[CLIFF] Question about training CLIFF
MooreManor opened this issue · comments

@zhihaolee
I tried training CLIFF res50 from scratch.
Here is my exp setting. I used 4 GPUS with syncbatchnorm, and the batch size for per GPU is 64. The dataset setting for training CLIFF on Human3.6M, COCO (your pseudo GT), MPII (your pseudo GT), MPI-INF-3DHP, and 3DPW-train set with partitions 0.4, 0.3, 0.3, 0.1, 0.2 respectively. I didn't use the PARE syncocclusion for augmentation. I used lr 1xe-4 and didn't reduce it in the middle. I used the pretrained res50 weight on COCO instead of Imagenet. The input image size is 256x192.
The paper mentions that the learning rate is set to 1 ×e−4 and reduced by a factor of 10 in the middle.
The time when lr reduces is set to be in the middle (i.e. the 100th epoch). However, I found at about 12th epoch during training, the result was 74.9 which is close to MPJPE 72.0 in your paper. I ran your checkpoint to eval on 3dpw, and got about 73.1 MPJPE on my computer. I think the result is close but with training only 12 epochs. The training epoch num should be 200, but only 12 epochs of training got a similar result.

- According to the evaluation performance, do I have to reduce the lr rate until the 100th epoch? Maybe at the 10th epoch?
- Is the convergence speed of my experiment similar to yours?
Here is the training log. Did I make something wrong?


Glad you make a almost successful training implementation!
- Your convergence is faster than mine, and the main reason is that you use the res50 backbone pretrained on COCO instead of Imagenet, and I think you should have a better performance due to this.
- Your partition sum is bigger than 1, which will drop the MPI-INF-3DHP, and 3DPW-train datasets. My partition is: Human3.6M 0.4, COCO (cliffGT) 0.2, MPII (cliffGT) 0.1, MPI-INF-3DHP 0.1, and 3DPW-train 0.2.
- In your case of faster convergence, I suggest you reduce the learning rate at the 50th epoch, just let the bullet fly for a little while (haha)
Thanks for your advice! There's something wrong with what I said about the dataset settings. The partition is actually 0.3 for all ITW datasets, and the partition for a single ITW dataset depends on its proportion in all ITW datasets. The partition for MPII is almost 0.1, and that for COCO is almost 0.2.
Here is the current log.
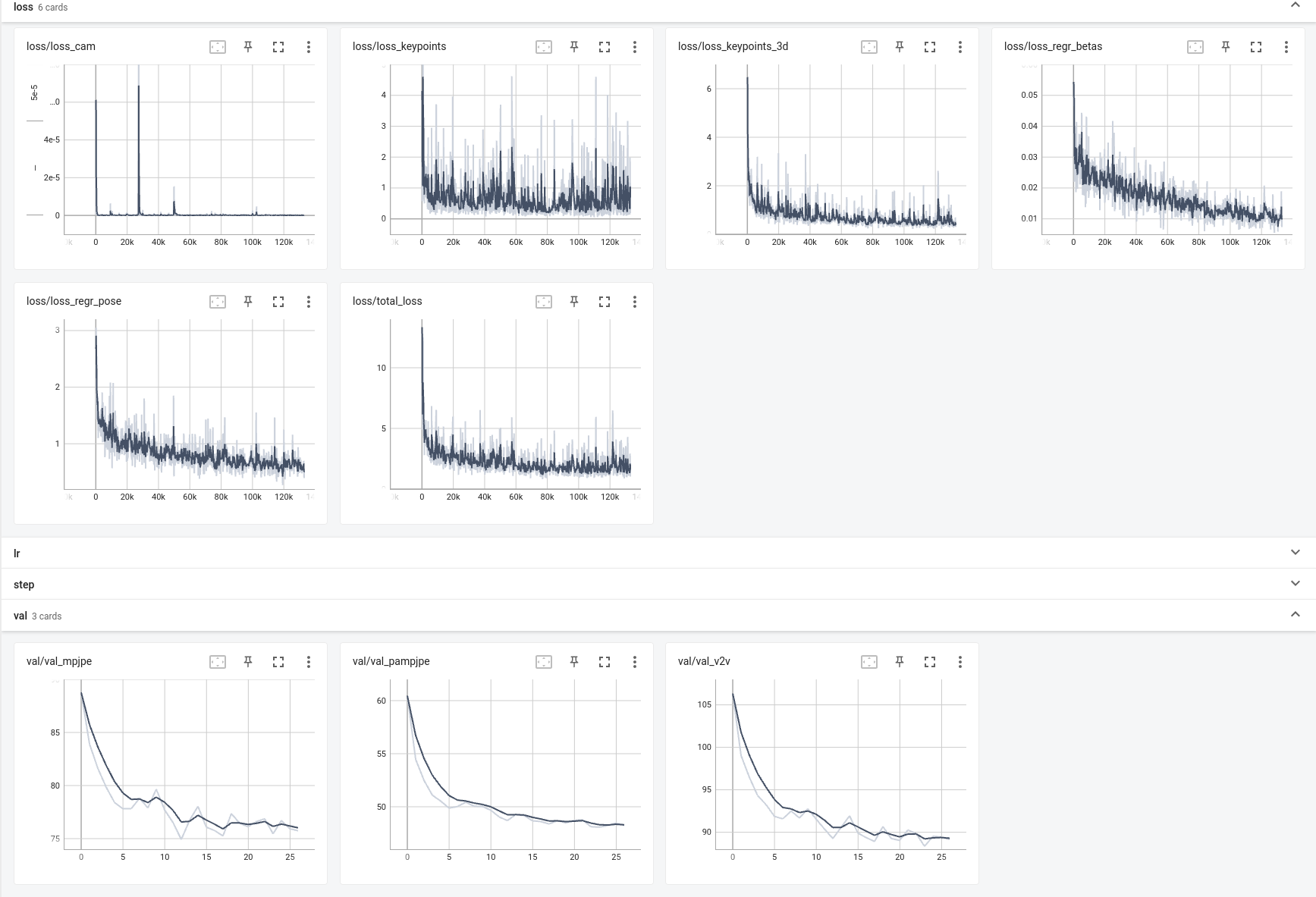
- Do I have to set the partition to a specific number or just leave it alone?
- Since the vanilla CLIFF uses PARE SYNCOCC, how much score can this augmentation promote? Do you have the ablation study of the augmentations?
- Based on the current log, is it necessary to train 200 epochs? Would 60 epochs be all right? Or maybe 100 epochs?
- As you said let the bullet fly for a little while, I will post the training log later here after the network trains for more steps with the fixed LR 1xe-4. Maybe you could give me some more advice about when to reduce LR and training settings according to a more sufficient training log.
- Just leave it alone.
- 1-2 mm improvements.
- There are 1219 steps per epoch in my setting. It looks like you have more steps than mine, so the training epoch number should be reduced according to your step number per epoch.
@zhihaolee Sorry, I check the code, actually, the batch size per GPU is 16, which means mine has 4x more steps. I can't increase the batch size because of the GPU memory. So here are two schemes. One scheme is that I will downgrade the learning rate by 4 (i.e. 2.5x10-5) and use batch size 16, and the other is using normal BN instead of syncBN which will increase the batch size to 32. Which one do you think is better?
SyncBN is essential for the multi-GPU training, so the former is better, and you don't need to reduce the learning rate if no gradient explosion exists.

Hi, Zhihao~ Thanks for your great work in CLIFF.
I would like to know how you prepare the training data. I suppose you prepared the training data following previous works, could you let us know the GitHub repo that with the training data you are using?
Thank you very much!
@Frank-Dz Thanks for your interest, please refer to https://github.com/nkolot/SPIN.

@MooreManor Hi, I was also looking into implementing CLIFF training but I got stuck while looking into SPIN for reference. Would it be possible for you to generously share your implementation code? I'm all new to this field and really want to get into it. :)
Thanks a bunch!

Sorry to bother you, it is difficult for me to modify the spin to train the cliff, I was wondering if you could be generous enough to share your training code below, thank you very much

@MooreManor
Hi, sorry to bother you. I was wondering if you could be generous to share your training code, thank you very much!