optimizing ansi escape sequences
fdncred opened this issue · comments

I was wondering if there was a way with your crate to optimize the ansi escape sequences. Here's an example of what I'm talking about. This is based off of your hello_worlds.rs example.
owo-colors: "\u{1b}[47m\u{1b}[30mHello\u{1b}[0m\u{1b}[0m \u{1b}[42m\u{1b}[35mWorld\u{1b}[0m\u{1b}[0m"
nu-ansi-term: "\u{1b}[47;30mHello\u{1b}[0m \u{1b}[42;35mWorld\u{1b}[0m"
Hello World
owo-colors: "\u{1b}[47m\u{1b}[30mo\u{1b}[0m\u{1b}[0m \u{1b}[42m\u{1b}[35mWo\u{1b}[0m\u{1b}[0m"
nu-ansi-term: "\u{1b}[47;30mo\u{1b}[0m \u{1b}[42;35mWo\u{1b}[0m"
o Wo
Note how there seems to be extra ansi codes. One way of optimizing this would be to parse the codes and combine them where possible. For instance,
E=ESC here - note the E[47E[30m instead of E[47;30m.
Alternatively when you're doing "Hello".fg::<Black>().bg::<White>() you could just write that out as E[47;30m. I'm guessing this may be the easiest solution. Of course, you may have some reason why you're doing it the way you are that I'm unaware of.
This isn't a huge deal with 'hello world' but the extra ansi codes add up over time and will decrease throughput.

This is definitely something I'd like to do, but haven't come up with quite enough solutions for making this real. I think doing this in an efficient/robust enough manner would involve something along the lines of specialization, either actual (non-option, specialization is not a nightly feature worth depending on) some form of emulation (Deref specialization or otherwise)
I'll try and take some time soon to improve this if I can figure something out
Style seems to be more optimized but it still seems to be concatenating ansi sequences.
owo-colors : "\u{1b}[47m\u{1b}[30mHello\u{1b}[0m\u{1b}[0m \u{1b}[42m\u{1b}[35mWorld\u{1b}[0m\u{1b}[0m"
owo style : "\u{1b}[30m\u{1b}[47mHello\u{1b}[0m \u{1b}[35m\u{1b}[42mWorld\u{1b}[0m"
nu-ansi-term : "\u{1b}[47;30mHello\u{1b}[0m \u{1b}[42;35mWorld\u{1b}[0m"
maybe i'm not using your crate right. here's the small test.
let colored_text = format!(
"{hello} {world}",
hello = "Hello"
.fg::<owo_colors::colors::Black>()
.bg::<owo_colors::colors::White>(),
world = "World"
.fg::<owo_colors::colors::Magenta>()
.bg::<owo_colors::colors::Green>(),
);
let colored_text2 = format!(
"{hello} {world}",
hello = nu_ansi_term::Style::new()
.fg(nu_ansi_term::Color::Black)
.on(nu_ansi_term::Color::White)
.paint("Hello"),
world = nu_ansi_term::Style::new()
.fg(nu_ansi_term::Color::Magenta)
.on(nu_ansi_term::Color::Green)
.paint("World"),
);
let colored_text3 = format!(
"{hello} {world}",
hello = "Hello".style(owo_colors::Style::new().black().on_white()),
world = "World".style(owo_colors::Style::new().magenta().on_green()),
);
println!("owo: {:?}", &colored_text);
println!("owo: {}", &colored_text);
println!("nu : {:?}", &colored_text2);
println!("nu : {}", &colored_text2);
println!("sty: {:?}", &colored_text3);
println!("sty: {}", &colored_text3);I'm currently working on using autoref specialization in order to make these optimizations work with the entire API. This will likely be a breaking change (in theory; but for 99% of people not in practice), so I'm going to try and wrap this in with some other changes I wanted to go into the 3.0 release.
If you or anyone else wants these changes before the 3.0 release, please let me know and I can from then on start pushing 3.0 betas to crates.io that you can work off of.
github only just refreshed, so to respond: I noticed this while working on an autoref specialization version, @fdncred you are correct that Style still currently results in concatenation of ANSI sequences. I am currently working on resolving this and will setup some tracking issues for this.
Thanks @jam1garner. I look forward to the next release.
How do you think your changes will affect compile time? I recently was doing more comparison and noticed owo-colors took about 5.9sec vs nu-ansi-term 2.6. I'm hoping these changes make it compile faster.
These changes will likely not affect compile times in either direction. Could you explain your testing methods so I can possibly use them to guide optimizing compile times? Thanks.
For context: just a straight cargo build --release is < 1s for me, but that doesn't include any monomorphization-related compile times. I will admit owo-colors optimizes runtime performance (allocations, speed, binary size, in that order) over compile time, and thus is arguably "overly smart" in its design.
I'm sure there's improvements to be had without compromising on the design and I'd love to find those, but I don't actually know that I have an accurate way to measure this. For example owo-colors generates std::fmt::* implementations that you likely don't use (as, unlike most color libraries, it isn't fmt::Display-only), and I imagine those don't get optimized out until late into compilation. So that's my theory, and if correct would be trivial to solve for a good amount of compile time shaved off.
I would very much like to do everything to help owo-colors fit your usecase and I will admit optimizing compile times is something I need to work on improving at if you have any time to point my in the direction you're using for measurements @fdncred.
Thanks for being so willing to talk about this. It speaks well of you.
My testing isn't very scientific but I just use this command below and compile engine-q here - engine-q it's our next-gen nushell engine. kat recently introduced us to miette which includes owo-colors where I started investigating all this.
cargo +nightly build -Z timings="html,info"
Ok so @fdncred I've pulled engine-q and have been investigating and honestly I'm having trouble recreating your results. There's a bit of variability (anywhere from a slight bit under 1 second to a bit under 3 seconds (actual range: 0.9 to 2.7)) but I can't seem to recreate anything over 3 seconds?
I suppose this could be processor differences (I'm on a Ryzen 9 4900HS, for reference), but a >100% difference seems a bit extreme unless you're on an old/lower end machine. Or possibly it could be highly dependent on core count. I'm not sure.
I'm going to try to pull down compile times best I can, but measuring is hard because there's about as much noise as there is signal due to parallel compilation :/
I'll try doing this work from a slower box to see if I can better recreate your numbers
This is the slowest I've been able to get (on latest nightly):
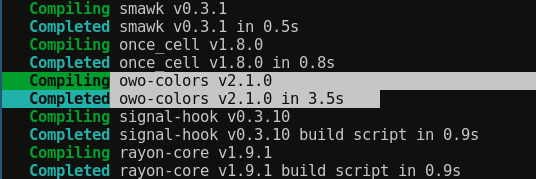
3.5 seconds on digital ocean's cheapest VM, a quite slow single-core machine :<
I don't mean to be rude @fdncred but are your timings coming from some sort of free-tier CI container? Even on a machine that takes 21x as long to compile as my laptop I can't get as slow as your numbers for owo-colors. nu-ansi-term time seems decently similar on this digital ocean VM to what you have, so I'm honestly not sure what's going on.
Also I should've mentioned @fdncred, can you see if (ignoring edit: Style, which I still need to optimize moreStyle has also been optimized) the output off of the master branch is optimized in all the manners you're seeking? I believe I've implemented autoref specialization for both compile-time and runtime colors.
For example:
let test = String::from("red on white");
let test_colored = test.red().on_white();
println!("{}", test_colored);
dbg!(test_colored);this now should work and the above example outputs:
"\x1b[31;47mred on white\x1b0m"
@fdncred sorry for all the requests but if you get a second could you run the following command on engine-q then send the output for the section following "Compiling owo-colors..." ?
Command:
RUSTFLAGS="-Z time-passes" cargo +nightly build -j1
Example of what part of the output I need:
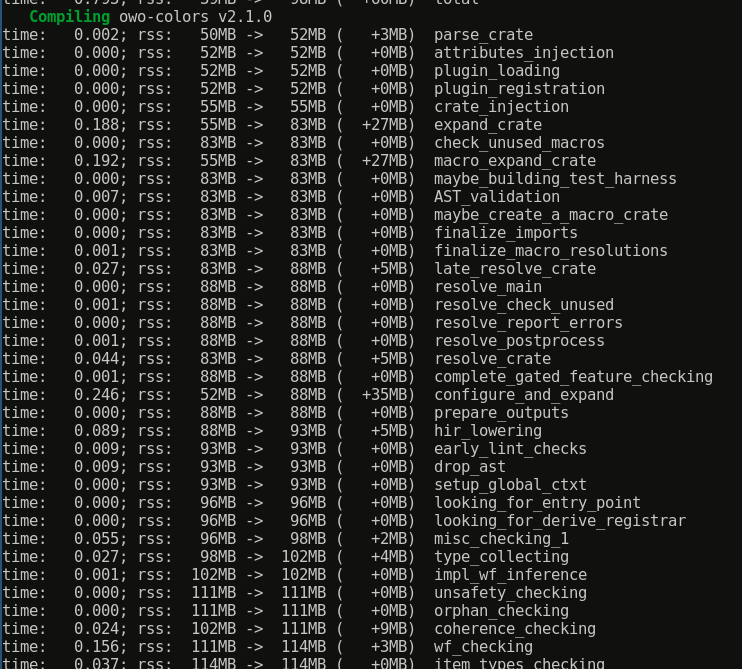
this would help give me a better idea of the breakdown of what is causing such slow compilation on your machine. Thanks.
Also an addendum: -j1 also seems to produce more accurate results when being compared on a per-crate basis. The ordering seems significantly more consistent and while not 100% indicative of real-world performance, something about pipelining here seems to be hurting how owo-colors compares to other crates.
For example: what could I possibly be doing that causes owo-colors, a < 3000 line crate, to have longer compile times that regex, which has over 60k lines and is pretty universally considered a heavy dependency? This didn't add up to me so I've been looking into what could be the cause.
Now if I add -j1 regex floats upwards in the list, while owo-colors sinks well over 10 places. This would heavily imply that owo-colors' compile types aren't actually the issue: it just happens to be located in the tree in the perfect spot to be competing with crates being compiled in parallel. It's a leaf node (has no deps) *and* is high (i.e. low depth) in the dependency graph, meaning it's most likely to be pulled in right when cargo is starting to run out of parallelize-able tasks, which means the time that *the most* crates are hitting LLVM codegen, the most consistently expensive compilation pass (due to the fact rustc ouputs a lot of LLVM bitcode and just lets LLVM clean up and optimize the mess).
I've also gone on to example other libraries and applications I've written in Rust for a variety of tasks, with varying amounts of generics, deps, macros, etc. From what I can tell (2-3 runs per project) there is less variation and more sensible results for -j1.
All this data *really* makes me think owo-colors' compile times are more accurately in the subsecond range, Across 5 runs I observed an average compile time difference of 0.139s with this testing method:
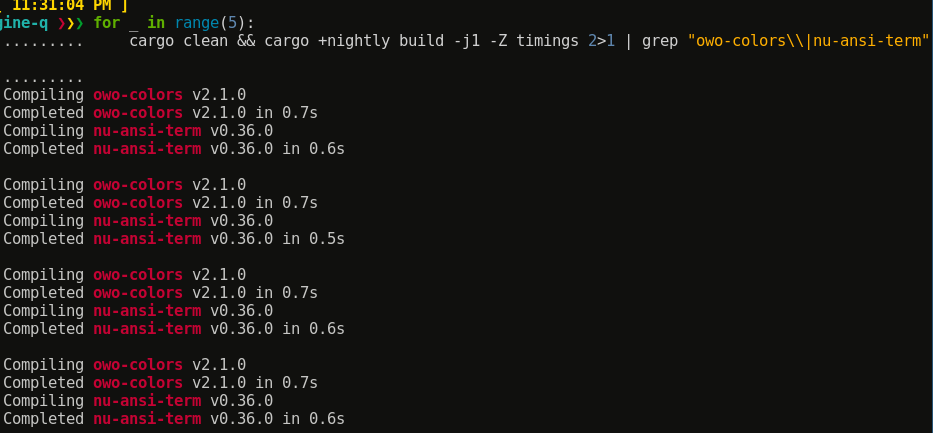
wow - lots of comments. lol. i'll try to reply one at a time. but first, i should've mentioned that my timings come from the html file created from the command I specified. attaching it here so you can look at it. cargo-timing-20210930T130511Z.zip.
You can see it in the timeline graph

and in the table below

so this answers one part of your questions, about how/where the numbers came from.
This is my system spec for where these numbers were produced. Probably not the fastest but i like it.
| Key | Value |
|---|---|
| OS Name | Microsoft Windows 10 Pro |
| Version | 10.0.19043 Build 19043 |
| System Manufacturer | LENOVO |
| System Model | 20QN002GUS |
| System Type | x64-based PC |
| Processor | Intel(R) Core(TM) i9-9880H CPU @ 2.30GHz, 2304 Mhz, 8 Core(s), 16 Logical Processor(s) |
| Installed Physical Memory (RAM) | 32.0 GB |
here's the results compiled with cargo +nightly build -j1
Compiling owo-colors v2.1.0
time: 0.014; rss: 15MB -> 16MB ( +1MB) parse_crate
time: 0.000; rss: 16MB -> 16MB ( +0MB) attributes_injection
time: 0.000; rss: 16MB -> 16MB ( +0MB) plugin_loading
time: 0.000; rss: 16MB -> 16MB ( +0MB) plugin_registration
time: 0.000; rss: 17MB -> 17MB ( +0MB) crate_injection
time: 0.177; rss: 17MB -> 38MB ( +21MB) expand_crate
time: 0.000; rss: 38MB -> 38MB ( +0MB) check_unused_macros
time: 0.178; rss: 17MB -> 38MB ( +21MB) macro_expand_crate
time: 0.000; rss: 38MB -> 38MB ( +0MB) maybe_building_test_harness
time: 0.006; rss: 38MB -> 38MB ( +0MB) AST_validation
time: 0.000; rss: 38MB -> 38MB ( +0MB) maybe_create_a_macro_crate
time: 0.000; rss: 38MB -> 38MB ( +0MB) finalize_imports
time: 0.001; rss: 38MB -> 38MB ( +0MB) finalize_macro_resolutions
time: 0.016; rss: 38MB -> 42MB ( +4MB) late_resolve_crate
time: 0.000; rss: 42MB -> 42MB ( +0MB) resolve_main
time: 0.002; rss: 42MB -> 42MB ( +0MB) resolve_check_unused
time: 0.000; rss: 42MB -> 42MB ( +0MB) resolve_report_errors
time: 0.001; rss: 42MB -> 42MB ( +0MB) resolve_postprocess
time: 0.020; rss: 38MB -> 42MB ( +4MB) resolve_crate
time: 0.003; rss: 42MB -> 42MB ( +0MB) complete_gated_feature_checking
time: 0.208; rss: 16MB -> 42MB ( +26MB) configure_and_expand
time: 0.002; rss: 42MB -> 42MB ( +0MB) prepare_outputs
time: 0.028; rss: 42MB -> 48MB ( +6MB) hir_lowering
time: 0.017; rss: 48MB -> 48MB ( +0MB) early_lint_checks
time: 0.010; rss: 48MB -> 41MB ( -8MB) drop_ast
time: 0.000; rss: 38MB -> 38MB ( +0MB) setup_global_ctxt
time: 0.000; rss: 41MB -> 41MB ( +0MB) looking_for_entry_point
time: 0.000; rss: 41MB -> 41MB ( +0MB) looking_for_derive_registrar
time: 0.018; rss: 41MB -> 44MB ( +3MB) misc_checking_1
time: 0.015; rss: 44MB -> 46MB ( +3MB) type_collecting
time: 0.001; rss: 46MB -> 46MB ( +0MB) impl_wf_inference
time: 0.000; rss: 52MB -> 52MB ( +0MB) unsafety_checking
time: 0.000; rss: 52MB -> 52MB ( +0MB) orphan_checking
time: 0.008; rss: 46MB -> 52MB ( +6MB) coherence_checking
time: 0.041; rss: 52MB -> 56MB ( +4MB) wf_checking
time: 0.012; rss: 56MB -> 57MB ( +1MB) item_types_checking
time: 0.208; rss: 57MB -> 69MB ( +12MB) item_bodies_checking
time: 0.289; rss: 44MB -> 69MB ( +25MB) type_check_crate
time: 0.021; rss: 69MB -> 69MB ( +1MB) match_checking
time: 0.005; rss: 69MB -> 69MB ( +0MB) liveness_and_intrinsic_checking
time: 0.026; rss: 69MB -> 69MB ( +1MB) misc_checking_2
time: 0.225; rss: 69MB -> 86MB ( +17MB) MIR_borrow_checking
time: 0.022; rss: 86MB -> 87MB ( +1MB) MIR_effect_checking
time: 0.000; rss: 87MB -> 87MB ( +0MB) layout_testing
time: 0.003; rss: 87MB -> 88MB ( +0MB) death_checking
time: 0.000; rss: 88MB -> 88MB ( +0MB) unused_lib_feature_checking
time: 0.016; rss: 88MB -> 88MB ( +1MB) crate_lints
time: 0.014; rss: 88MB -> 89MB ( +0MB) module_lints
time: 0.031; rss: 88MB -> 89MB ( +1MB) lint_checking
time: 0.012; rss: 89MB -> 89MB ( +0MB) privacy_checking_modules
time: 0.050; rss: 87MB -> 89MB ( +2MB) misc_checking_3
time: 0.000; rss: 96MB -> 96MB ( +0MB) monomorphization_collector_root_collections
time: 0.054; rss: 96MB -> 102MB ( +7MB) monomorphization_collector_graph_walk
time: 0.005; rss: 102MB -> 103MB ( +0MB) partition_and_assert_distinct_symbols
time: 0.119; rss: 89MB -> 103MB ( +14MB) generate_crate_metadata
time: 0.000; rss: 104MB -> 104MB ( +0MB) find_cgu_reuse
time: 0.000; rss: 106MB -> 106MB ( +0MB) LLVM_module_optimize_function_passes(owo_colors.0d562811-cgu.0)
time: 0.000; rss: 106MB -> 106MB ( +0MB) LLVM_module_optimize_module_passes(owo_colors.0d562811-cgu.0)
time: 0.000; rss: 109MB -> 109MB ( +0MB) LLVM_module_optimize_function_passes(owo_colors.0d562811-cgu.14)
time: 0.000; rss: 109MB -> 109MB ( +0MB) LLVM_module_optimize_module_passes(owo_colors.0d562811-cgu.14)
time: 0.000; rss: 110MB -> 110MB ( +0MB) LLVM_module_optimize_function_passes(owo_colors.0d562811-cgu.1)
time: 0.000; rss: 110MB -> 110MB ( +0MB) LLVM_module_optimize_module_passes(owo_colors.0d562811-cgu.1)
time: 0.000; rss: 108MB -> 108MB ( +0MB) LLVM_module_optimize_function_passes(owo_colors.0d562811-cgu.13)
time: 0.000; rss: 108MB -> 108MB ( +0MB) LLVM_module_optimize_module_passes(owo_colors.0d562811-cgu.13)
time: 0.000; rss: 109MB -> 109MB ( +0MB) LLVM_module_optimize_function_passes(owo_colors.0d562811-cgu.2)
time: 0.000; rss: 109MB -> 109MB ( +0MB) LLVM_module_optimize_module_passes(owo_colors.0d562811-cgu.2)
time: 0.000; rss: 108MB -> 108MB ( +0MB) LLVM_module_optimize_function_passes(owo_colors.0d562811-cgu.12)
time: 0.000; rss: 108MB -> 108MB ( +0MB) LLVM_module_optimize_module_passes(owo_colors.0d562811-cgu.12)
time: 0.000; rss: 109MB -> 109MB ( +0MB) LLVM_module_optimize_function_passes(owo_colors.0d562811-cgu.3)
time: 0.003; rss: 109MB -> 109MB ( +0MB) LLVM_module_optimize_module_passes(owo_colors.0d562811-cgu.3)
time: 0.000; rss: 111MB -> 111MB ( +0MB) LLVM_module_optimize_function_passes(owo_colors.0d562811-cgu.10)
time: 0.000; rss: 111MB -> 111MB ( +0MB) LLVM_module_optimize_module_passes(owo_colors.0d562811-cgu.10)
time: 0.000; rss: 111MB -> 111MB ( +0MB) LLVM_module_optimize_function_passes(owo_colors.0d562811-cgu.6)
time: 0.000; rss: 111MB -> 111MB ( +0MB) LLVM_module_optimize_module_passes(owo_colors.0d562811-cgu.6)
time: 0.000; rss: 111MB -> 111MB ( +0MB) LLVM_module_optimize_function_passes(owo_colors.0d562811-cgu.9)
time: 0.000; rss: 111MB -> 111MB ( +0MB) LLVM_module_optimize_module_passes(owo_colors.0d562811-cgu.9)
time: 0.000; rss: 111MB -> 111MB ( +0MB) LLVM_module_optimize_function_passes(owo_colors.0d562811-cgu.4)
time: 0.000; rss: 111MB -> 111MB ( +0MB) LLVM_module_optimize_module_passes(owo_colors.0d562811-cgu.4)
time: 0.000; rss: 111MB -> 111MB ( +0MB) LLVM_module_optimize_function_passes(owo_colors.0d562811-cgu.11)
time: 0.000; rss: 111MB -> 111MB ( +0MB) LLVM_module_optimize_module_passes(owo_colors.0d562811-cgu.11)
time: 0.000; rss: 111MB -> 111MB ( +0MB) LLVM_module_optimize_function_passes(owo_colors.0d562811-cgu.5)
time: 0.000; rss: 111MB -> 111MB ( +0MB) LLVM_module_optimize_module_passes(owo_colors.0d562811-cgu.5)
time: 0.000; rss: 111MB -> 111MB ( +0MB) LLVM_module_optimize_function_passes(owo_colors.0d562811-cgu.8)
time: 0.000; rss: 111MB -> 111MB ( +0MB) LLVM_module_optimize_module_passes(owo_colors.0d562811-cgu.8)
time: 0.000; rss: 111MB -> 111MB ( +0MB) LLVM_module_optimize_function_passes(owo_colors.0d562811-cgu.15)
time: 0.000; rss: 111MB -> 111MB ( +0MB) LLVM_module_optimize_module_passes(owo_colors.0d562811-cgu.15)
time: 0.000; rss: 112MB -> 112MB ( +0MB) LLVM_module_optimize_function_passes(owo_colors.0d562811-cgu.7)
time: 0.000; rss: 112MB -> 112MB ( +0MB) LLVM_module_optimize_module_passes(owo_colors.0d562811-cgu.7)
time: 0.060; rss: 104MB -> 112MB ( +8MB) codegen_to_LLVM_IR
time: 0.302; rss: 106MB -> 112MB ( +6MB) LLVM_passes(crate)
time: 0.317; rss: 103MB -> 112MB ( +8MB) codegen_crate
time: 0.000; rss: 112MB -> 112MB ( +0MB) serialize_dep_graph
time: 0.016; rss: 112MB -> 51MB ( -60MB) free_global_ctxt
time: 0.000; rss: 51MB -> 51MB ( +0MB) join_worker_thread
time: 0.000; rss: 51MB -> 51MB ( +0MB) finish_ongoing_codegen
time: 0.000; rss: 51MB -> 51MB ( +0MB) llvm_dump_timing_file
time: 0.000; rss: 51MB -> 51MB ( +0MB) serialize_work_products
time: 0.001; rss: 51MB -> 51MB ( +0MB) link_binary_check_files_are_writeable
time: 0.133; rss: 51MB -> 51MB ( +1MB) link_rlib
time: 0.004; rss: 51MB -> 51MB ( +0MB) link_binary_remove_temps
time: 0.140; rss: 51MB -> 51MB ( +1MB) link_binary
time: 0.140; rss: 51MB -> 50MB ( -1MB) link_crate
time: 0.140; rss: 51MB -> 50MB ( -2MB) link
time: 1.534; rss: 11MB -> 46MB ( +35MB) total
The -j1 makes a huge difference in these timings. I'm not real sure why.
This command cargo +nightly build -Z timings="html,info" yields

while this command cargo +nightly build -j1 -Z timings="html,info" yields

So, I think your performance for version 2.1 is probably close to on par with nu-ansi-term. I'll confirm next, what you've said, that style is optimized now.
wow that's so weird. your specs are beefier than anything I have to test on and yet even my digital ocean machine chokes less??? that seems like an issue in something deeper than owo-colors x.x
Here's what the optimized styles produces with the following code.

let colored_text = format!(
"{hello} {world}",
hello = "Hello".fg::<Black>().bg::<White>(),
world = "World".fg::<Magenta>().bg::<Green>(),
);
let colored_text2 = format!(
"{hello} {world}",
hello = Color::Black.on(Color::White).paint("Hello"),
world = Color::Magenta.on(Color::Green).paint("World"),
);
let hello = String::from("Hello");
let world = String::from("World");
let colored_text3 = format!(
"{hello} {world}",
hello = hello.black().on_white(),
world = world.magenta().on_green(),
);
println!("owo-colors : {:#?}", colored_text);
println!("{}", colored_text);
println!("nu-ansi-term: {:#?}", colored_text2);
println!("{}", colored_text2);
println!("owo styles : {:#?}", colored_text3);
println!("{}", colored_text3);47 is the background
30 is the foreground
apparently, it doesn't matter which order they're in, which is kind of weird. i'm not exactly sure what the ansi spec says.
I looked into the ANSI spec a good bit while working on this and from my reading of it, the order of ANSI codes is arbitrary they're just semicolon-separated and applied in-order. since setting foreground doesn't clear background or vice-versa, the order is pretty irrelevant (short of a buggy implementation by the terminal emulator)
Also all of my testing has been against alacritty, so there's definitely a non-zero chance that some terminal emulator has compat issues due to improper implementation. If you happen to see that happening to anyone absolutely forward such an issue my way!
OH. I see the bug you're seeing in the first test. I can totally fix that, I just forgot to make this optimization work for the generic methods!!
If you test against the non-generic methods (e.g. .fg::<Black>().bg::<White>() can be made into .black().on_white()) you'll see this is already working on those, but good catch!!
Good to know. I use Windows Terminal.
Im guessing that some of the performance differences we're seeing may be related to NTFS and McAfee virus scan. I know ext3 is faster. I'll try to build in wsl2 and see what the perf looks like.
Alright @fdncred, fixed generic methods on master next time you get a chance to test. Should fix your .fg::<Black>().bg::<White>() test, and hopefully fix the last of your ANSI sequence optimization issues :)
Once you confirm that there aren't any issues for your use case I'll publish a 3.0.0-beta.0. (I'm working on a set of opt-in macros that extend the syntax of println/format/etc to add support for colors and 3.0 will be published after that is done) However if you don't feel comfortable being dependent on a beta and you start getting close to release then I will absolutely save the macros for 3.1.0 and just publish 3.0.0. I plan to have the macros done in less than a month, so in theory 3.0 should be out of beta before you publish (as, afaik, engine-q isn't published yet?), but again if that isn't the case I will 100% upgrade the beta to the full release given 2-3 days notice of you needing it ❤️
(also again I should note that these macros will be opt-in and will have zero effect on your compile times. not that it'd matter I suppose since miette is already dependent on syn, for good reason I might add)
Just tested the output and nu-ansi-term, owo-colors, and owo styles output are identical. I also tested the perf in wsl2 and i get this.
Compiling owo-colors v2.1.0
Completed owo-colors v2.1.0 in 0.7s
Compiling nu-ansi-term v0.36.0
Completed nu-ansi-term v0.36.0 in 0.4s
it's really miette that uses owo-colors. engine-q is going to be absorbed into nushell (or vice versa) and it's going to take a few months. nushell/engine-q aren't currently using owo-colors. I just had objections to miette using it because the ansi sequences were concatenated, which you've now fixed. so, release when you feel you're ready.
good work on working through these issues. as far as i'm concerned, the issues are closed and you can feel free to close this issue too. thanks again!
np!! thank you so much for your help working through these issues