This paper has been accepted by SIGIR 2021 as a full paper, the code is based on PyTorch, and the paper is here.
-
probabilistic graphical model
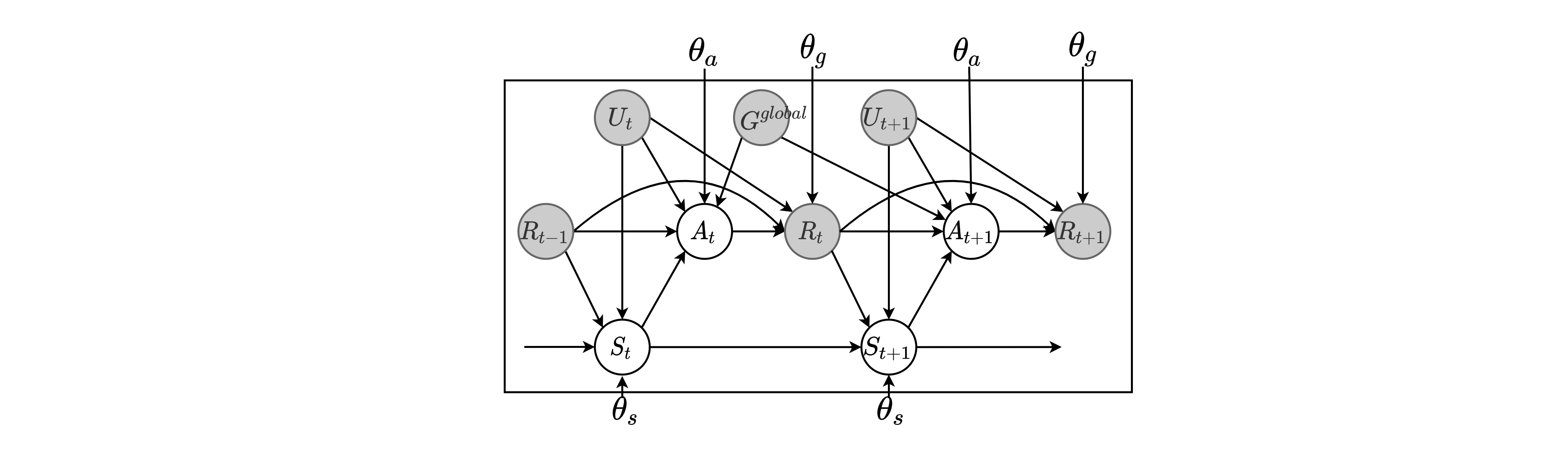
-
model overview


You can access the dataset via the following two links:
- Baidu Link: https://pan.baidu.com/s/1uEZhLC4gxq7Fn1u8VrGgPw Password: dmpm
- Google Link: https://drive.google.com/drive/folders/1i-qiwVgOHS9Cs_7YSNdUCWwviP2HOgqI?usp=sharing
- pytorch 1.4.0
- tqdm 4.31.1
- numpy 1.16.2
- pandas 0.24.0
- logging 0.5.1.2
- argparse 1.1
- json 2.0.9
- nlgeval
- The data should be loaded with several processes in parallel, please make sure your CPU with over 4 cores.
- We conduct our experiments on RTX 2080ti(11GB) and Titan RTX(24GB), please make sure your GPU with over 10 GB of memory.
- train
python main.py --task [kamed,meddialog,meddg] --super_rate 0.5 --model vrbot --train_batch_size 16 --test_batch_size 32 --device 0 --worker_num 5- test
python main.py --task [kamed,meddialog,meddg] --test --model vrbot --test_batch_size 32 --device 0 --ckpt ckpt_filename --worker_num 5- evaluation (compute the metrics and t-test):
python eval_main.py --eval_filename "your_output_filename" --vocab_filename "your_vocab_filename" --alias2scientific_filename "your_alias_filename"python eval_main.py --eval_filename "your_output_filename" --eval_filename2 "your_second_output_filename" --vocab_filename "your_vocab_filename" --alias2scientific_filename "your_alias_filename"please download the word embedding via link: https://pan.baidu.com/s/1A-EzSJUdSu6g8Zy8BCm-Cw password: qw9i .
If you use any code or data in this repo in your work, please cite our paper.
@inproceedings{li2021semi,
title={Semi-Supervised Variational Reasoning for Medical Dialogue Generation},
author={Li, Dongdong and Ren, Zhaochun and Ren, Pengjie and Chen, Zhumin and Fan, Miao and Ma, Jun and de Rijke, Maarten},
year = {2021},
booktitle = {SIGIR},
pages = {},
}