Apollo GraphQL 在 webapp 中应用的思考
kuitos opened this issue · comments

Apollo GraphQL 在 webapp 中应用的思考
简介
熟悉 Apollo GraphQL 的同学可直接跳过这一章,从 实践 一章看起。
GraphQL 作为 FaceBook 2015年推出的 API 定义/查询 语言,在历经了两年的发展之后,社区已相对发达和完善。对于 GraphQL 的一些基础概念,本文不再一一赘述,目前社区相关的文章已经很多,有兴趣的同学可以去 google,或者直接看GraphQL 官方教程 Apollo GraphQL Server 官方文档。
而 Apollo GraphQL 作为目前社区最流行的 GraphQL 解决方案提供商,提供了从 client 到 server 的一整套完整的工具链。在这里我也准备以 Apollo 为例,通过一步步搭建 Apollo GraphQL Server 的方式,来给大家展示 GraphQL 的特点,以及我的一些思考(主要是我的思考🤪)。
setup
创建基于 express 的 GraphQL server
// server.js
import express from 'express';
import { graphiqlExpress, graphqlExpress } from 'apollo-server-express';
import schema from './models';
const PORT = 8080;
const app = express();
...
app.use('/graphql', graphqlExpress({ schema }));
app.use('/graphiql', graphiqlExpress({
endpointURL: '/graphql'
}));
if (process.env.NODE_ENV === 'development') {
glob(path.resolve(__dirname, './mock/**/*.js'), {}, (er, modules) => modules.forEach(module => require(module).default(app)));
}
app.listen(PORT, () => console.log(`> Listening at port ${PORT}`));执行 node server.js,这样我们就能启动一个 GraphQL server 了。
注意我们这里使用了 apollo-server-express 提供的 graphiqlExpress 插件,graphiql 是一个用于浏览器端调试 graphql 接口的 GUI 工具。服务启动后,我们在浏览器打开 http://localhost:8080/graphiql就可以看到这样一个页面

定义 API schema
我们在 server.js 中定义了这样一个 endpoint : app.use('/graphql', graphqlExpress({ schema }));
这里传入的 schema 是什么呢?它大概长这样:
import { makeExecutableSchema } from 'graphql-tools';
// The GraphQL schema in string form
const typeDefs = `
type User {
id: ID!
name: String
age: Int
}
type Query { user(id: ID!): User }
schema { query: Query }
`;
// The resolvers
const resolvers = {
Query: { user({id}) { return http.get(`/users/${id}`)}}
};
// Put together a schema
const schema = makeExecutableSchema({
typeDefs,
resolvers
});
app.use('/graphql', graphqlExpress({ schema }));这里的关键是用了 graphql-tools 这个库提供的 makeExecutableSchema 组合了 schema 定义和对应的 resolver。resolver 是 Apollo GraphQL 工具链中提出的一个概念,什么用呢?就是在我们客户端请求过来的 schema 中的 field 如果在 GraphQL Server 中有对应的 resolver,那么在返回数据时候,这些 field 就由对应的 resolver 的执行结果填充(支持返回 promise)。
客户端请求
这里借助 graphiql 面板的功能来发送请求:
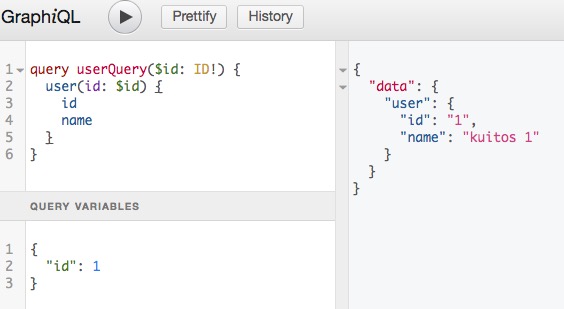
看一下 http request payload 信息:

响应体:

也就是说,无论你是用你熟悉的 http lib 还是社区的 apollo client,只要按照 GraphQL Server 要求的既定格式发请求就 ok 了。
这里我们使用了 GraphQL 中的 variable 语法,事实上在这种需要传参的动态查询场景下,我们应该总是使用这种方式发送请求:即一个 static query + variable 的方式,而不是在运行时动态的生成 query string。这也是官方建议的最佳实践。
更复杂的嵌套查询场景
假设我们有这样一个场景,即我们需要取到 User Entity 下的 nick 字段,而 nick 数据并不来自于 user 接口,而是需要根据 userId 调用另一个接口取得。这时候我们服务端的代码需要这样写。
// schema
type User {
id: ID!
name: String
age: Int
nick: String
}
// resolver
User: {
nick({ id }) {
return getUserNick(id);
}
}resolver 的参数列表中包含了当前所在 Entity 已有的数据,所以这里可以直接在函数的入参里取到已查询出来的 userId。
看下效果:

服务端的请求:

可以看到,这里多出了查询 nick 的请求。也就是说,GraphQL Server 只有在客户端提交了包含相应字段的 query 时,才会真正去发送相应的请求。更多 resolver 说明可以看这里。
其他
在真实的生产环境中,我们通常会有更多更复杂的场景,比如接口的权限认证、分页、缓存、批量提交、schema 模块化等需求,好在社区都有相对应的一些解决方案,这不是本文的重点所以不在这里一一介绍了,有兴趣的可以去看下我之前写的 graphql-server-startkit,或者官方的 demo。
实践
如果你真实的使用过 Apollo GraphQL,你会经历如下过程:
-
定义一个 schema 用于描述查询入口
// schema.graphql type User { id: ID! name: String nick: String age: Int gender: String } type Query { user(id: ID!): User } schema { query: Query } -
编写 resolver 解析对应类型
const resolvers = { Query: { user(root, { id }) { return getUser(id); } }, User: { nick({ id }) { return getUserNick(id); } } };
-
编写客户端请求代码调用 GraphQL 接口,通常我们会封装一个 get 方法
function getUser(id) { // 以 axios 为例 return axios.post('/graphql', { query: 'query userQuery($id: ID!) {↵ user(id: $id) {↵ id↵ name↵ nick↵ }↵}', operationName: "userQuery", variables: {id}}); }
如果你的项目中加入了静态类型系统,那么你的代码可能就会变成这样:
// 以 ts 为例 interface User { id: number name: string nick: string age: number gender: string } function getUser(id: number): User { return axios.post('/graphql', { query: 'query userQuery($id: ID!) {↵ user(id: $id) {↵ id↵ name↵ nick↵ }↵}', operationName: "userQuery", variables: {id}}); }
写到这里你可能已经发现,不仅是 entity 类型定义,就连接口的封装,我们在服务端和客户端都重复了一遍(虽然一个用的 GraphQL Type Language 一个用的 TS)… 这还是最简单的场景,如果业务模型复杂起来,你在两端需要重复的代码会更多(比如类型的嵌套定义和 resolve)。这时候你可能会想起 DRY 原则,然后开始思考有没**有什么方式可以使得类型及接口定义能两端复用,或者根据一端的定义自动生成另一端的代码?**甚至你开始怀疑,到底有没有引入 GraphQL 的必要?
思考
GraphQL 作为一个标准化并自带类型系统的 API Layer,其工程价值我也不再过多广告了。只是在实践过程中,既然我们无法完全避免服务端与客户端的实体与接口定义重复(使用 apollo-codegen 可以避免一部分),而且对于大部分小团队而言,运维一个 productive nodejs system 实际上都是力有未逮。**那么我们是不是可以考虑在纯客户端构建一个类 GraphQL 的 API Layer 呢?**这样既可以有效的避免编码重复,也能大大的降低对团队的要求,可操作的空间也比增加一个 nodejs 中间层大得多。
我们可以回忆一下,通常对于一个前端而言,促使我们需要一个 API Layer 的原因是什么:
- 后端接口设计不够 restful,命名垃圾,用的时候看见那个*一样的 url 就难受。
- 后端同学只愿意写 microservice,提供聚合服务的 web api 被认为没有技术含量,不愿意写。你需要一个数据,他告诉你需要调 a、b、c 三个接口,然后根据 id 组装合并。
- 接口返回的数据格式各种嵌套及不合理,不是前端想要的结构。
- 接口返回的数据字段命名随意或者风格不统一,我有强迫症用这种接口会发疯。
- 后端返回的 数据格式/字段名 一旦变了,前端视图绑定部分的代码需要修改。
通常情况下,碰到这些问题,你可能去跟后端同学据理力争,要求他们提供调用体验更良好设计更优雅的接口。没错这很好,毕竟为了追求完美去跟各种人撕(跟后端撕、跟产品撕、跟UI撕)是一个前端工程师基本的职业素养。但是如果你每天都被撕逼弄得心力交瘁,甚至是你根本找不到撕的对象(比如数据来源接口来着几个不同部门,甚至是一些祖传的没人敢动的接口),这些时候大概就是你迫切希望有一个 API Layer 的时候了。
如何在客户端实现一个 API Layer
其实很简单,你只需要在客户端把 Apollo Server 中要写的 resolvers 写一遍,然后配上一些性能提升手段(如缓存等),你的 API Layer 就完成了。
比如我们在src下新建一个 loaders/apis 目录,所有的数据拉取接口都放在这里。比如这样:
// UserLoader.ts
export interface User {
id: number
name: string
nick: string
}
export default class UserLoader {
async getUser(id: number): User {
const base = await Promise.all([http.get('//xxx.com/users/${id}'), this.getUserNick(id)]);
const user = base.reduce((acc, info) => ({...acc, ...info}), {});
return user;
}
getUserNick(id: number): string {
return http.get(`//xxx.com/nicks/${id}`);
}
}然后在你业务需要的地方注入相应 loader 调用接口即可,如:
import { inject } from 'mmlpx';
import UserLoader from './UserLoader';
// Controller.ts
export default class Controller {
@inject(UserLoader)
userLoader = null;
async doSomething() {
// ...
const user = await this.userLoader.getUser(this.id);
// ...
}
}如果你不喜欢依赖注入的方式,loaders/apis 层直接 export function getUser 也可以。
如果你碰到了上面描述的第 3、4 、5 三种问题,你可能还需要在这一层做一下数据格式化。比如这样:
async getUser(id: number): User {
const base = await Promise.all([http.get('//xxx.com/users/${id}'), this.getUserNick(id)]);
const user = base.reduce((acc, info) => ({...acc, ...info}), {});
return {
id: user.id,
name: user.user_name, // 重命名字段
nick: user.nick.userNick // 剔除原始数据中无意义的层次结构
};
}经过这一层的数据处理,我们就能确保我们的应用运行在前端自己定义的数据模型之下。这样之后后端接口不论是数据结构还是字段名的变更,我们只需要在这一层做简单调整即可,而不会影响到我们上层的业务及视图。相应的,我们的业务层逻辑不再会直接对接接口 url,而是将其隐藏在 API Layer 下,这样不仅能提升业务代码的可读性,也能做到眼不见为净。。。
总结
熟悉 GraphQL 的同学可能会很快意识到,我这不过是在客户端做了一个简单的 API 封装嘛,并不能解决在 GraphQL 出现之前的 lots of roundtrips 及 overfetching 问题。但事实上是 roundtrip 的问题我们可以通过客户端缓存来缓解(如果你用的是 axios 你可能需要 axios-extensions ),而且 roundtrip 的问题其实本质上我们不过是将客户端的 http 开销转移到服务端了而已。在客户端与服务端均不考虑缓存的情况,客户端反而会少一个请求。。。overfetching 问题则取决于 backend service 的粒度,如果 endpoint 不够 micro,即便是 GraphQL,也会出现接口数据冗余问题,毕竟 GraphQL 不生产数据,它只是数据的搬运工。。。而如果 endpoint 粒度足够小,那么我在客户端 API 层多开几个接口(换成 Apollo 也要多写几个 resolver),一样可以按需取数据。服务端 API Layer 只有一个不可替代的优势就是,如果我们的数据源接口是不支持跨域或者仅内网可见的,那么就只能在服务端开个口子做代理了。另外一个优势就是,GraphQL Server 的 http 开销是可控的,毕竟机器是我们自己控制,而客户端的环境则不可控(受限于终端设备及网络环境,比如低版本浏览器或者低速网络,均会导致 http 开销的性能权重增大)。
可能有同学会说,服务端 API Layer 部署一次任何系统都可以共享其服务,而客户端 API Layer 的作用域只在某一项目。其实,如果我们把某一项目需要共享的 API Layer 打成一个 npm 包发布出去,不也能达到同样的效果吗,很多平台的 js sdk 不都是这个思路么(这里只讨论 web 开发范畴)。
在我看来,不论你是否会搭建一个服务端的 API Layer,**我们其实都需要有一个客户端 API Layer 从数据源头来保证客户端数据的模型统一及一致性,从而有足够的能力应对接口的变迁。**如果你考虑的再远一点,在 API Layer 服务的业务模型层,我们同样需要有一套独立的 Service/Model Layer 来应对视图框架的变迁。这个暂且按下不表,后面会再写篇文字来详细说一下我的思路。
事实上,对于大部分团队而言,客户端 API Layer 已经够用了,增加一层 GraphQL 并不是那么必要。而且如果没有很好的支持将客户端接口转换成 GraphQL Schema 和 resolver 的工具时,我们并不能很愉快的 coding,毕竟两端重复的工作还是有点多。

前排留名

看了几次GraphQL,还是接受不了。我还是更喜欢加可控的中间层(为客户端准备数据,可以升级降级方案,数据拼合都好搞),这样比不会影响服务化的基础服务。
@kuitos 就是和您的api layer类似的的意思。就是再搭建一个api server,用于构建客户端需要的数据,这个server的数据源是真正的后端service。
@hstarorg 如果是 server 端的话实际上我会倾向于 apollo GraphQL,相比于自建 nodejs api server,ag 的优势还是蛮多的。
GraphQL 目前对我而言唯二的障碍是:
- 即便是 nodejs 已经发展这么多年,但是否大部分前端团队都有能力做好一个 nodejs server 的运维我依然持保留意见(包括各种监控、日志等)
- 目前我从实践中不好的体验是,GraphQL Server 端跟客户端在编码中存在大量重复性工作,目前还没发现社区有工具能改善这个问题
所以我现在的方案是在客户端做 api layer ...

小板凳
@kuitos 客户端api layer没有解决数据拼接,传输性能等问题,api的版本控制,隔离在客户端也做不到,所以我更倾向于服务端layer。至于GraphQL,从查询的层面不错,不过我暂时还接收不了与传统开发模式之间的那些差异。
但事实上是 roundtrip 的问题我们可以通过客户端缓存来缓解(如果你用的是 axios 你可能需要 axios-extensions ),而且 roundtrip 的问题其实本质上我们不过是将客户端的 http 开销转移到服务端了而已。在客户端与服务端均不考虑缓存的情况,客户端反而会少一个请求。。。overfetching 问题则取决于 backend service 的粒度,如果 endpoint 不够 micro,即便是 GraphQL,也会出现接口数据冗余问题,毕竟 GraphQL 不生产数据,它只是数据的搬运工。。。而如果 endpoint 粒度足够小,那么我在客户端 API 层多开几个接口(换成 Apollo 也要多写几个 resolver),一样可以按需取数据。服务端 API Layer 只有一个不可替代的优势就是,如果我们的数据源接口是不支持跨域或者仅内网可见的,那么就只能在服务端开个口子做代理了。另外一个优势就是,GraphQL Server 的 http 开销是可控的,毕竟机器是我们自己控制,而客户端的环境则不可控(受限于终端设备及网络环境,比如低版本浏览器或者低速网络,均会导致 http 开销的性能权重增大)。
@hstarorg 数据拼接在服务端 api layer 怎么做客户端也是一样的逻辑,比如
// server
async function getUser() {
const [a, b] = await Promise.all([http.get('/a'), http.get('b')]);
return [...a, ...b];
}
// client
async function getUser() {
const [a, b] = await Promise.all([ajax.get('/a'), ajax.get('b')]);
return [...a, ...b];
}所以在我来看性能问题无非就是客户端 XmlHttpRequest 跟服务端 http 模块谁的开销更大...
版本控制我认为通过客户端 api layer 包(package.json)的 version 号就能解决...
隔离的话如我文中所说,是客户端的缺陷之一。
GraphQL 从我角度来看其实就是传统的 API Layer 加上了 DSL,同时提供各种强大机能解决前档开发的常见痛点。如果我们的中间层的定位就是各种后端接口的 组装/调用 层,而没有复杂的自有业务逻辑,我会觉得 GraphQL 还是一个不错的选择。
@kuitos 数据拼接前后写法上是差不多的,但是可控性就有差异了。如果有服务端中间层,可以做缓存控制,数据简化,请求也会更少,从我这边的实践来看,性能是会相对高些的(服务端连接复用,内网,也会减少下发到客户端的数据量)。
版本控制问题,前后的解决方案到是差不多,无非就是公共层,加版本前缀(后缀)的方式。
GraphQL,我还没有深刻理解,暂时的情况是,喜欢不起来。可能是太懒,不愿意接受新玩意。

您的思考很到位,下面是我的粗浅理解:
如果是 server 端的话实际上我会倾向于 apollo GraphQL,相比于自建 nodejs api server,ag 的优势还是蛮多的。
GraphQL 目前对我而言唯二的障碍是:
- 即便是 nodejs 已经发展这么多年,但是否大部分前端团队都有能力做好一个 nodejs server 的运维我依然持保留意见(包括各种监控、日志等)
- 目前我从实践中不好的体验是,GraphQL Server 端跟客户端在编码中存在大量重复性工作,目前还没发现社区有工具能改善这个问题
所以我现在的方案是在客户端做 api layer ...
即便是 nodejs 已经发展这么多年,但是否大部分前端团队都有能力做好一个 nodejs server 的运维我依然持保留意见(包括各种监控、日志等)
这个障碍确实是目前大多数前端团队面临的巨大挑战,不是每一个团队都有能力自己解决,不过目前可以利用 alinode: https://alinode.aliyun.com 去解决一部分问题,当然解决问题肯定是需要付出成本的。
目前我从实践中不好的体验是,GraphQL Server 端跟客户端在编码中存在大量重复性工作,目前还没发现社区有工具能改善这个问题
我对 GraphQL Server 并没有深入的了解,更没有实践过;不过从您的思考中明白了一些问题。
但是 客户端做 api layer 则是强耦合的,职责不够清晰,向您说的一样
写到这里你可能已经发现,不仅是 entity 类型定义,就连接口的封装,我们在服务端和客户端都重复了一遍(虽然一个用的 GraphQL Type Language 一个用的 TS)… 这还是最简单的场景,如果业务模型复杂起来,你在两端需要重复的代码会更多(比如类型的嵌套定义和 resolve)
为了解决这个问题,我的想法是可以尝试将 entity 类型定义,接口的封装 的封装成独立的 JS SDK; 用 npm 来管理,这样它不会和项目耦合,会更加灵活。
对于做 客户端做 api layer 我觉得并不是解决问题的一个好方案。
