EdgeFormer: Improving Light-weight ConvNets by Learning from Vision Transformers
Official PyTorch implementation of EdgeFormer
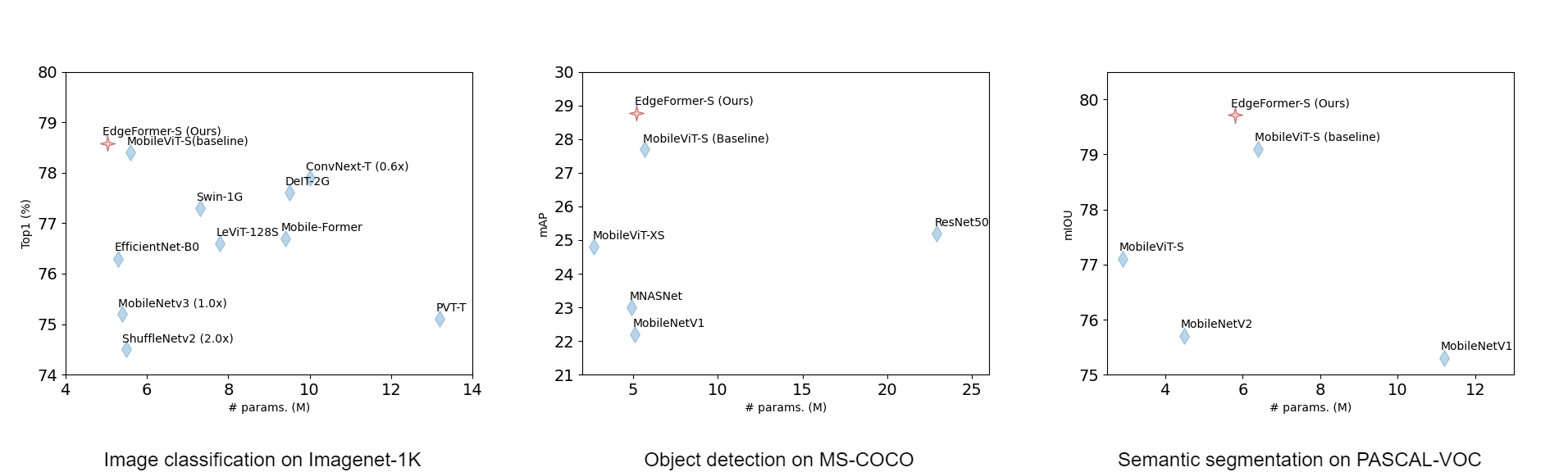
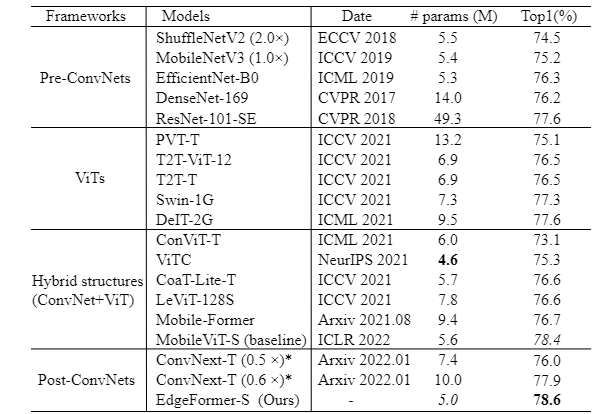
Introduction
EdgeFormer, a pure ConvNet based light weight backbone model that inherits advantages of ConvNets and integrates strengths of vision transformers. Specifically, we propose global circular convolution (GCC) with position embeddings, a light-weight convolution op which boasts a global receptive field while producing location sensitive features as in local convolutions. We combine the GCCs and squeeze-exictation ops to form a meta-former like model block, which further has the attention mechanism like transformers. The aforementioned block can be used in plug-and-play manner to replace relevant blocks in ConvNets or transformers. Experiment results show that the proposed EdgeFormer achieves better performance than popular light-weight ConvNets and vision transformer based models in common vision tasks and datasets, while having fewer parameters and faster inference speed. For classification on ImageNet-1k, EdgeFormer achieves 78.6% top-1 accuracy with about 5.0 million parameters, saving 11% parameters and 13% computational cost but gaining 0.2% higher accuracy and 23% faster inference speed (on ARM based Rockchip RK3288) compared with MobileViT.
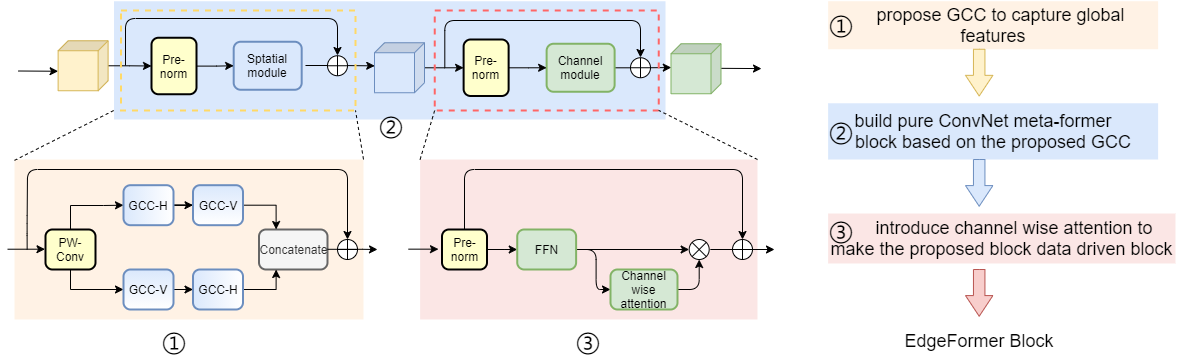
EdgeFormer block
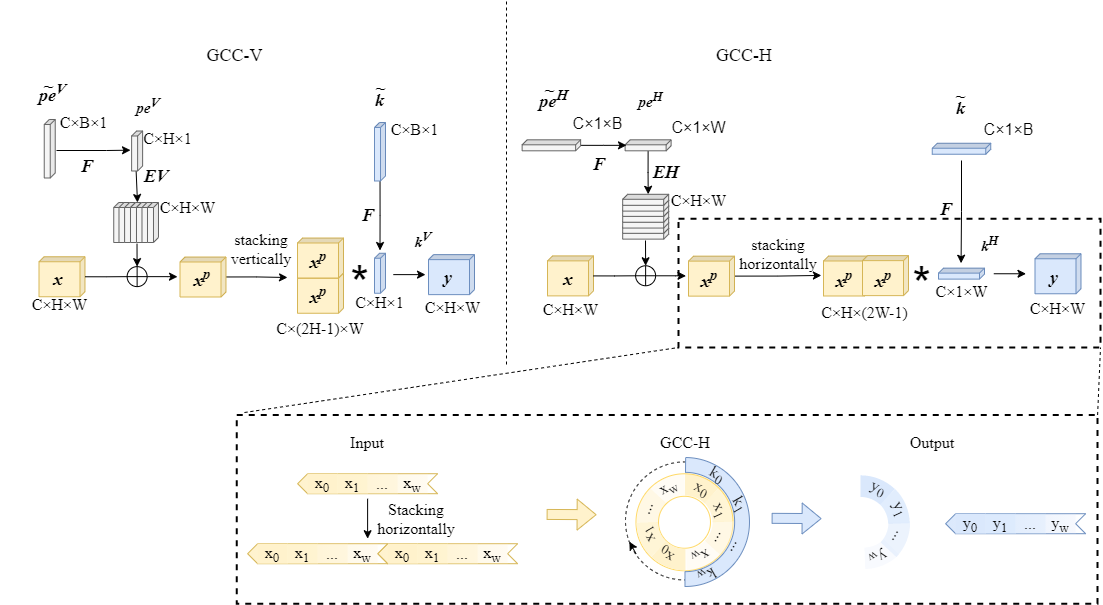
Global circular convolution
Experimental results
EdgeFormer-S
| Tasks | performance | #params | pretrained models |
|---|---|---|---|
| Classification | 78.6 (Top1 acc) | 5.0 | model |
| Detection | 28.8 (mAP) | 5.2 | model |
| Segmentation | 79.7 (mIOU) | 5.8 | model |
Inference speed
We deploy the proposed EdgeFormer and baseline on widely used low power chip Rockchip RK3288 and DP2000 chip for comparison. DP2000 is the code name of a in house unpublished low power neural network processor that highly optimizes the convolutions. We use ONNX [1] and MNN to port these models to RK3288 and DP2000 chip and time each model for 100 iterations to measure the average inference speed.
| Models | #params (M) | Madds (M) | RK3288 inference speed (ms) | DP2000 (ms) | Top1 acc |
|---|---|---|---|---|---|
| MobileViT-S | 5.6 | 2010 | 457 | 368 | 78.4 |
| EdgeFormer-S | 5.0 (-11%) | 1740 (-13%) | 353 (+23%) | 98 (3.77x) | 78.6 (+0.2%) |
Applying Edgeformer designs on various lightweight backbones
Classification experiments. CPU used here is Xeon E5-2680 v4. *Authors of EdgeViT do not clarify the type of CPU used in their paper.
| Models | # params | Madds | Devices | Speed(ms) | Top1 acc | Source |
|---|---|---|---|---|---|---|
| MobileViT-S | 5.6 M | 2.0G | RK3288 | 457 | 78.4 | ICLR 22 |
| EdgeFormer-S | 5.0 M | 1.7G | RK3288 | 353 | 78.6 | Ours |
| MobileViT-S | 5.6 M | 2.0G | DP2000 | 368 | 78.4 | ICLR 22 |
| EdgeFormer-S | 5.0 M | 1.7G | DP2000 | 98 | 78.6 | Ours |
| ResNet50 | 26 M | 2.1G | CPU | 98 | 78.8 | CVPR 16 |
| GCC-ResNet50 | 24 M | 2.0G | CPU | 98 | 79.6 | Ours |
| MobileNetV2 | 3.5 M | 0.3G | CPU | 24 | 70.2 | CVPR 18 |
| GCC-MobileNetV2 | 3.5 M | 0.3G | CPU | 27 | 71.1 | Ours |
| ConvNext-XT | 7.4 M | 0.6G | CPU | 47 | 77.5 | CVPR 22 |
| GCC-ConvNext-XT | 7.4 M | 0.6G | CPU | 48 | 78.3 | Ours |
| EdgeViT-XS | 6.7 M | 1.1G | CPU* | 54* | 77.5 | Arxiv 22/05 |
| GCC-EdgeViT-XS |
Detection experiments
| Models | # params | AP box | AP50 box | AP75 box | AP mask | AP50 mask | AP75 mask |
|---|---|---|---|---|---|---|---|
| ConvNext-XT | - | 47.2 | 65.6 | 51.4 | 41.0 | 63.0 | 44.2 |
| GCC-ConvNext-XT | - | 47.7 | 66.2 | 52.0 | 41.5 | 63.6 | 44.6 |
Segmentation experiments
To be done
ConvNext block and ConvNext-GCC block
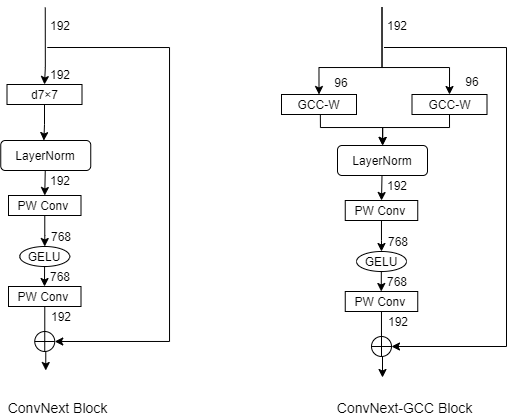
In terms of designing a pure ConvNet via learning from ViTs, our proposed EdgeFormer is most closely related to a parallel work ConvNext. By comparing Edgeformer with Convnext, we notice that their improvements are different and complementary. To verify this point, we build a combination network, where Edgeformer blocks are used to replace several ConvNext blocks in the end of last two stages. Experiment results show that the replacement signifcantly improves classification accuracy, while slightly decreases the number of parameters. Results on ResNet50, MobileNetV2 and ConvNext-T shows that models which focus on optimizing FLOPs-accuracy trade-offs can also benefit from our EdgeFormer designs. Corresponding code will be released soon.
Installation
We implement the EdgeFomer with PyTorch-1.9.0, CUDA=11.1.
PiP
The environment can be build in the local python environment using the below command:
pip install -r requirements.txt
Dokcer
A docker image containing the environment will be provided soon.
Training
Training settings are listed in yaml files (./config/classification/xxx/xxxx.yaml, ./config/detection/xxx/xxxx.yaml, ./config/segmentation/xxx/xxxx.yaml )
Classifiction
cd EdgeFormer-main
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python main_train.py --common.config-file ./config/classification/edgeformer/edgeformer_s.yaml
Detection
cd EdgeFormer-main
CUDA_VISIBLE_DEVICES=0,1,2,3 python main_train.py --common.config-file --common.config-file config/detection/ssd_edgeformer_s.yaml
Segmentation
cd EdgeFormer-main
CUDA_VISIBLE_DEVICES=0,1,2,3 python main_train.py --common.config-file --common.config-file config/segmentation/deeplabv3_edgeformer_s.yaml
Evaluation
Classifiction
cd EdgeFormer-main
CUDA_VISIBLE_DEVICES=0 python eval_cls.py --common.config-file ./config/classification/edgeformer/edgeformer_s.yaml --model.classification.pretrained ./pretrained_models/classification/checkpoint_ema_avg.pt
Detection
cd EdgeFormer-main
CUDA_VISIBLE_DEVICES=0 python eval_det.py --common.config-file ./config/detection/edgeformer/ssd_edgeformer_s.yaml --model.detection.pretrained ./pretrained_models/detection/checkpoint_ema_avg.pt --evaluation.detection.mode validation_set --evaluation.detection.resize-input-images
Segmentation
cd EdgeFormer-main
CUDA_VISIBLE_DEVICES=0 python eval_seg.py --common.config-file ./config/detection/edgeformer/deeplabv3_edgeformer_s.yaml --model.segmentation.pretrained ./pretrained_models/segmentation/checkpoint_ema_avg.pt --evaluation.segmentation.mode validation_set --evaluation.segmentation.resize-input-images
Acknowledgement
We thank authors of MobileVit for sharing their code. We implement our EdgeFormer based on their source code. If you find this code is helpful in your research, please consider citing our paper and MobileVit