Mixed precision support for pytorch
un-knight opened this issue · comments

Does horovod support mixed precision triaining for pytorch like nvidia apex?

@un-knight, I was able to get Apex to work with Horovod, please see gist - look for # Apex comments. I also applied the same changes to our PyTorch ImageNet example and it successfully trained for a few epochs with loss / accuracy identical to regular FP32 training.
Important things:
- Do
amp.initialize()after optimizer is wrapped into DistributedOptimizer. - Do
optimizer.synchronize()withinscale_lossblock (code).
Can you try it out and let us know if it works for you?
That is great! I will have a try and feadback, thx.
@alsrgv By the way, Does horovod will extend mixed precision support in native?
@un-knight, we didn't have plans so far as it seems to be orthogonal to distributed training.
@alsrgv In my project, apex can work with horovod, and I find something new and interesting:
optimizer.synchronize()operation will slow down the training throughput- comment
optimizer.synchronize()will work fun with apex-fp32, while invoke synchronize error with apex-fp16 - distributed training throughput with horovod is lower than pytorch native distributed
optimizer.synchronize() is added for safety - Apex applies a lot of modifications to underlying network and gradients which can conflict with asynchronous allreduce that is performed by DistributedOptimizer - you're seeing it in (2).
I'm not surprised Apex works faster with PyTorch native since that's what it was optimized for. Conceptually, both PyTorch and Horovod use similar PyTorch mechanics so it should be possible to make Apex work fast, but ongoing support would require commitment from Apex team.
How big of a gap are you seeing with Horovod vs native PyTorch distributed with Apex?
@un-knight, a couple of updates:
#597 introduced a performance regression for use-cases involving manual synchronize(). As pointed out in #1099, it causes duplicate allreduce.
As a workaround, can you specify optimizer._requires_update = set() after DistributedOptimizer wraps original optimizer, like this?
This workaround led to significant performance improvement in my environment. I'm curious to hear about your experience.
@un-knight, the fix was merged into master. You can reinstall Horovod from master (or wait a bit for 0.16.3), and use .step(synchronize=False), like this.
@alsrgv There is my experiment result:
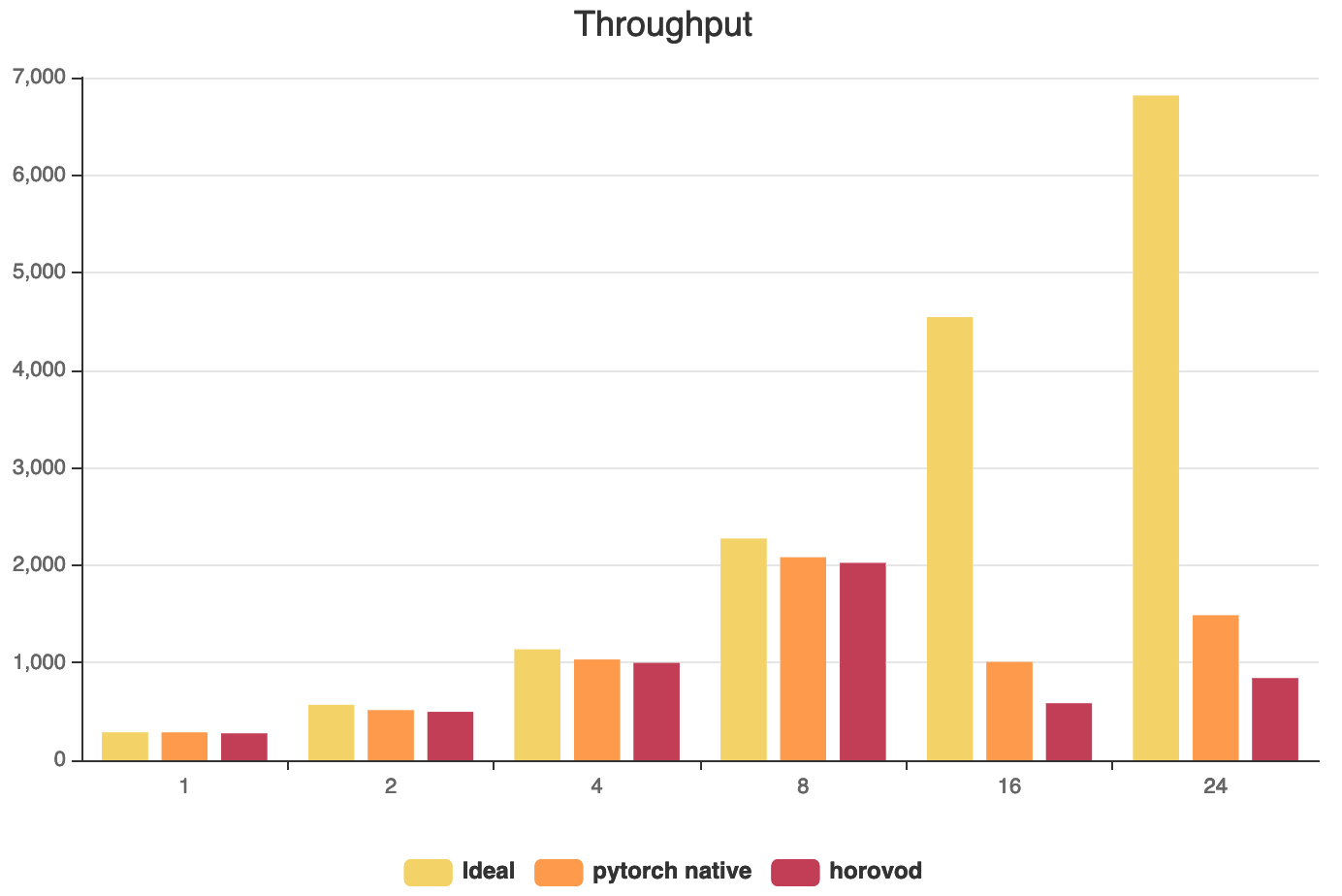
So in multi-nodes environment(16 and 24 gpus), the horovod throughput is really poorer than pytorch native api.
And thanks for your workaround! I will have a try in my spare time.
@un-knight, thanks for sharing the results. I think using the latest master branch code (pip uninstall -y horovod; [flags] pip install --no-cache-dir git+https://github.com/horovod/horovod) and optimizer.step(synchronize=False), you should be able to recover most of the performance difference.
It looks like your network performance is not great. What network adapters do you use?
You may gain further performance by using fp16 compression of gradients via hvd.DistributedOptimizer(..., compression=hvd.Compression.fp16) (docs link1, link2)
@alsrgv Yes, compression does help, the result above have used fp16 compression. And I know the network is a big bottleneck since the theory bandwidth is just 1Gbps ethernet. Besides, I find something else in the log NCCL INFO NET/Plugin : No plugin found (libnccl-net.so)., does this will have an implicit impact on the communication scalability between gpus?
@un-knight, the message you mentioned should not have any impact, but 1G is just too slow. I'd recommend upgrading the network - it's pretty cheap compared to the GPUs.
@alsrgv I update horovod from 0.16.1 to 0.16.2 following your instructions above, but getting a timeout error when starting the training script. Does it seem that the latest horovod have some connectivity problem?
@un-knight, what error message are you seeing? It may be helpful to specify --start-timeout 600 in some cases to extend the timeout.
@alsrgv The error message is:
Traceback (most recent call last):
File "/opt/anaconda/bin/horovodrun", line 21, in <module>
run.run()
File "/opt/anaconda/lib/python3.7/site-packages/horovod/run/run.py", line 425, in run
settings, fn_cache=fn_cache)
File "/opt/anaconda/lib/python3.7/site-packages/horovod/run/util/cache.py", line 103, in wrap_f
results = func(*args, **kwargs)
File "/opt/anaconda/lib/python3.7/site-packages/horovod/run/run.py", line 221, in _driver_fn
driver.wait_for_initial_registration(settings.timeout)
File "/opt/anaconda/lib/python3.7/site-packages/horovod/run/common/service/driver_service.py", line 117, in wait_for_initial_registration
timeout.check_time_out_for('tasks to start')
File "/opt/anaconda/lib/python3.7/site-packages/horovod/run/common/util/timeout.py", line 32, in check_time_out_for
raise Exception(self._message.format(activity=activity))
Exception: Timed out waiting for tasks to start. Please check connectivity between servers. You may need to increase the --start-timeout parameter if you have too many servers.
And I have tried to set --start-timeout=120, but it's useless. So I think there might be some connectivity problem.
@un-knight, can you try adding --verbose flag to see what's going on? Also, make sure you don't have typo in --start-timeout.
@alsrgv There is the output with --verbose:
Filtering local host names.
Checking ssh on all remote hosts.
SSH was successful into all the remote hosts.
Testing interfaces on all the hosts.
Launched horovodrun server.
Attempted to launch horovod task servers.
Waiting for the hosts to acknowledge.
Traceback (most recent call last):
File "/opt/anaconda/bin/horovodrun", line 21, in <module>
run.run()
File "/opt/anaconda/lib/python3.7/site-packages/horovod/run/run.py", line 425, in run
settings, fn_cache=fn_cache)
File "/opt/anaconda/lib/python3.7/site-packages/horovod/run/util/cache.py", line 103, in wrap_f
results = func(*args, **kwargs)
File "/opt/anaconda/lib/python3.7/site-packages/horovod/run/run.py", line 221, in _driver_fn
driver.wait_for_initial_registration(settings.timeout)
File "/opt/anaconda/lib/python3.7/site-packages/horovod/run/common/service/driver_service.py", line 117, in wait_for_initial_registration
timeout.check_time_out_for('tasks to start')
File "/opt/anaconda/lib/python3.7/site-packages/horovod/run/common/util/timeout.py", line 32, in check_time_out_for
raise Exception(self._message.format(activity=activity))
Exception: Timed out waiting for tasks to start. Please check connectivity between servers. You may need to increase the --start-timeout parameter if you have too many servers.
And I am sure that I don't have typo.
Besides, I will get the following error message randomly, it's really strange:
Filtering local host names.
Checking ssh on all remote hosts.
SSH was successful into all the remote hosts.
Testing interfaces on all the hosts.
Launched horovodrun server.
Attempted to launch horovod task servers.
Waiting for the hosts to acknowledge.
Launching horovodrun task function was not successful:
Usage: /opt/anaconda/lib/python3.7/site-packages/horovod/run/task_fn.py <index> <service addresses> <num_hosts> <tmout> <key>
@un-knight, did you upgrade Horovod on all the hosts to the same version?
@alsrgv Yes, I make a new docker image, and I checked the horovod version twice.
@un-knight, one situation I've seen before is that the previous container is still running, and your ssh connections are routed there. Can you switch to a new port, or reboot the second machine to be extra sure? The fact that Usage: shows up in the log indicates a possible version mismatch.
@alsrgv After setting start-timeout to 500, the program can start up, but it's strange that horovod 0.16.2 spends more time to set up communication with each node.
In this case, with optimizer._requires_update = set() the scalebility effeciency is as better as pytorch native.
Besides, I got another error when running the script you shared:
[1,12]<stderr>: File "pytorch_synthetic_benchmark_apex.py", line 102, in <module>
[1,12]<stderr>: timeit.timeit(benchmark_step, number=args.num_warmup_batches)
[1,12]<stderr>: File "/opt/anaconda/lib/python3.7/timeit.py", line 232, in timeit
[1,12]<stderr>: return Timer(stmt, setup, timer, globals).timeit(number)
[1,12]<stderr>: File "/opt/anaconda/lib/python3.7/timeit.py", line 176, in timeit
[1,12]<stderr>: timing = self.inner(it, self.timer)
[1,12]<stderr>: File "<timeit-src>", line 6, in inner
[1,12]<stderr>: File "pytorch_synthetic_benchmark_apex.py", line 86, in benchmark_step
[1,12]<stderr>: optimizer.step(synchronize=False)
[1,12]<stderr>:TypeError: skip_step() got an unexpected keyword argument 'synchronize'
This error doesn't happen if I set amp opt_level to O0, it seems like our apex version are mismatch, so which version do you use?
@un-knight, glad to hear the performance is better! I've updated the script to use Horovod 0.16.3, can you upgrade to that version (released yesterday)?
@alsrgv ok, I will have a try. Then which apex version do you use?
@un-knight, I just used apex from master: pip install git+https://github.com/nvidia/apex
@alsrgv When I set amp opt_level to O1, an argument error will occur:
[1,12]<stderr>: File "pytorch_synthetic_benchmark_apex.py", line 102, in <module>
[1,12]<stderr>: timeit.timeit(benchmark_step, number=args.num_warmup_batches)
[1,12]<stderr>: File "/opt/anaconda/lib/python3.7/timeit.py", line 232, in timeit
[1,12]<stderr>: return Timer(stmt, setup, timer, globals).timeit(number)
[1,12]<stderr>: File "/opt/anaconda/lib/python3.7/timeit.py", line 176, in timeit
[1,12]<stderr>: timing = self.inner(it, self.timer)
[1,12]<stderr>: File "<timeit-src>", line 6, in inner
[1,12]<stderr>: File "pytorch_synthetic_benchmark_apex.py", line 86, in benchmark_step
[1,12]<stderr>: optimizer.step(synchronize=False)
[1,12]<stderr>:TypeError: skip_step() got an unexpected keyword argument 'synchronize'
This error doesn't happen when opt_level is O0
@un-knight, sorry - you're right, this example does not work 🤦♂ AMP does not support passing custom flags to optimizer.step().
I've pushed out #1132 with a fix and updated the Gist, could you give it a try (pip uninstall -y horovod; [flags] pip install --no-cache-dir git+https://github.com/horovod/horovod@fix_amp_support)?
@alsrgv Really thanks! now it can work correctly.
Great! The PR has been merged and new Horovod version will be released soon (#1139).
@alsrgv Find another bug, when I set amp apt_level to O2 and using fp16_compression, I get an error:
[1,0]<stderr>:Traceback (most recent call last):
[1,0]<stderr>: File "synthetic_benchmark.py", line 105, in <module>
[1,0]<stderr>: main()
[1,0]<stderr>: File "synthetic_benchmark.py", line 84, in main
[1,0]<stderr>: number=args.num_warmup_batches, globals=globals())
[1,0]<stderr>: File "/opt/anaconda/lib/python3.7/timeit.py", line 232, in timeit
[1,0]<stderr>: return Timer(stmt, setup, timer, globals).timeit(number)
[1,0]<stderr>: File "/opt/anaconda/lib/python3.7/timeit.py", line 176, in timeit
[1,0]<stderr>: timing = self.inner(it, self.timer)
[1,0]<stderr>: File "<timeit-src>", line 6, in inner
[1,0]<stderr>: File "/workspace/image-classification/libs/clf_train.py", line 151, in benchmark_step
[1,0]<stderr>: optimizer.synchronize()
[1,0]<stderr>: File "/opt/anaconda/lib/python3.7/site-packages/horovod/torch/__init__.py", line 157, in synchronize
[1,0]<stderr>: p.grad.set_(self._compression.decompress(output, ctx))
[1,0]<stderr>:RuntimeError: Expected object of scalar type Float but got scalar type Half for argument #2 'source'
while setting fp16_compression to false, or setting amp opt_level to O1 with fp16_compression will work.
@un-knight, I gathered a timeline for O2 and all the convolutional (large) gradients are actually allreduced in fp16 without the fp16_compression setting:


Hi, I have a question about using apex.amp in horovod setup.
From what I know, apex.amp uses dynamic scale loss where the loss is adaptively scaled over time. The loss is scaled when its value is NaN. But it seems that this information (whether the loss is NaN or not) is not shared between multiple processes in horovod. So in the training, if one or more processes have to adjust loss scale, they adjust the scale of only their own where different loss scales between processes induce NaN loss. Have you ever met such situation?
Hi, I have a question about using
apex.ampin horovod setup.
From what I know,apex.ampuses dynamic scale loss where the loss is adaptively scaled over time. The loss is scaled when its value is NaN. But it seems that this information (whether the loss is NaN or not) is not shared between multiple processes in horovod. Have you ever met such situation?
There is no need to share Nan information between multiple processes. Besides, the purpose of loss scaling is to avoid gradient presented in fp16 occurs underflow.
@un-knight Thank you for reply. I mean when the one of the process meet nan loss value, the call of loss.backward() induces nan value of its gradient (let me say it as nan_process). The problem is, when we call optimizer.synchronize() or optimizer.step(), this nan gradient is averaged (allreduced) across all processes so they share nan gradient. The call of optimizer.step() of nan_process is ignored because the nan value is detected at nan_process, but other processes update its parameter value with nan gradient (and they have nan parameters after) because nan loss is not detected at their own processes.
@seilna Oh I see, I think the first thing you should do is to check why your program will get Nan gradient during training. There must be some inappropriate op in your code, you should check it out.

@un-knight You mentioned that Horovod + multile-nodes will have worse performance than Pytorch's native distributed data parallel. Is it still the case? Moreover, does Horovod + Apex O1 work well?

Hi, @un-knight @alsrgv
When I set fp16-allreduce to True and setting amp opt_level to 01, the package error is as follows:
<stderr>: optimizer.synchronize()
<stderr>: File "/usr/local/lib64/python3.6/site-packages/horovod/torch/__init__.py", line 178, in synchronize
<stderr>: optimizer.synchronize()
<stderr>: File "/usr/local/lib64/python3.6/site-packages/horovod/torch/__init__.py", line 178, in synchronize
<stderr>: p.grad.set_(self._compression.decompress(output, ctx))
<stderr>:RuntimeError: set_storage is not allowed on a Tensor created from .data or .detach()
How can I solve this problem?

Hey @Richie-yan, in general it is not advisable to mix AMP with Horovod's native FP16 compression. I think that may be the source of the issue here.
Hey @tgaddair , One more question, the reason why it is not recommended is that there will be conflicts between the two?
Hey @Richie-yan, my understanding is that the gradients should already be compressed when using AMP when it is appropriate to do so. If you further attempt to compress them, it may not give you good results.

Does horovod support pytorch's native amp now? Are there any conflicts using both?
Hey @hiyyg, yes Horovod supports native AMP. Let us know if you run into any issues.
@tgaddair I got an error trying to use horovod with native AMP:
AssertionError: optimizer.zero_grad() was called after loss.backward() but before optimizer.step() or optimizer.synchronize(). This is prohibited as it can cause a race condition
I think it is because the gradient scaler sometimes skips the optimizer.step().
Hey @hiyyg, you need use optimizer.skip_synchronize() along with calling optimizer.synchronize() manually as shown in this example: https://gist.github.com/alsrgv/0713add50fe49a409316832a31612dde#file-pytorch_synthetic_benchmark_apex-py-L86
@tgaddair Do you mean this way if I use pytorch's native AMP?
grad_scaler.scale(losses).backward()
optimizer.synchronize()
with optimizer.skip_synchronize():
grad_scaler.step(optimizer)
grad_scaler.update()

@tgaddair Is it possible to use apex.amp or native amp with horovod along with backward_passes_per_step > 1? In the example you will have to do communication every backward, instead of every optimizer.step(). Is it possible to avoid it? Would it be correct if I did:
optimizer = hvd.DistributedOptimizer(..., backward_passes_per_step=backward_passes_per_step)
...
model, optimizer = amp.initialize(model, optimizer, opt_level="O1")
...
for i in range(backward_passes_per_step):
...
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
if i == backward_passes_per_step - 1:
optimizer.synchronize()
with optimizer.skip_synchronize():
optimizer.step()
@hiyyg Hello, have you made horovod work with pytorch native amp? I got the same ERR with you:
AssertionError: optimizer.zero_grad() was called after loss.backward() but before optimizer.step() or optimizer.synchronize(). This is prohibited as it can cause a race condition.
I can make it work with the code I posted above.