sort_multiline could be improved
atsju opened this issue · comments


I think that people handwriting will drift randomly but the end of previous word will be about same height as next word. Also words cannot overlap too much in X.
Thus the line splitter should compare Y position of words that are near each other in X. The end of previous line not beeing necessarly compared with begining of previous one.
Here I have a good horizontal line but useda very small max_dist of 0.3 :
lines = sort_multiline(detections, max_dist=0.3, min_words_per_line=1)

For me line 6 and 11 could be easily computed correctly. Maybe the distance algoryhtm need to be modified in depth.

can you upload the 2nd image, so I can give it a try.
for the 1st one: the y-drift is not supported.
Here is the file

I was thinking about this tonight and why wouldn't we track distance between middle of right edge and middle of left edge to do a "line" ? This might help with slight y-drift also. Well I'm just thinking out loud. If I find something interesting I might propose a PR.
running the main.py script from the examples folder (python main.py --data path/to/img --img_height 300 --theta 5) on the image I get this output:

I can confirm this what you see. As I said,
Here I have a good horizontal line but used a very small max_dist of 0.3 :
lines = sort_multiline(detections, max_dist=0.3, min_words_per_line=1)
OK I should not have used such a small value but the result still makes me think the line splitter could be improved.
OK I should not have used such a small value but the result still makes me think the line splitter could be improved.
The result is correct, it clusters the words into 4 lines.
have you tried with with max_dist = 0.3 ?

I studied a bit the function _cluster_lines. The "problem" with this method is that tall words like aaaaa will not match well with fffff even if on same line. If the lines are correctly spaced this is the case. But when the line is sligtly drifting or near the next one it might get complex. However the code is clean and I do not have a better proposal for now.
The Jaccard (=1-intersection over union) distance is used, I would not go that low because this means that 100%-30%=70% intersection over union is needed so that two words are considered as neighbors. But the required 70% overlap is already quite a lot when you think about small and large words (like "in" (small) and "Lothringen" (large)).
You could try some other distance functions. Jaccard distance is a proper metric, but I'm not sure if this is even needed for DBSCAN clustering (check the paper for this please). You might also use information about the x-distance between words (currently only y is used).
You could also try something like this: for two words i, j, compute the minimum distance between the endpoints on the center line of the bbox (see drawing below), there are 4 possible lines, take the length of the shortest.
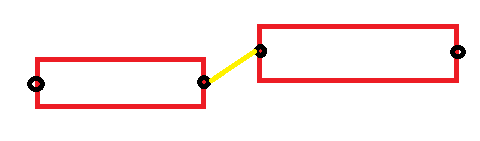
So all the "magic" happens in selecting the right distance function, and there might be ways to also support drifting lines.
You could try some other distance functions. Jaccard distance is a proper metric, but I'm not sure if this is even needed for DBSCAN clustering (check the paper for this please). You might also use information about the x-distance between words (currently only y is used).
I will let you know if I find something interesting 👍 The distance needs to be normalised for DBSCAN so I suppose the Jacquard distance choice you made is not bad.
Your proposal is exactly what I an thinking about right now. But we need to find a way to normalize this to feed it to DBSCAN. Let the night help us.
thinking out loud:
Looking on first picture (drifting line)
Or we try to take X into account to avoid 7/26 beeing matched with 7/0 and thus connecting the "7" labelled lines. Again we need a way to normalize at the end
Hi,
The distance you proposed work quite well
def my_cluster_lines(detections: List[DetectorRes],
max_dist: float = 0.7,
min_words_per_line: int = 2) -> List[List[DetectorRes]]:
# compute matrix containing Jaccard distances (which is a proper metric)
num_bboxes = len(detections)
dist_mat = np.ones((num_bboxes, num_bboxes))
for i in range(num_bboxes):
for j in range(i, num_bboxes):
a = detections[i].bbox
b = detections[j].bbox
if a.y > b.y + b.h or b.y > a.y + a.h: # no vertical overlap
dist_mat[i, j] = 9999999 # arbitrary large number
continue
dist_y = abs(a.y+a.h/2 - (b.y+b.h/2))
dist_x = min(abs(a.x - b.x), abs(a.x+a.w - b.x), abs(a.x+a.w - b.x-b.w), abs(a.x - b.x-b.w))
# give more impact on Y to split narrow lines
dist_mat[i, j] = dist_mat[j, i] = dist_x + 2*dist_y
dbscan = DBSCAN(eps=max_dist, min_samples=min_words_per_line, metric='precomputed').fit(dist_mat)
clustered = defaultdict(list)
for i, cluster_id in enumerate(dbscan.labels_):
if cluster_id == -1:
continue
clustered[cluster_id].append(detections[i])
res = sorted(clustered.values(), key=lambda line: [det.bbox.y + det.bbox.h / 2 for det in line])
return resThe only thing is that distance is not normalized anymore. Meaning the parameter max_dist must be adjusted manually to a bit more than the number of pixels between words.
I let you decide if and how you want to integrate it. Thank you for this great repo.
thanks for sharing the code, I'll have a look asap and will then decide how to integrate.