This project is a Python-based danmaku spider that is used to collect danmaku data (including danmaku content, sending time, appearance time in the video, danmaku color, and font size) on 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili.
- Make sure you have Python 3.8+ and pip installed.
- Install the required libraries using pip:
pip install -r requirements.txt
- Open the website you need to crawl, add an
ibefore the website name to jump to the API website.


-
Copy the cid on the API website.
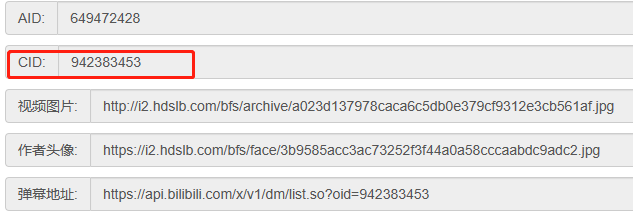
-
Paste the cid into the code in
main.py.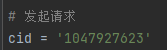
-
Run the program, and the result will be saved in
target/output.xlsx(Excel format) andtarget/output.json(JSON format)


If you find any issues or have any suggestions for improvement, please raise an issue. If you would like to contribute to the project, please fork the project and submit a pull request.
This project is open-sourced under the MIT License, see the LICENSE file for more information.