Simply implementation of ALBERT(A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS) in Pytorch. This implementation is based on clean dhlee347/pytorchic-bert code.
Please make sure that I haven't checked the performance yet(i.e Fine-Tuning), only see SOP(sentence-order prediction) and MLM(Masked Langauge model with n-gram) loss falling.
CAUTION Fine-Tuning Tasks not yet!
This contains 9 python files.
tokenization.py: Tokenizers adopted from the original Google BERT's codemodels.py: Model classes for a general transformeroptim.py: A custom optimizer (BertAdam class) adopted from Hugging Face's codetrain.py: A helper class for training and evaluationutils.py: Several utility functionspretrain.py: An example code for pre-training transformer
With WikiText 2 Dataset to try Unit-Test on GPU(t2.xlarge). You can also use parallel Multi-GPU or CPU.
$ CUDA_LAUNCH_BLOCKING=1 python pretrain.py \
--data_file './data/wiki.train.tokens' \
--vocab './data/vocab.txt' \
--train_cfg './config/pretrain.json' \
--model_cfg './config/albert_unittest.json' \
--max_pred 75 --mask_prob 0.15 \
--mask_alpha 4 --mask_beta 1 --max_gram 3 \
--save_dir './saved' \
--log_dir './logs'
cuda (1 GPUs)
Iter (loss=19.162): : 526it [02:25, 3.58it/s]
Epoch 1/25 : Average Loss 18.643
Iter (loss=12.589): : 524it [02:24, 3.63it/s]
Epoch 2/25 : Average Loss 13.650
Iter (loss=9.610): : 523it [02:24, 3.62it/s]
Epoch 3/25 : Average Loss 9.944
Iter (loss=10.612): : 525it [02:24, 3.60it/s]
Epoch 4/25 : Average Loss 9.018
Iter (loss=9.547): : 527it [02:25, 3.66it/s]
...TensorboardX : loss_lm + loss_sop.
# to use TensorboardX
$ pip install -U protobuf tensorflow
$ pip install tensorboardX
$ tensorboard --logdir logs # expose http://server-ip:6006/
-
SOP(sentence-order prediction) loss : In Original BERT, creating is-not-next(negative) two sentences with randomly picking, however ALBERT use negative examples the same two consecutive segments but with their order swapped.
is_next = rand() < 0.5 # whether token_b is next to token_a or not tokens_a = self.read_tokens(self.f_pos, len_tokens, True) seek_random_offset(self.f_neg) #f_next = self.f_pos if is_next else self.f_neg f_next = self.f_pos # `f_next` should be next point tokens_b = self.read_tokens(f_next, len_tokens, False) if tokens_a is None or tokens_b is None: # end of file self.f_pos.seek(0, 0) # reset file pointer return # SOP, sentence-order prediction instance = (is_next, tokens_a, tokens_b) if is_next \ else (is_next, tokens_b, tokens_a)
-
Cross-Layer Parameter Sharing : ALBERT use cross-layer parameter sharing in Attention and FFN(FeedForward Network) to reduce number of parameter.
class Transformer(nn.Module): """ Transformer with Self-Attentive Blocks""" def __init__(self, cfg): super().__init__() self.embed = Embeddings(cfg) # Original BERT not used parameter-sharing strategies # self.blocks = nn.ModuleList([Block(cfg) for _ in range(cfg.n_layers)]) # To used parameter-sharing strategies self.n_layers = cfg.n_layers self.attn = MultiHeadedSelfAttention(cfg) self.proj = nn.Linear(cfg.hidden, cfg.hidden) self.norm1 = LayerNorm(cfg) self.pwff = PositionWiseFeedForward(cfg) self.norm2 = LayerNorm(cfg) # self.drop = nn.Dropout(cfg.p_drop_hidden) def forward(self, x, seg, mask): h = self.embed(x, seg) for _ in range(self.n_layers): # h = block(h, mask) h = self.attn(h, mask) h = self.norm1(h + self.proj(h)) h = self.norm2(h + self.pwff(h)) return h
-
Factorized Embedding Parameterziation : ALBERT seperated Embedding matrix(VxD) to VxE and ExD.
class Embeddings(nn.Module): "The embedding module from word, position and token_type embeddings." def __init__(self, cfg): super().__init__() # Original BERT Embedding # self.tok_embed = nn.Embedding(cfg.vocab_size, cfg.hidden) # token embedding # factorized embedding self.tok_embed1 = nn.Embedding(cfg.vocab_size, cfg.embedding) self.tok_embed2 = nn.Linear(cfg.embedding, cfg.hidden) self.pos_embed = nn.Embedding(cfg.max_len, cfg.hidden) # position embedding self.seg_embed = nn.Embedding(cfg.n_segments, cfg.hidden) # segment(token type) embedding
-
n-gram MLM : MLM targets using n-gram masking (Joshi et al., 2019). Same as Paper, I use 3-gram. Code Reference from XLNET implementation.
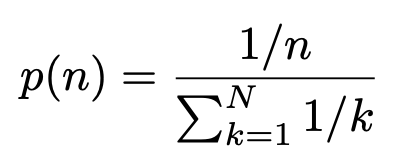

- In Paper, They use a batch size of 4096 LAMB optimizer with learning rate 0.00176 (You et al., 2019), train all model in 125,000 steps.
- Tae Hwan Jung(Jeff Jung) @graykode, Kyung Hee Univ CE(Undergraduate).
- Author Email : nlkey2022@gmail.com