different functionalities with different defaults, such as train.py, ensemble.py, test.py, etc.
We will use Hydra to instantiate objects.
This allow us to use the same entry point (main.py above) to dynamically combine different models and data modules.
Given a configs/defaults.yaml file contains:
defaults:
- data: mnist # Path to sub-config, can also omit the .yaml extension
- model: classifier.yaml # full path for ease of navigation (e.g vim cursor in path, press gf)Different modules can be instantiated for each run by supplying a different set of configuration:
# Using default
$ python main.py
# The default is equivalent to
$ python main.py model=classifier data=mnist
# Override a default module
$ python main.py model=autoencoder
$ python main.py data=cifar
# Override multiple default modules and arguments
$ python main.py model=autoencoder data=cifar trainer.gpus=4In python, the module will be instantiated by a line, for example data_module = hydra.utils.instantiate(cfg.data).
cfg.data is a DictConfig object created by hydra at runtime, and is stored in a config file, for example configs/data/mnist.yaml:
name: mnist
# _target_ class to instantiate
_target_: project.data.MNISTDataModule
# Argument to feed into __init__() of target module
data_dir: ~/datasets/MNIST/ # Use absolute path
batch_size: 4
num_workers: 2
# Can also define arbitrary info specific to this module
input_dim: 784
output_dim: 10and the target: project.data.MNISTDataModule to be instantiated is:
class MNISTDataModule(pl.LightningDataModule):
def __init__(self, data_dir: str = "",
batch_size: int = 32,
num_workers: int = 8,
**kwargs): ...
# kwargs is used to handle arguments in the DictConfig but not used for initSince hydra manages our entry point and command line arguments, it also manages the output directory of each run.
We can easily customize the output directory to suit our project via defaults.yaml
hydra:
run:
# Configure output dir of each experiment programmatically from the arguments
# Example "outputs/mnist/classifier/baseline/2021-03-10-141516"
dir: outputs/${data.name}/${model.name}/${experiment}/${now:%Y-%m-%d_%H%M%S}and tell TensorBoardLogger() to use the current working directory without adding anything:
tensorboard = pl.loggers.TensorBoardLogger(".", "", "")Click to expand/collapse
Each modules should be self-contained and self-explanatory, to maximize reusability, even across projects.
- Don't do this:
class LitAutoEncoder(pl.LightningModule):
def __init__(self, cfg, **kwargs):
super().__init__()
self.cfg = cfgYou will not like it when having to track down the config file every time just to remember what are the input arguments, their types and default values.
- Do this instead:
class LitAutoEncoder(pl.LightningModule):
def __init__(self,
input_dim: int, output_dim: int, hidden_dim: int = 64,
optim_encoder=None, optim_decoder=None,
**kwargs):
super().__init__()
self.save_hyperparameters()
# Later all input arguments can be accessed anywhere by
self.hparams.input_dim
# Use this to avoid boilderplate code such as
self.input_dim = input_dim
self.output_dim = output_dimAlso see Pytorch Lightning's official style guide.
- Use forward slash
/in naming metrics to group it together.- Don't:
loss_val,loss_train - Do:
loss/val,loss_train
- Don't:
- Group metrics by type, not on what data it was evaluate with:
- Don't:
val/loss,val/accuracy,train/loss,train/acc - Do:
loss/val,loss/train,accuracy/val,accuracy/train
- Don't:
- Log computation graph of
LightningModuleby:- Define
self.example_input_arrayin your module's__init__() - Enable in TensorBoard with
TensorBoard(log_graph=True)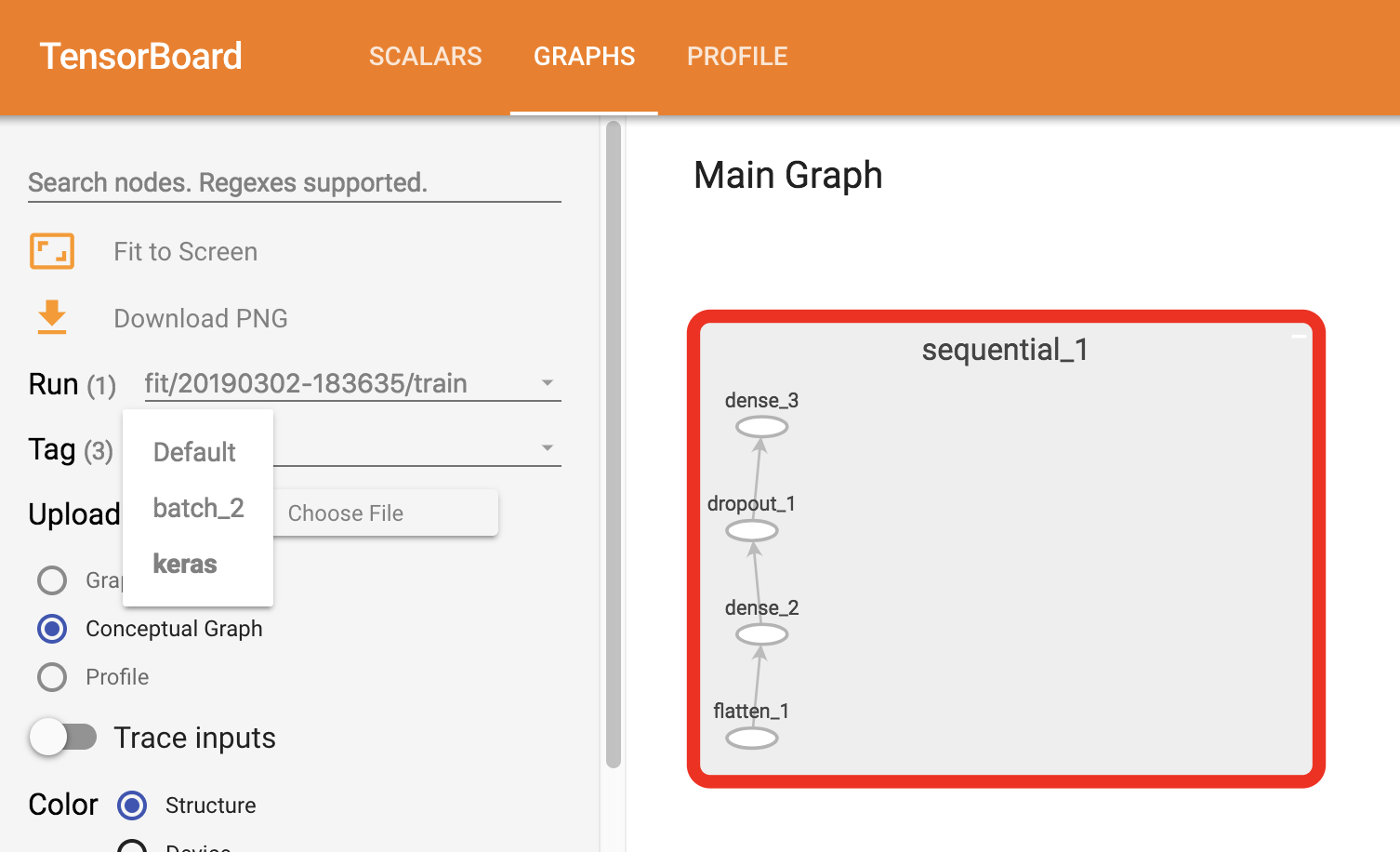
- Define
- Proper loggin of hyper-parameters and metrics
Hydra serves two intertwined purposes, configuration management and script launcher. These two purposes are dealt with jointly because each run can potentially has a different set of configs.
This provides a nice separation of concerns, in which the python scripts only focus on the functionalities of individual run, while the hydra command line will orchestrate multiple runs.
With this separation, it's easy to use Hydra's sweeper to do hyperparameters search, or launcher to run experiments on SLURM cluster or cloud.
To provide path into program, it's best to provide an absolute path for both local or cloud storage (start with ~, /, s3://).
That way you don't have litter your code with hydra.utils.get_original_cwd() to convert relative path, and therefore retaining the flexibility to use your module outside of hydra-managed entry points.
Use hydra to created a hierarchical structure for experiments output based on configurations of each run, by setting the configs/defaults.yaml with
dir: outputs/${data.name}/${model.name}/${experiment}/${now:%Y-%m-%d_%H%M%S}
${data.name}/${model.name}will be dynamically determined from config object. They are preferably nested by the order of least frequently changed.${experiment}is a string briefly describe the purpose of the experiment${now:%Y-%m-%d_%H%M%S}will insert the time of run, serves as a unique identifier for runs differ only in minor hyperparameters such as learning rate.
Example output:outputs/mnist/classifier/baseline/2021-03-10-141516.
Click to expand/collapse
- Drop into a debugger anywhere in your code with a single line
import pdb; pdb.set_trace(). - Use
ipdbor pudb for nicer debugging experience, for exampleimport pudb; pudb.set_trace() - Or just use
breakpoint()for Python 3.7 or above. SetPYTHONBREAKPOINTenvironment variable to makebreakpoint()useipdborpudb, for examplePYTHONBREAKPOINT=pudb.set_trace. - Post mortem debugging by running script with
ipython --pdb. It opens a debugger and drop you right into when and where an Exception is raised.
$ ipython --pdb main.py -- model=autoencoderThis is super helpful to inspect the variables values when it fails, without having to put a breakpoint and then run the script again, which can takes a long time to start for deep learning model.
- Use
fast_dev_runof PytorchLightning, and checkout the entire debugging tutorial.
It's 2021 already, don't squint at your 4K HDR Quantum dot monitor to find a line from the black & white log.
pip install hydra-colorlog and edit defaults.yaml to colorize your log file:
defaults:
- override hydra/job_logging: colorlog
- override hydra/hydra_logging: colorlogThis will colorize any python logger you created anywhere with:
import logging
logger = logging.getLogger(__name__)
logger.info("My log")Alternative: loguru, coloredlogs.
Zsh-autoenv will auto source the content of .autoenv.zsh when you cd into a folder contains that file.
Say goodbye to activate conda or export a bunch of variables for every new terminal:
conda activate project
HYDRA_FULL_ERROR=1
PYTHON_BREAKPOINT=pudb.set_traceAlternative: https://github.com/direnv/direnv, https://github.com/cxreg/smartcd, https://github.com/kennethreitz/autoenv
- Pre-commit hook for python
black,isort. - Experiments
- Configure trainer's callbacks from configs as well.
- Structured Configs
- Hydra Torch and Hydra Lightning
- Keepsake version control
- (Maybe) Unit test (only where it makes sense).
Contrastive Self-supervised Transformers for Disentangled Representation Learning with Inductive Biases is All you need, and where to find them.
![]()
Code for paper paper.
python main.py@article{YourName,
title={Your Title},
author={Your team},
journal={Location},
year={Year}
}