- Transformer: Type of deep neural network architecture that is used to solve the problem of transduction or transformation of input sequences into output sequences.

- MSMARCO Dataset.
- Dataset: https://huggingface.co/datasets/ms_marco
- BERT and GPT are both foundation models. Let’s look at the definition and characteristics:
- Pre-trained on different types of unlabeled datasets (e.g., language and images)
- Self-supervised learning
- Generalized data representations which can be used in multiple downstream tasks (e.g., classification and generation)
- The Transformer architecture is mostly used, but not mandatory
"Read this blog" Foundation Models at IBM "to find out more."
-
As mentioned, there are encoders and decoders. BERT uses encoders only, GTP uses decoders only. Both options understand language including syntax and semantics. Especially the next generation of large language models like GPT with billions of parameters do this very well.
-
The two models focus on different scenarios. However, since the field of foundation models is evolving, the differentiation is often fuzzier.
- BERT (encoder): classification (e.g., sentiment), questions and answers, summarization, named entity recognition
- GPT (decoder): translation, generation (e.g., stories)
-
The outputs of the core models are different:
- BERT (encoder): Embeddings representing words with attention information in a certain context
- GPT (decoder): Next words with probabilities
-
Both models are pretrained and can be reused without intensive training. Some of them are available as open source and can be downloaded from communities like Hugging Face, others are commercial. Reuse is important, since trainings are often very resource intensive and expensive which few companies can afford.
-
The pretrained models can be extended and customized for different domains and specific tasks. Layers can sometimes be reused without modifications and more layers are added on top. If layers need to be modified, the new training is more expensive. The technique to customize these models is called Transfer Learning, since the same generic model can easily be transferred to other domains.
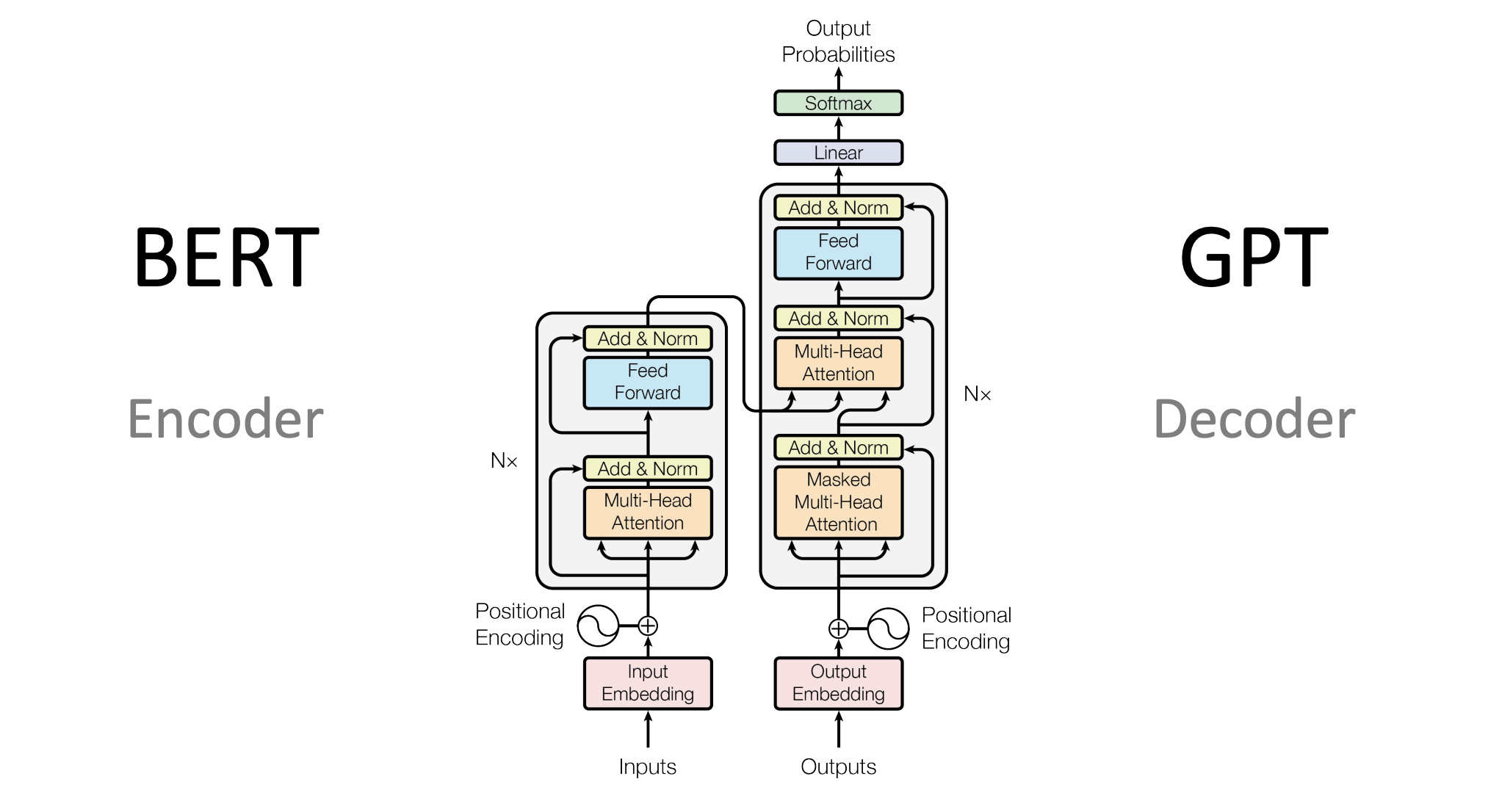
-
BERT uses the encoder part of the transformer architecture so that it understands semantic and syntactic language information. The output of BERT are embeddings, not predicted next words. To leverage these embeddings, other layer(s) need to be added on top, for example text classification or questions and answers.
-
BERT uses a genius trick for the training. For supervised training it is often expensive to get labeled data, sometimes it’s impossible. The trick is to use masks as I described in my post Evolution of AI explained via a simple Sample. Let’s take a simple example, an unlabeled sentence:
-
“Sarah went to a restaurant to meet her friend that night.”
-
This is converted into:
- Text: “Sarah went to a restaurant to meet her MASK that night.”
- Label: “Sarah went to a restaurant to meet her friend that night.”
-
Note that this is a very simplified description only since there aren’t ‘real’ labels in BERT.
-
-
In other words, BERT produces labeled data for originally unlabeled data. This technique is called Self-Supervised Learning. It works very well for huge amounts of data.
-
In masked language models like BERT, each masked word (token) prediction is conditioned on the rest of the tokens in the sentence. These are received in the encoder which is why you don’t need a decoder.
-
In language scenarios decoders are used to generate next words, for example when translating text or generating stories. The outputs are words with probabilities.
-
Decoders also use the attention concepts and even two times. First when training models, they use Masked Multi-Head Attention which means that only the first words of the target sentence are provided so that the model can learn without cheating. This mechanism is like the MASK concept from BERT.
-
After this the decoder uses Multi-Head Attention as it’s also used in the encoder. Transformer based models that utilize encoders and decoders use a trick to be more efficient. The output of the encoders is feed as input to the decoders, more precisely the keys and values. Decoders can invoke queries to find the closest keys. This allows, for example, to understand the meaning of the original sentence and translate it into other languages even if the number of resulting words and the order changes.
-
GPT doesn’t use this trick though and only use a decoder. This is possible since these types of models have been trained with massive amounts of data (Large Language Model). The knowledge of encoders is encoded in billions of parameters (also called weights). The same knowledge exists in decoders when trained with enough data.
-
Note that ChatGPT has evolved these techniques. To prevent hate, profanity and abuse, humans need to label some data first. Additionally Reinforcement Learning is applied to improve the quality of the model (see ChatGPT: Optimizing Language Models for Dialogue).