(한) 개체명 인식, (영) named entitiy recognition,(일) 固有表現抽出 (중) 命名实体识别
문맥을 파악해서 인명, 기관명, 지명 등과 같은 문장 또는 문서에서 특정한 의미를 가지고 있는 단어 또는 어구를 인식하는 과정을 의미함
-
질의 응답 시스템과 정보 검색 분야에서 유용하게 사용되고 있는 정보 추출의 한 분야
-
문서나 문장 내에서 개체명을 추출하고 추출된 개체명의 종류를 식별하는 작업

-
개체명 인식(Named Entity Recognition, 이하 NER)이라고 하지만 개체명을 인식하는 과제라기 보다는 문자열에서 미리 정의된 개체명 타입에 대해 개체명의 경계를 탐지하고 해당하는 타입으로 분류하는 방식으로 말뭉치를 구축함
-
자연어처리 중 정보 추출 과제의 하나로 주로 상호 참조(coreference resolution), 관계 추출(relation extraction), 사전 추출, 시간 표현 등에서 유용하게 사용됨
- 한국어 개체명 데이터 구축을 위한 지침은 TTA 표준이 일반적으로 사용되고 있으나 2020년과 2021년에 공개된 모두의 말뭉치에서는 신문을 중심으로 하는 문어 외에도 웹 등에서 많이 사용되는 구어체 말뭉치 태깅을 위해 개체명의 타입 수가 늘어나 있는 것을 확인할 수 있다. 펭수와 같은 캐릭터, 강아지 이름 등을 태깅하기 위해 PS_CHARACTER, PS_PET 등이 추가된 것이 이러한 특징을 반영한다.

- 개체명 인식은 정보 추출의 목적으로 개최되던 MUC-6 (Message Understanding Conference)에서 처음으로 정의되고 본격적으로 연구되기 사작해, 사람, 조직, 장소, 시간, 통화, 백분율의 표현들을 텍스트로 인식하기 위해서 진행됨.

-
1995년 MUC-6[the Sixth Message Understanding Conference] (https://cs.nyu.edu/faculty/grishman/muc6.html) 에서 시작되었는데 당시 분류의 기준은 5 가지로 인명(PS), 기관명(OG), 장소(LC), 날짜(DT), 시간(TI) 분류 및 BIO(Begin, in, out) tag 를 붙이는 과제였다. NEtask20에서 참조할 수 있다.
-
이후 CoNLL(2002, 2003) shared task에서 Language-Independent Named Entity Recognition 과제가 이루어졌다.
개체명 인식은 크게 3가지의 방법으로 연구됨
- 규칙 기반
- 정규표현식
- 자연어 특징을 이용한 규칙과 사전 정보사용
- 통계기반의 기계 학습 방법
- Hidden Markov Model
- Maximum Entropy Model
- Conditional Random Fields
- Decision Tree
- 규칙 기반 및 기계학습
- 규칙 기반과 기계학습을 혼합함으로 더 향상된 성능을 보였음
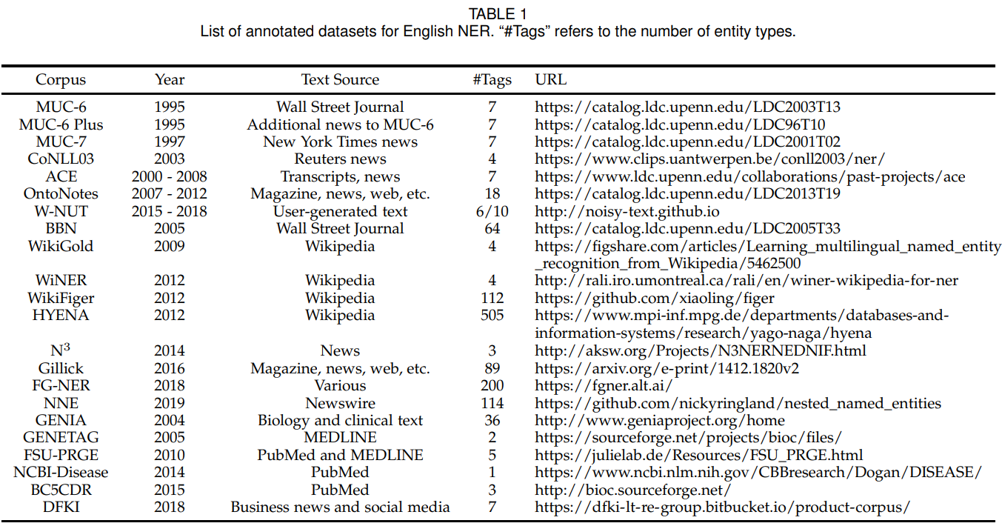
CORPUS
CoNLL-2002 NER corpus
QUICK PEEK

CORPUS
CoNLL-2003 NER corpus : 영어 NER
COUPUS
NUT Named Entity Recognition in Twitter Shared task
TOOLKIT
Stanford Named Entity Recognizer
TOOLKIT
영어의 경우 nltk 패키지를 통해 다음의 4단계를 거치면 입력 문장에서 사람, 조직, 장소 이름을 추출할 수 있다.
- 문장분리 nltk.sent_tokenize
- 어절분리 nltk.word_tokenize
- 형태소 태깅 nltk.pos_tag
- 개체명 인식 nltk.chunk.ne_chunk
- HLCT 2016에서 제공한 데이터 세트 원본의 일부 오류를 수정하고 공개한 말뭉치
- KoreanNERCorpus
QUICK PEEK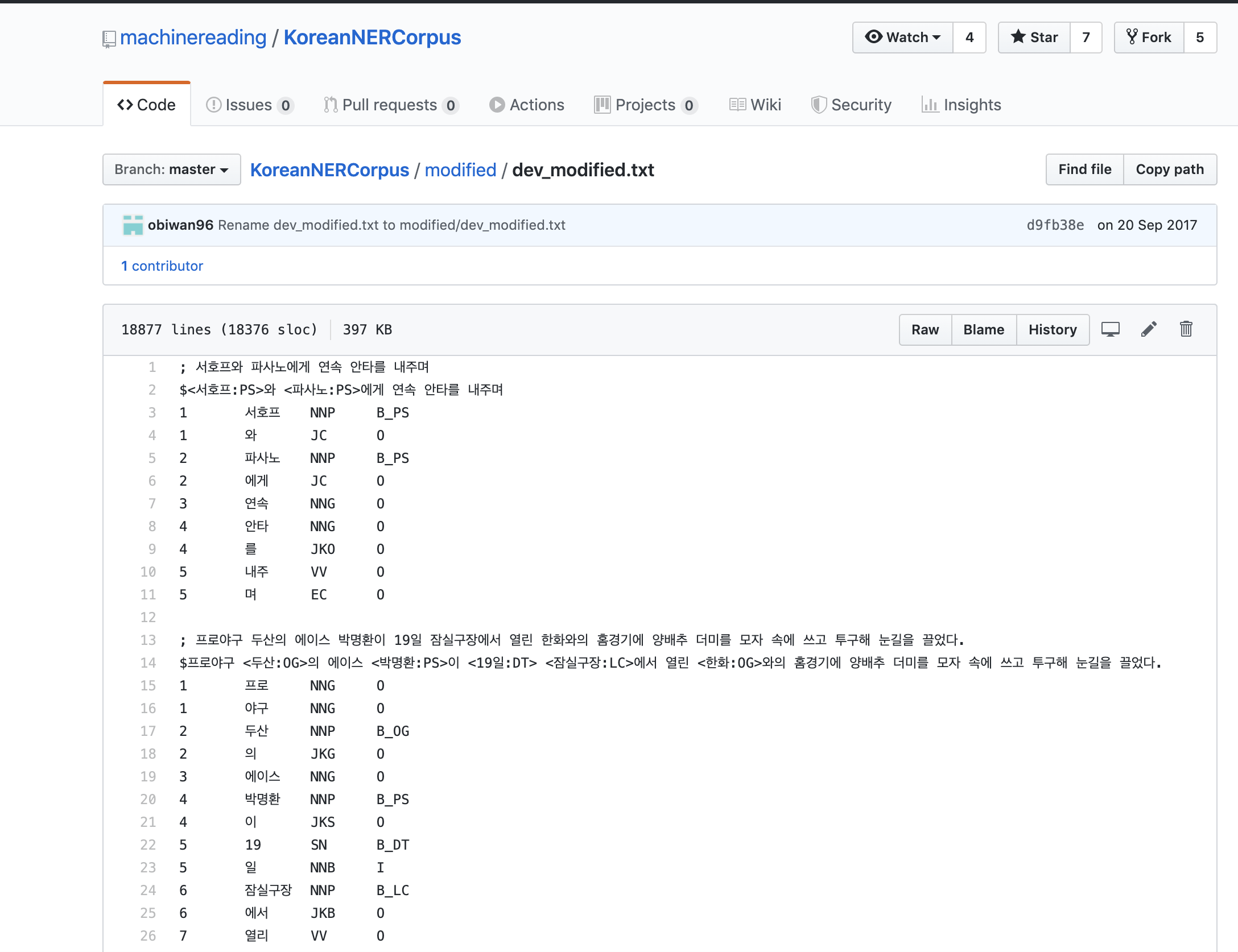

- 한국어 개체명 정의 및 표지 표준화 기술보고서와 이를 기반으로 제작된 개체명 형태소 말뭉치
- mounlp_NER
QUICK PEEK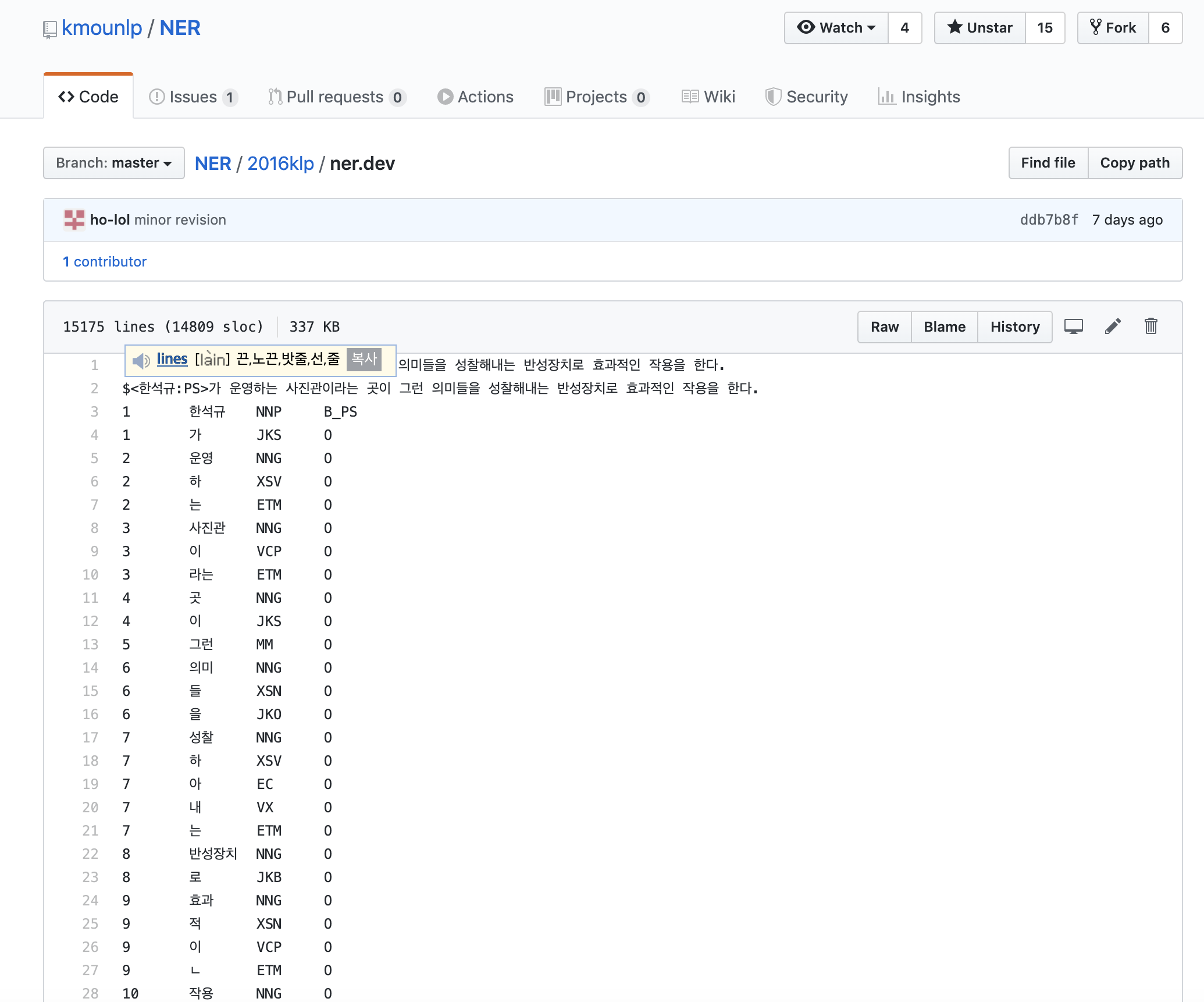

- aihub에서 사용자 의도가 반영된 개체(Entity)를 추출하여 시소러스 및 소상공인, 공공민원 분야를 위해 구축한 데이터
QUICK PEEK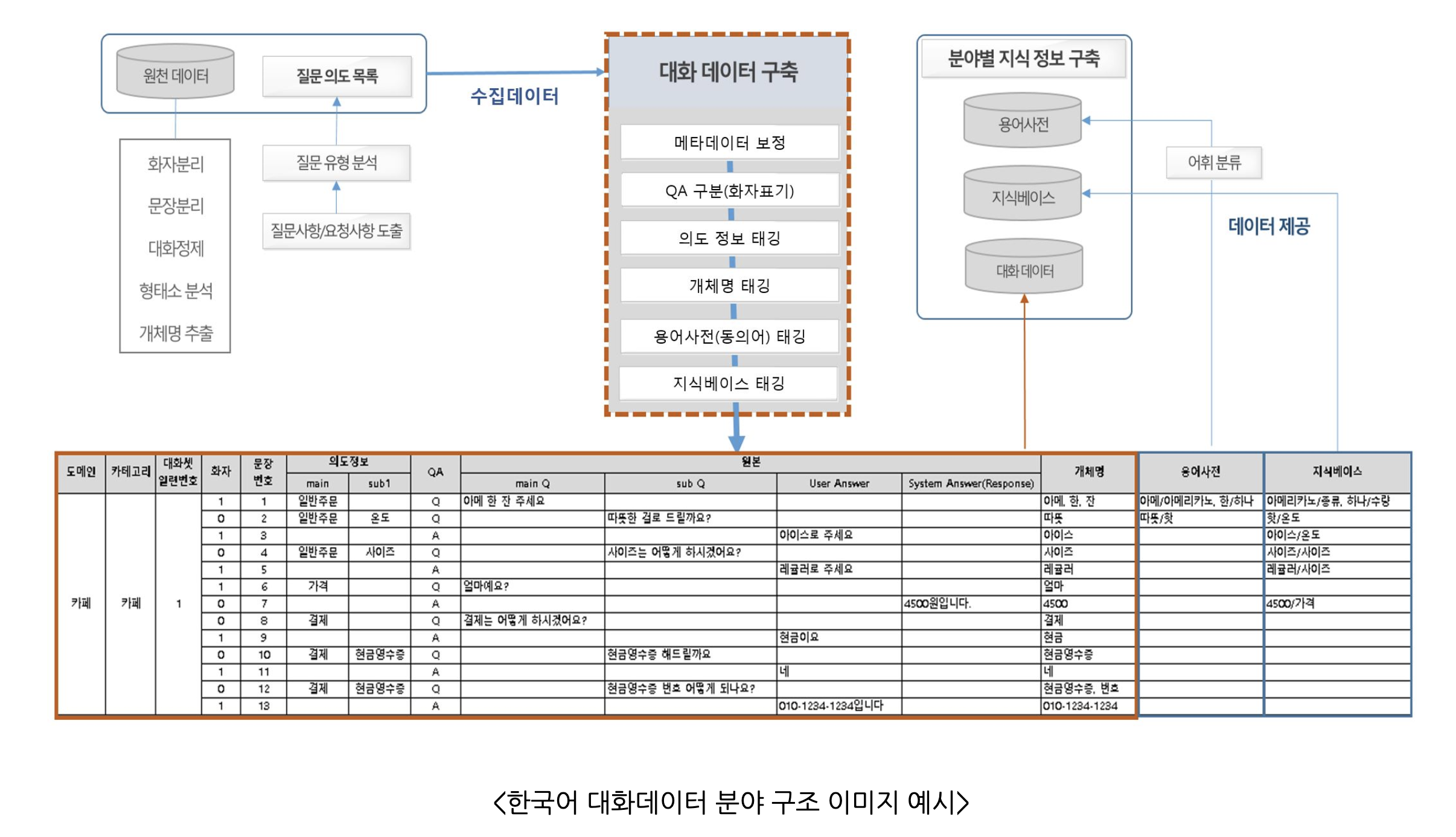

- 포멧이 사용하기 편하고 사용 예시가 분명한 단계로 진행되고 있음
- 개체명 태그의 종류가 다양해지고 다양한 도메인에서도 유연하게 작용할 수 있는 방향을 모색하는 중
- 개체명 인식을 위한 말뭉치 구축이 어려운 이유는 새로운 개체명이 계속 만들어지고 있어서 완성된 사전을 가지기 어렵기 때문이다.
- 같은 단어라도 사용되는 상황에 따라 다른 의미로 해석되는 중의성이 발생할 수 있다.
- 세분류 태깅보다 대분류 태깅이, 개체명의 분류 타입을 규정하는 것보다 경계를 탐지(스팬 설정)하는 것이 더 난이도가 높은 과제로 여겨진다. 가령 <서울 패션 위크:EV_FESTIVAL> 에서 서울은 분리해서 도시로 태깅하지 않고 패션 위크의 하위 이벤트로 판단하여 한꺼번에 태깅한다.
- 도메인을 구분 하는 이유 역시 쉽게 중의성을 해소하기 위해서
-
'여자 친구'의 여름여름해'라는 곡이 있다면 사전적 의미로는 올바른 정보를 추출하기 어려울 수도 있다.
-
이를 대중 가요라는 closed domain에 가수와 곡명으로 분류하여 개체로 태깅해 주면 빠르게 정보에 접근할 수 있을 것이다.
-
또한, 병원의 차트, 법원 녹취록 등은 특정한 목적을 위해 데이터를 별도로 구축하기 때문에 다수의 전문 용어들이 특정한 의미로 사용되게 된다.
- 아스피린과 같이 일반적으로 많이 쓰이는 용어도 있지만, 대체로는 특정한 용어를 개체로 태깅해 주는 것이 데이터 구축시 주요 작업일 것이다.
- 이 때 결과물은 개체명과 범주로 이루어진 사전 또는 태깅된 문서가 된다.
-
 위 그림과 같이 B,I,O 또는 B,I,E,S,O 등의 suffix로 분리된 토큰을 하나로 묶어주는 방법이 고안되어 왔는데, 요즘같이 딥러닝에 사용되는 토크나이저를 활용하면, 단어를 subwords unit으로 나누게 되는데, 이때 단어가 분리되면 토크나이저에 따라 '##' 또는 '_' 형식으로 분리된 두번째 subwords 부터 특수 문자가 붙게 되어서 I, E등의 정보는 필요가 없어짐
위 그림과 같이 B,I,O 또는 B,I,E,S,O 등의 suffix로 분리된 토큰을 하나로 묶어주는 방법이 고안되어 왔는데, 요즘같이 딥러닝에 사용되는 토크나이저를 활용하면, 단어를 subwords unit으로 나누게 되는데, 이때 단어가 분리되면 토크나이저에 따라 '##' 또는 '_' 형식으로 분리된 두번째 subwords 부터 특수 문자가 붙게 되어서 I, E등의 정보는 필요가 없어짐
딥러닝 학습시에도 점수를 평가(evaluate)할때, seqeval_metrics.precision_score(labels, preds, suffix=True)를 사용하게 되는데, 여기서 suffix는 AGE-B나, B-AGE 처럼 개체의 앞또는 뒤에 붙은 유무에 따라서 True/False 지정을 하므로써, 최종 평가 점수의 형태에는 suffix를 반영하지 않음은 아래 결과와 같이 확인이 가능함
하지만 모델의 cross entropy loss 시 I 또는 B에 대한 각각의 출력이 있을것이라 생각이됨
- 이유는 모델 config에서 라벨의 개수를 지정해 주는데 아래 서울시 데이터에 대한 태그는 [AGE],[LOC],[SEX]까지 총 3개의 태그는 B, I의 각 suffix에 의해 6개가 되고 suffix O를 더해 총 7개의 태그로 학습을 진행하기 때문임
#####################################################
# roberta 서울시(seoul-si) 데이터 학습 결과
# ckpt 1200
f1 = 0.9991445680068435
loss = 0.002619927439946457
precision = 0.9988159452703592
recall = 0.9994734070563455
precision recall f1-score support
AGE 0.97 0.99 0.98 231
LOC 1.00 1.00 1.00 5932
SEX 1.00 1.00 1.00 1433
micro avg 1.00 1.00 1.00 7596
macro avg 0.99 1.00 0.99 7596
weighted avg 1.00 1.00 1.00 7596
#####################################################
#####################################################
# KoElectra 119(ner-119) 긴급신고접수 NER 데이터 학습 결과
f1 = 0.7518783854621702
loss = 0.37201588021384346
precision = 0.7110046265697291
recall = 0.7977382276603634
precision recall f1-score support
DAN 1.00 0.83 0.91 6
DIR 0.70 0.76 0.73 3650
LOC 0.79 0.85 0.82 1368
MET 0.82 0.87 0.84 52
NUM 0.66 0.66 0.66 884
ORG 0.77 0.84 0.81 2690
PER 0.77 0.90 0.83 3709
QTY 0.56 0.74 0.64 250
SIT 0.42 0.50 0.46 1532
TIM 0.74 0.88 0.81 2041
micro avg 0.71 0.80 0.75 16182
macro avg 0.72 0.78 0.75 16182
weighted avg 0.71 0.80 0.75 16182
#####################################################
#####################################################
# KoElectra + CRF 119(ner-119) 긴급신고접수 NER 데이터 학습 결과
# ckpt = 2000
f1 = 0.825208846781679
loss = 2.4524980651007757
precision = 0.852579365079365
recall = 0.7995410283446008
precision recall f1-score support
DAN 0.86 0.50 0.63 12
DIR 0.84 0.70 0.77 3605
LOC 0.85 0.87 0.86 1245
MET 0.90 0.95 0.92 64
NUM 0.81 0.69 0.75 906
ORG 0.83 0.85 0.84 2803
PER 0.91 0.89 0.90 3641
QTY 0.74 0.82 0.78 299
SIT 0.73 0.58 0.65 1481
TIM 0.90 0.89 0.90 2067
micro avg 0.85 0.80 0.83 16123
macro avg 0.84 0.78 0.80 16123
weighted avg 0.85 0.80 0.82 16123
#####################################################
서울시 [LOC], [AGE], [SEX] 개체명 인식 모델 추론 결과


- nn.linear -> 7개 클래스에대한 logits -> CrossEntropyLoss -> 학습 -> 모델완성 -> 추론 -> 각 토큰별 입력에 대한 개체별 logits값이 출력 확인
PATH_Klue_roberta = WORK_DIR + '/ner_finetune/model_KlueRoberta_ckpt/roberta-large-seoul-si-lr5e-5/checkpoint-2200'
tokenizer = AutoTokenizer.from_pretrained('klue/roberta-large')
model = AutoModelForTokenClassification.from_pretrained(PATH_Klue_roberta)
ner = NerPipeline(model=model,
tokenizer=tokenizer,
ignore_labels=[],
ignore_special_tokens=True)
text = '서울특별시 강남구 세곡동에 사는 남성 30대만 고용률 알 수 있나요'
inputs = tokenizer(text, return_tensors='pt')
with torch.no_grad():
logits = model(**inputs).logits
print(tokenizer.tokenize(text))
print(tokenizer(text)['input_ids'])
len(tokenizer(text)['input_ids'])
# ['서울특별시', '강남구', '세', '##곡동', '##에', '사', '##는', '남성', '30', '##대', '##만', '고용', '##률', '알', '수', '있', '##나', '##요']
# [0, 30500, 9549, 1269, 13506, 2170, 1233, 2259, 4576, 3740, 2104, 2154, 4571, 2595, 1381, 1295, 1513, 2075, 2182, 2]
# 20
# 로짓의 길이는 20은 시작토큰(1 개) + 문장토큰(text : 18 개) + 문장끝 토큰(1 개)
tokenizer.tokenize(text)
len(str(tokenizer.bos_token_id)) + len(tokenizer.tokenize(text)) + len(str(tokenizer.eos_token_id))
print(len(logits[0]))
print(logits) # 각 토큰별 7개의 태그들에 대한 logits 결과
# 여기서 첫번째 logit은 '서울특별시'에 대한 logit임
predictions = torch.argmax(logits, dim=2)
predictions # argmax로 보았을때 3번 인덱스의 개체가 가장 높은 확률임
# Output exceeds the size limit. Open the full output data in a text editor
# 20
# tensor([[[-1.0638e-01, -2.3128e+00, -9.8020e-01, 2.9688e+00, -3.6005e+00,
# -2.8416e-01, 1.9760e+00],
# [-2.6486e+00, -1.9731e+00, -2.2968e+00, 1.0179e+01, -2.4592e+00,
# -5.8233e-01, -1.3004e+00],
# [-2.0368e+00, -3.3225e+00, -1.7676e+00, -2.2002e+00, -3.3691e+00,
# -6.6381e-01, 9.4754e+00],
# [-2.0584e+00, -3.3303e+00, -1.7535e+00, -2.1740e+00, -3.3938e+00,
# -6.6947e-01, 9.4550e+00],
# [-2.0432e+00, -3.3191e+00, -1.7638e+00, -2.1874e+00, -3.3828e+00,
# -6.6951e-01, 9.4682e+00],
# [ 1.0786e+01, -3.0063e+00, -1.3876e+00, -1.2231e+00, -3.3049e+00,
# -1.5784e+00, -1.2131e+00],
# [ 1.1107e+01, -3.1188e+00, -1.5399e+00, -1.1353e+00, -3.0952e+00,
# -1.6931e+00, -1.5426e+00],
# [ 1.1295e+01, -2.8823e+00, -1.5599e+00, -1.3841e+00, -3.1316e+00,
# -1.3819e+00, -1.4931e+00],
# [-2.1313e+00, 1.1725e+01, -2.2336e+00, -1.6570e+00, -9.9801e-01,
# -9.7593e-01, -2.3810e+00],
# [-2.0532e+00, -1.4382e+00, 8.9992e+00, -1.4494e+00, -1.3441e+00,
# 1.9819e-01, -1.8532e+00],
# [ 3.4401e+00, -2.9372e+00, 1.6621e+00, 1.5478e+00, -4.4614e+00,
# -7.5508e-01, 1.1595e+00],
# [ 4.2103e-01, -2.8174e+00, 7.1775e+00, -3.2325e-01, -3.4736e+00,
# 7.0342e-03, -2.3290e-01],
# ...
# [ 1.1441e+01, -2.6780e+00, -1.7298e+00, -1.5472e+00, -2.8277e+00,
# -1.3263e+00, -1.9278e+00],
# [-2.0267e+00, -3.3193e+00, -1.7481e+00, -2.2055e+00, -3.3961e+00,
# -6.6399e-01, 9.4623e+00]]])
# tensor([[3, 3, 6, 6, 6, 0, 0, 0, 1, 2, 0, 2, 0, 0, 0, 0, 0, 0, 0, 6]])
print(model.config.id2label) # 모델의 라벨 정보
# {0: 'O', 1: 'SEX-B', 2: 'AGE-B', 3: 'LOC-B', 4: 'SEX-I', 5: 'AGE-I', 6: 'LOC-I'}
print(logits[0,0], 'argmax =',np.argmax(logits[0,0])) # 'bos_token' -> 'LOC-B'
print(logits[0,1], 'argmax =',np.argmax(logits[0,1])) # '서울특별시' -> 'LOC-B'
print(logits[0,2], 'argmax =',np.argmax(logits[0,2])) # '강남구' -> 'LOC-I'
print(logits[0,3], 'argmax =',np.argmax(logits[0,3])) # '세' -> 'LOC-I'
print(logits[0,4], 'argmax =',np.argmax(logits[0,4])) # '##곡동' -> 'LOC-I'
# 다음과 같이 토큰별로 예측 되는것을 확인할 수 있음
# tensor([-0.1064, -2.3128, -0.9802, 2.9688, -3.6005, -0.2842, 1.9760]) argmax = tensor(3)
# tensor([-2.6486, -1.9731, -2.2968, 10.1791, -2.4592, -0.5823, -1.3004]) argmax = tensor(3)
# tensor([-2.0368, -3.3225, -1.7676, -2.2002, -3.3691, -0.6638, 9.4754]) argmax = tensor(6)
# tensor([-2.0584, -3.3303, -1.7535, -2.1740, -3.3938, -0.6695, 9.4550]) argmax = tensor(6)
# tensor([-2.0432, -3.3191, -1.7638, -2.1874, -3.3828, -0.6695, 9.4682]) argmax = tensor(6)

- 개체명 인식의 최종 토큰에 대한 개체명의 인식에 있어서 B와 I에 대한 suffix의 정확도를 올리기 위해서는 deep learning모델을 미세조정시 CRF(Conditional Random Field)레이어를 추가해서 특정 토큰의 개체 다음에 오는 개체의 suffix를 보완해줄 수 있는 메커니즘의 추가로 학습 결과가 더 좋게 나올 수 있을 거라는 생각이 듦
- 여기서 실험이 필요함
- CRF 적용 / 미적용 성능비교 필요
- 데이터셋 : 119-ner
- 모델 : ELECTRA / RoBERTa
각 토큰별 개체의 분포를 보기 (예: 오늘 서울시 날씨는 -> 오늘[TIM] 서울[LOC] ##시[LOC] 날씨[WHT] ##는) 이면 [TIM] : 1, [LOC] : 2, [WHT] : 1 이런식으로 각각의 TOKEN CLASSIFICATION이 수행해야할 분포에 대해 살펴보기
- torch.nn.CrossEntropyLoss
- torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=- 100, reduce=None, reduction='mean', label_smoothing=0.0) 학습 파이프라인에서 -100이 들어가는 이유
- 가중치를 각각의 클래스에 할당하므로 불균형한 학습셋을 학습할때 용이하다.
ELECTRA, RoBERTa와 성능비교진행 ELECTRA+CRF, RoBERTa+CRF와 성능비교진행
| Naver NER | 한국해양대학교 | KLP NER | EXOBRAIN | KLUE | 적요 | 긴급신고접수 | 국립국어원 | 한국정보통신협회(TTA) | 생활화학제품 | 아이디어 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 날짜 | 12월31일 | DAT | DAT | DAT | DAT | DAT | DAT | DAT | DT | DT | ||
| 장소 | 서울특별시 성수동 1가 | LOC | LOC | LOC | LOC | LOC | LOC | LOC | LOC | LC | LC | |
| 기관/단체 | 학교명 | ORG | ORG | ORG | ORG | ORG | ORG | ORG | ORG | OG | OG | |
| 사람/이름 | 김진원, 경찰관, 의사 | PER | PER | PER | PER | PER | PER | PER | PER | PS | PS | |
| 시간 | 12시30분 | TIM | TIM | TIM | TIM | TIM | TIM | TIM | TIM | TI | TI | |
| 수량 | 몇 개, 몇 명, 한 사람 | QTY | QTY | QTY | QT | QT | ||||||
| 기타 수량 | NOH | NOH | NUM | |||||||||
| 은행 | 은행명 | BNK | ||||||||||
| 병원 | 병원명 | HOS | ||||||||||
| 병명 | 코로나, 감기 | DIS | ||||||||||
| 회사 | 회사명 | CMP | ||||||||||
| 학문 분야 | FLD | FLD | FD | |||||||||
| 인공물 | 사람이 만든 물건: 책, 무기, 등등 | AFW | AFW | AF | ||||||||
| 문화용어 | CVL | CVL | CV | |||||||||
| 숫자 | NUM | |||||||||||
| 사건 | EVT | EVT | EV | |||||||||
| 119사건 | SIT | |||||||||||
| 동물 | ANM | ANM | AM | |||||||||
| 식물 | PLT | PLT | PT | |||||||||
| 금속/화학물질 | MAT | MAT | MT | MT | ||||||||
| 용어 | TRM | TRM | TM | |||||||||
| 기타고유명사 | POH | |||||||||||
| 기간 | 몇일 동안, 3일동안 | DUR | ||||||||||
| 통화 | 원, 달러 | MNY | ||||||||||
| 비율 | %, 몇퍼 | PNT | ||||||||||
| 음식액체(마실것) | FDL | |||||||||||
| 음식고체(먹을것) | FDS | |||||||||||
| 날씨 | WHT | |||||||||||
| 이론 | THR | TR | ||||||||||
| 브랜드 | BR | |||||||||||
| 모델명 | MN | |||||||||||
| 제품타입 | PT | |||||||||||
| 모양타입 | ST | |||||||||||
| 유입경로 | IR | |||||||||||
| 방향,쪽,방면 | DIR | |||||||||||
| 측정 길이 높이 | 몇 미터 등 | MET | ||||||||||
| 위험물질 | DAN |