Pix2Pix Loss tracking and inspecting the bad results.
iswarup opened this issue · comments

I've been using the Pix2Pix model here for my project recently. A few questions about it if you could help
-
I trained the model for 500+50 epochs with whatever data I had. I didn't get any satisfactory results.
But I've a few more files after sometime now. I continued the training by using the latest .pth files. Still no improvement.
Would you suggest anything particular I'm missing? -
I'm logging all four losses at each epoch. How can I pick the best optimal point where I would get the best results?
(I checked your response to the FID metric PR. I'll be watching out for if you update on - FID evaluation code for pre-trained checkpoints.) Meanwhile I'll try to implement it myself.
-
Would you suggest any ways to inspect why I'm getting bad results?
If more info on the use-case and data used is needed, please reply.

Answered here.

Hello,
I am sorry to hear the quality is not great. It could be because of many reasons, ranging from the size of the dataset to the fundamental limitation of our model.
In case of pix2pix, the precise alignment of the two images is important. It works well when the similar content appears at the same location of the image. For example, in all result below, the underlying content is the same between input and output. The model just "renders" the content into different styles.
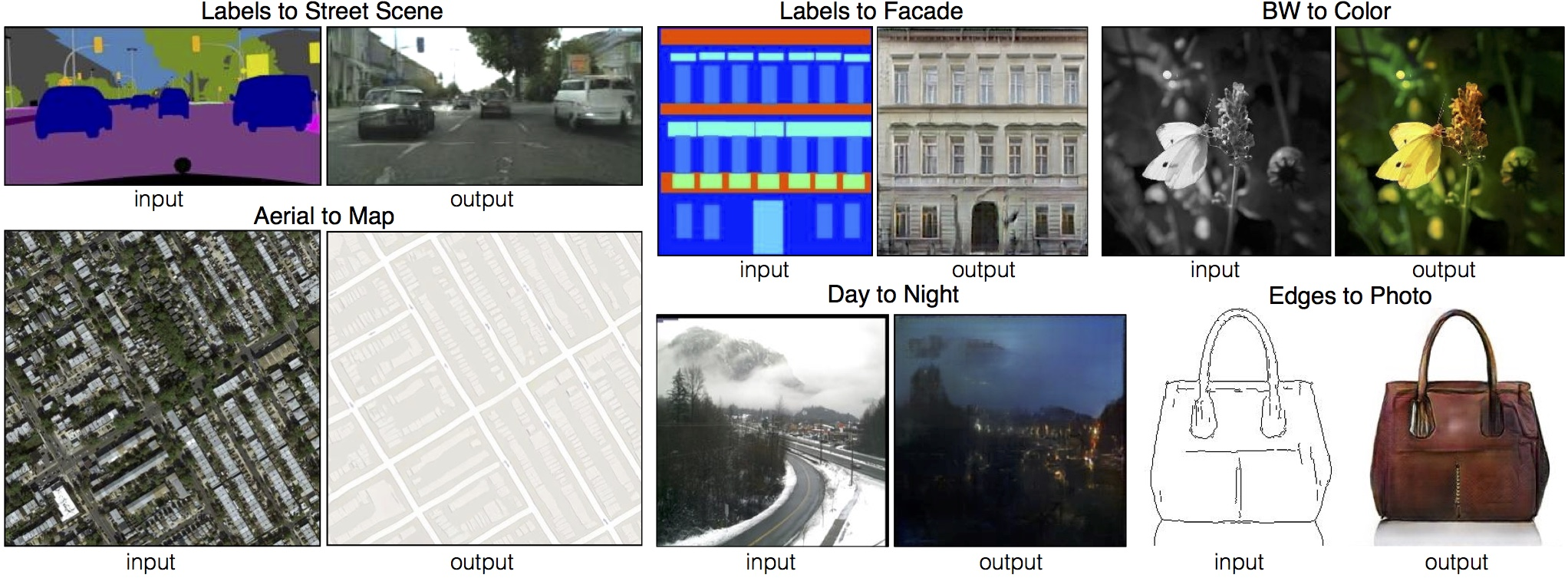
This alignment may not be perfect for some datasets and hurt performance. For example, in case of medical imaging, two images of the same patient won't be aligned well if the patient needs to be scanned in two settings. Therefore, pix2pix actually worked less well than CycleGAN, which was designed to be more lenient to misalignment.
Also, if you have enough images in the dataset, using more latest formulation such as Co-Modulation GAN. It is a more powerful architecture, and will work better if you have many samples in the dataset to prevent overfitting.