
-
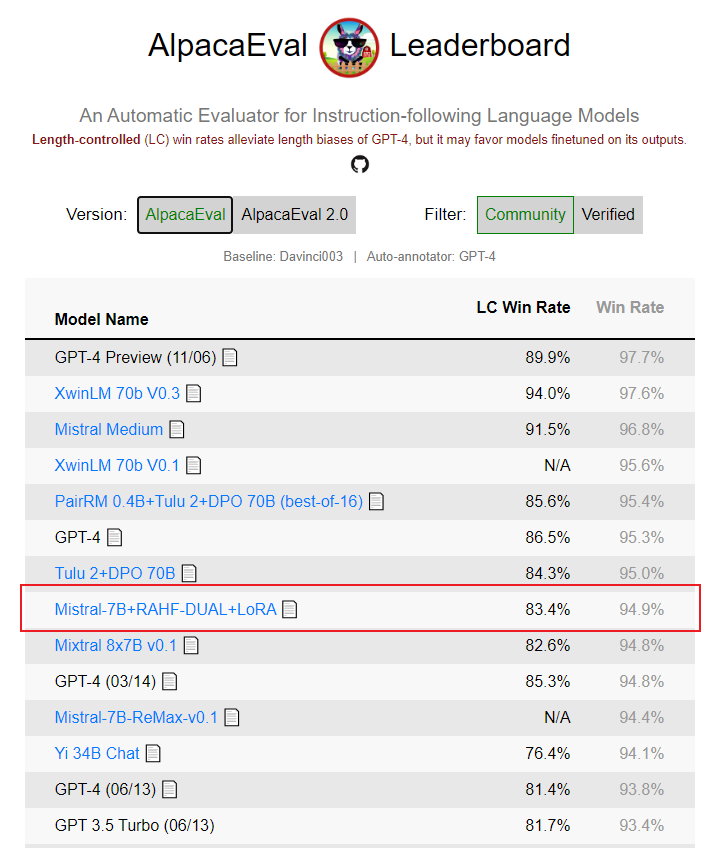
We used RAHF to align the Mistral-7B model and uploaded the evaluation results on AlpacaEval to the AlpacaEval Leaderboard. We achieved the best results among all 7B models currently on the leaderboard.

This repo includes a reference implementation of the RAHF for training language models from preference data, as described in the paperAligning Large Language Models with Human Preferences through Representation Engineering
The RAHF pipeline has three stages:
- Step 0: Using the HH-RLHF dataset, perform Supervised Fine-Tuning (SFT) to enable the model with instruction following and conversational abilities.
- Step 1: Fine-tune the model using the preference dataset Ultrafeedback, instructing the model to understand human preferences.
- Step 2: Collecting activity patterns and constructing a model with LoRA to fit these patterns.
The files in this repo are:
code/step0/data_process.py:Split the dataset into PPO, RM, and test sets. For reproducibility, we have uploaded the split datasets used in our experiments to thedatafolder.code/step1/DUAL_step1.py:Perform SFT on the model using the preference dataset. This part corresponds to the code implementation of part 3.1.2 in our paper.code/step1/SCIT_step1.py:Perform Hindsight on the model using the preference dataset. This part corresponds to the code implementation of part 3.1.1 in our paper.cde/step2/RAHF.py: This part corresponds to the code implementation of part 3.1.3 in our paper.
pip install -r requirements.txtStep0: Using the HH-RLHF dataset, perform Supervised Fine-Tuning (SFT)
cd code
bash bash/SFT-step0.shfor SCIT
cd code
bash bash/SCIT-step1.sh
for DUAL
cd code
bash bash/DUAL-step1.sh
for SCIT
cd code
bash bash/SCIT-step2.sh
for DUAL
cd code
bash bash/DUAL-step2.sh
for open llm Evaluation, we use lm-evaluation-harness.
for Alpaca-Eval, please see alpaca_eval.
for MT-Bench, please see FastChat.