通过用户自定义词典来增强歧义纠错能力
fxsjy opened this issue · comments

你好,最近在用你的分词,发现
大连 美容美发 学校 中君 意是 你 值得 信赖 的 选择这句话被错误地切分了,我查看了dict.txt和idf.txt都没有找到“中君”和“意是”这两个词,不知道为什么>>会有这样的错分呢?
能不能从理论上解释一下?
RE:
"大连美容美发学校中君意是你值得信赖的选择" 这句话首先会按照概率连乘最大路径来切割,因为单字有一定概率,而“中君意是”这四个字中不含词典中有的词,所以会被切割成单字:
即:大连/ 美容美发/ 学校/ 中/ 君/ 意/ 是/ 你/ 值得/ 信赖/ 的/ 选择/
然后我们认为“中/ 君/ 意/ 是/ 你/ ”这几个连续的单字 中可能有词典中没有的新词,所以再用finalseg来切一遍“中君意是你 ”,finalseg是通过HMM模型来做的,简单来说就是给单字大上B,M,E,S四种标签以使得概率最大。
很遗憾,由于训练数据的问题,finalseg最终得到的标签是:
中君 意是 你
B E B E S
即认为P(B)_P(中|B)_P(E|B)_P(君|E)_P(B|E)_P(意|B)_P(E|B)_P(是|E)_P(S|E)*P(你|S) 是所有可能的标签组合中概率最大的。
B: 开头
E:结尾
M:中间
S: 独立成词的单字
解决方案是在词典中补充“君意”这个词,并给予一个词频,不用太大,比如3即可。
==user.dict===
君意 3
==test.py==
encoding=utf-8
import sys
import jieba
jieba.load_userdict("user.dict")
print ", ".join(jieba.cut("大连美容美发学校中君意是你值得信赖的选择"))
==结果===
大连, 美容美发, 学校, 中, 君意, 是, 你, 值得, 信赖, 的, 选择
Bad Case: '江州/ 市/ 长江大桥/ 参加/ 了/ 长江大桥/ 的/ 通车/ 仪式'
目前这个方面的确还比较弱。
通过在自定义词典里提高“江大桥”的词频可以做到,但是设置多少还没有公式,词频越高则成词概率越大,不宜过大。
我是这样设置的:
==user.dict==
江大桥 20000
===test1.py======
#encoding=utf-8
import sys
sys.path.append("../")
import jieba
jieba.load_userdict("user.dict")
print ", ".join(jieba.cut("江州市长江大桥参加了长江大桥的通车仪式"))
==结果===
江州, 市长, 江大桥, 参加, 了, 长江大桥, 的, 通车, 仪式

请问,在提供自定义词的时候,为什么还需要指定词频?这里的词频有什么作用?
@hitalex, 频率越高,成词的概率就越大。
比如"江州市长江大桥",既可以是”江州/市长/江大桥“,也可以是”江州/市/长江大桥“。
假设要保证第一种划分的话,我们需要保证P(江州)_P(市长)_P(江大桥)> P(江州)_P(市)_P(长江大桥)
注意 自定义词典不要用Windows记事本保存,这样会加入BOM标志,导致第一行的词被误读。

通过在自定义词典里提高“江大桥”的词频可以做到,但是设置多少还没有公式,词频越高则成词概率越大,不宜过大。这里的“不宜过大”到底不宜大到什么程度,我看前面的词频也就2,3,4,怎么到“江大桥”的词频就要大到了20000??这个难道不是过大??
@macknight , 这个例子比较极端,因为”长江大桥“、”市长“这些词的频率都很高,为了纠正,才把”江大桥“的词频设置的很高。而对于一般的词典中没有的新词,大多数情况下不会处于有歧义的语境中,故词频也就2,3,4就够了。

看到词库格式是: {word:frequency},总样本字数是多少?添加新词的频率怎么设定?
比如之前没有的词,我在5k文本中找到了"瞄星人"这个词,freq:100。 词库中怎么设置freq?
后来我又在另外10k文本中,找到了"瞄星人":30. freq怎么修改?

默认词库在这里:https://github.com/fxsjy/jieba/blob/master/jieba/dict.txt?raw=true
总样本字数??你说的是词数吧? wc -l 就好了。
一个词的举例:“一一列举 34 i”,这个词中,freq 就是 34 嘛,i 是词性。照着加进去就好。
@while,不用设置那么高。
只要能保证:
P(喵星人) =max{ P(喵)*P(星)*P(人), P(喵星)*P(人), P(喵)*P(星人), P(喵星人) }
频率设个 4 就好了。
fxsjy comment:
是的,一般不用太大, 除非是歧义纠结的句子。
2013/4/10 Sun Junyi notifications@github.com
@while https://github.com/while,不用设置那么高。
只要能保证:
P(喵星人) =max{ P(喵)_P(星)_P(人), P(喵星)_P(人), P(喵)_P(星人), P(喵星人) }—
Reply to this email directly or view it on GitHubhttps://github.com//issues/14#issuecomment-16159512
.
我想有陆续添加新词功能。 看源码里把freq取了log。 所以直接用了词频。 但是以后新的文本词频怎么整合,还想不明白?
看词库:https://github.com/fxsjy/jieba/blob/master/jieba/dict.txt?raw=true
#########
的 3188252 uj
...
龟甲 92 ns
#########
应该有个总txt长度的概念吧。
我觉得你的 comment 里,标点符号用得特别传神。
在 2013年4月10日下午3:39,whille notifications@github.com写道:
我想有陆续添加新词功能。 看源码里把freq取了log。 所以直接用了词频。 但是以后新的文本词频怎么整合,还想不明白?
—
Reply to this email directly or view it on GitHubhttps://github.com//issues/14#issuecomment-16159713
.
@whille, 如果你添加的词语特别多的话(因为会对分母造成影响),建议直接加到dict.txt里面,否则就用jieba.load_userdict好了(这里的分母还是用的dict.txt中的总词频和,为了性能并没有重新计算一遍)。

看来dict.txt里面的词频只是为解决歧义而设置的,词典中的词频数值跟计算tf-idf时没有必然联系吧?
@metalhammer666 ,没有必然联系。

在自定义词典中,明明把词性标为nr,print出来的却是x。请问怎么解决?是格式不对么?
@heloowird , 按说不会啊,把你的词典发我看看?


@fxsjy “在自定义词典中,明明把词性标为nr,print出来的却是x“
我也出现了同样的问题


我发现一个问题:我已经将某个词加入用户自定义词典,且设置了很高的词频(例如,5),但是jieba在分词或POS时,还是没有将其作为一个词。
请问,除了设置词频外,能否保证在用户词典中的词一定能够在分词过程中被认为是一个词?

还有一个问题,在中文中含有英文,如何把一个词语分到一起来?

请问自定义字典的存放路径@fxsjy
请问自定义字典的存放路径@fxsjy

请问自定义的字典里面可以有正则表达式吗?

我在添加自定义字典时,出现这个错误UnboundLocalError: local variable 'line' referenced before assignment,请问该如何解决?

@fxsjy 我想问,我在使用自定义词典的时候,分词“藏宝阁太贵”,我成功把“藏宝阁”分成一起了,但是“太贵”却不能分成“太”和“贵”。
我尝试过将jieba的字典dict.txt中的“太贵”直接删掉,也尝试过加入语句jieba.suggest_freq(('太','贵'),True),也都没有用。
请问,怎么才能成功把“太贵”分开
@codywsy 个人认为有两种方式:1)你可以在字典dict.txt中先找出“太贵”的词频,然后在后面加上“太” ,“贵”,但是词频要比“太贵”高;
2)添加自定义字典,字典里写上“太” ,“贵”,分别加词频,词频设置跟前面的方法一样

怎么结合其他输入法之类的词库??

請問Jieba有沒有辦法將英文片語分出來, 例如我要的是: "get out", 而不是"get" 和 "out" ,謝謝
再請教可以保留標點符號嗎?例如我要分的詞是"不要,停止",而不是"不要"和"停止"

您好,我发现在使用自定义词典时,我设置了A320词频为4,但我又想在有A320-200的时候分出A320-200,但即使我把A320-200的词频设置到2000,他还是会分成A320 - 200,请问这是什么原因,谢谢您!


如何强制把地名分开,比如:北京饭店 -> 北京/饭店
现在是:北京饭店连起来的

my_dict.txt
北京 4 n
饭店 4 n
jieba.set_dictionary('my_dict.txt')
print(" ".join(jieba.cut('我们来到了北京饭店')))
# 我们 来 到 了 北京 饭店

请问怎样才能又能自己定义字典又输出词性啊?
自己定义字典是用jieba.loaduserdict
输出词性用的是posseg.cut
怎样结合呢?

@fxsjy 您好,最近使用您的工具发现 “常用的数据挖掘方法包括向量机等”这句话被分成了
常用 \ 的 \ 数据挖掘 \ 方法 \ 包括 \ 向量 \ 机 \ 等
于是自己加了词典,写的是 向量机 5 n
结果分词变成了
常用 \ 的 \ 数据 \ 挖掘 \ 方法 \ 包括 \ 向 \ 量机 \ 等
数据挖掘这个词也分错了,另外向量机也没分出来
还望不吝赐教,谢谢!

@bill4mobile 请问“get out”这种问题解决了吗?我也遇到这个问题

print '/'.join( jieba.cut("谁拍板谁负责任"))
输出的是:/谁/拍板/谁/负责/任/
除了自定义词典外,如何解决这类似的错误?
@09wthe 我后来发现问题是jieba在分词时只能引用一个词典,我导入了自己的词典后jieba分词就没有使用原来的词典,之所以还能分词是因为HMM处在开启状态。
我后来直接把发现的新词加入到原词典里就没问题了。
另外我发现如果不写词频的话会报
ValueError: invalid dictionary entry
这样一个bug,似乎是字典格式要求必须有词频才可以,我试了一下,可以没有词性但必须要有词频才能不报错。
另外感谢您的指导

@fxsjy 您好,我也想问您一下,我把发现的新词添加到词典当中,还要使用标记词性的方法,请问,这时候词典起作用吗,因为我并不能分出来我添加的这些新词,分词结果和没有添加新词的时候是一样的,就是楼上呢 @SunflowerSmileYY 的问题。
@SunflowerSmileYY 您好,我想问您一下,你说那个词性标记和自定义词典的功能结合问题,你有知道方法了吗?我现在也遇到这个问题,想请教一下,能麻烦你和我讲一下吗

你好,我想问一下自定义词典中“词频省略时使用自动计算的能保证分出该词的词频。”是如何使用自动计算词频的?谢谢!

你好,我想问一下如何在词典中设置同义词呢,比如“黑色” 和 “black”?谢谢!

你好,請問我在內建詞典或自定義詞典中,加入了《海瑞罢官》這詞,但都不能分出詞。但去掉《》後加入了 海瑞罢官 就可成詞。但我的用途是一定要分出完整《海瑞罢官》這詞才成。請問有何辦法解決呢? 謝謝

你好,想问jieba有自己的对中文停用词设置的文件或方法吗

请问idf文件是如何影响分词的?

请问
使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
这个调节词频的函数是自己判断提高还是降低词频吗?如果不是,我用什么方法来告诉该函数仅仅降低词频?

jieba.suggest_freq(u'法律与秩序:特殊受害者', True)
text = u"Butt-UglyMartians法律与秩序:特殊受害者纽约重案组蝶舞天涯橙子不是唯一的水果战争风云太空堡垒"
words = jieba.cut(text, HMM=False)
print '|'.join(words)输出
Butt|-|UglyMartians|法律|与|秩序|:|特殊|受害者|纽约|重|案|组|蝶舞|天涯|橙子|不是|唯一|的|水果|战争|风云|太空|堡垒
带符号的名字被分割了, "法律与秩序:特殊受害"没有匹配出来。

您好,我想问一下一个事情,例如“很多年”,结巴分词的精准分词是分成了”很多年“,但是由于我自己的词典中是”很多“和”年“,所以我需要分成”很多“和”年“,有什么办法吗?
我尝试做了一个自定义词典解决这个问题,但是没有起作用。
@kute 您好,我用了您的方法,分词成功了,我想问一下set_dictionary和load_userdict有什么区别?

@zxqchat 请问你搞清楚了么?我想把“二手手机” 分为“二手” 和 “手机”,自定义词典后, 我用load_userdict 没有任何作用,但是用set_dictionary 就能分开了。。。

@Azusamio 看起来确实是只能用一个词典,但是我看到文档里说:
在 0.28 之前的版本是不能指定主词典的路径的,有了延迟加载机制后,你可以改变主词典的路径:
jieba.set_dictionary('data/dict.txt.big')
这样来看 set_dictionary 使用来设置主词典的,这就产生了两个问题:
- 既然有主词典,是不是还有个副词典之类的?如果有,那么如何设置呢?
- 就像 @zxqchat 所说的,
set_dictionary和load_userdict的区别是什么?我自己试了试确实是使用load_userdict加载不管用,分词的时候仍然显示加载的是默认词典。
@fxsjy 能否解释下?谢谢啦 😄

你好, 我修改了 dict.txt 中的詞頻, 希望輸出結果為 [失|明天] 而非 [失明|天]。
seg_list = jieba.cut('失明天', HMM=False) print('|'.join(seg_list))
詞頻修改為:
失明 1 N
明天 6 N
但結果還是[失明|天],
但是直接將 失明 拿掉就可以.
請問除了載入自定義辭典, 還可以怎麼解決這個問題呢?

遇到了同樣的問題,如同 @zxqchat 和 @secsilm 所说的,set_dictionary 和 load_userdict 的區別是什麽?我使用 load_userdict 加載也是不管用,分詞的時候仍然顯示的是默認詞典。
目前的解法是直接 jieba.suggest_freq(term, tune=True) 去遍歷 userdict
def handler_jieba_suggest_freq(term):
jieba.suggest_freq(term, tune=True)
# loading userdict
loading_lst = ['夏裝','原宿風','EASY SHOP','酒紅色','冷萃蘆薈'... ... ]
result = map(handler_jieba_suggest_freq,loading_lst)
for ele in result:
pass
我在添加自定义字典时,出现这个错误UnboundLocalError: local variable 'line' referenced before assignment,请问该如何解决?
这个问题应该是你在赋值前引用了line变量把,python的问题啊
@zxqchat 请问你搞清楚了么?我想把“二手手机” 分为“二手” 和 “手机”,自定义词典后, 我用load_userdict 没有任何作用,但是用set_dictionary 就能分开了。。。
@JimCurryWang @mali-nuist 已经很久没弄了,回忆了这个问题,我记得是由于词频影响的。
set_dictionary 是将自定义词典设置为分词的词典,load_userdict 是加载一个自定义词典与源词典共同构成分词的词典,假如加载的词典所定义的词频依旧低于源词典,所以就不会生效,故应当在加载的自定义词典中设置合理的词频。

你好,請問我在內建詞典或自定義詞典中,加入了《海瑞罢官》這詞,但都不能分出詞。但去掉《》後加入了 海瑞罢官 就可成詞。但我的用途是一定要分出完整《海瑞罢官》這詞才成。請問有何辦法解決呢? 謝謝
这个可以修改jieba源码中的正则表达式即可,你可以google一下


你好, 这句话 "有时候线上线下的活动需要请客户来"
分词-》 有时候 线 上线 下 的 活动 需要 请 客户 来
有什么方法可以将 线上线下 分成 线上 线下 ?
我试了几种方式都不行.......
@randyliu61 修改词频,它是按词频来决定切分的

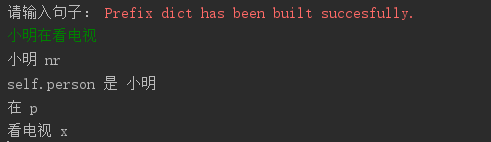
@fxsjy
原字典的看电视我删掉了,我只想分出’看‘ 和 ‘电视’,但是分出来都是x是怎么回事? 看 和 电视 的词频都很高啊一个6w 一个3k
我不想用动态调整,动态调整后也不会保存下来,每次测试都要添加一个suggest_freq太可笑了,如果要调整上千个每次弄都会死人
如果可以保存动态调整后的频率就好了,可以的话怎么做?

@fxsjy 您好,我在使用您的自定义词典功能后,程序分词的速度大幅提升,但是分词的结果其实变化并不大,变化率大概在3%左右,但是程序运行时间减到了一半,您觉得这个现象出现的原因是什么呢?希望您能解答,谢谢!

请问我用load_userdict加载了自定义词典后,还是吃 鸡,没有合并起来,如何处理呢
kute
您好,怎么成功了?
遇到了同樣的問題,如同 @zxqchat 和 @secsilm 所说的,set_dictionary 和 load_userdict 的區別是什麽?我使用 load_userdict 加載也是不管用,分詞的時候仍然顯示的是默認詞典。
目前的解法是直接 jieba.suggest_freq(term, tune=True) 去遍歷 userdict
def handler_jieba_suggest_freq(term):
jieba.suggest_freq(term, tune=True)loading userdict
loading_lst = ['夏裝','原宿風','EASY SHOP','酒紅色','冷萃蘆薈'... ... ]
result = map(handler_jieba_suggest_freq,loading_lst)
for ele in result:
pass
貌似还是不行
set_dictionary
set_dictionary怎么使用啊

请问
使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
这个调节词频的函数是自己判断提高还是降低词频吗?如果不是,我用什么方法来告诉该函数仅仅降低词频?
(我也是刚学,不保证正确:) )
应该是程序自行判断。
首先是依据什么分词的问题。分词依靠的是词频,即词典dict.txt中的词频。
我认为,不要把这个函数理解为改变词频数量的函数(虽然分词最终依靠的是词频,词频越高越能分出词),而要理解为调整是否能分词的bool开关函数。比如,原来分词时由于'台'和'中'的词频很高(FREQ('台')=16964, FREQ('中')=243191, FREQ('台中')=3),故分出的是:
>>> print('/'.join(jieba.cut('「台中」正确应该不会被切开')))
「/台/中/」/正确/应该/不会/被/切开此时使用suggest_freq,调整分出'台中'。但由于分词最终依靠的是词频,所以其实内部是修改了'台中'的词频。suggest_freq函数的返回值即修改后的词频,应该是刚好能达到分词的词频。
>>> jieba.suggest_freq('台中', True)
69为了检验,使用add_word利用此词频,一样可以分出词。
>>> jieba.add_word('台中', 69)
>>> print('/'.join(jieba.cut('「台中」正确应该不会被切开')))
「/台中/」/正确/应该/不会/被/切开
@fxsjy 我想问,我在使用自定义词典的时候,分词“藏宝阁太贵”,我成功把“藏宝阁”分成一起了,但是“太贵”却不能分成“太”和“贵”。
我尝试过将jieba的字典dict.txt中的“太贵”直接删掉,也尝试过加入语句
jieba.suggest_freq(('太','贵'),True),也都没有用。
请问,怎么才能成功把“太贵”分开
分词是以词频为中心的,不论用什么方法,最终都会归到词频。
首先说一下词频的规律:
- 词频相对越大越能分出词
- 单字的词频一般都大于双字
先举个我的例子:
对于这句话:“「台中」正确应该不会被切开”。当前词频为FREQ('台')=16964, FREQ('中')=243191, FREQ('台中')=3. 由于'台'和'中'的词频远远大于'台中',故分出的是:
>>> print('/'.join(jieba.cut('「台中」正确应该不会被切开')))
「/台/中/」/正确/应该/不会/被/切开但是,是不是只要'台'和'中'的词频大于'台中'就可以分出'台/中':
>>> jieba.add_word('台中', 69) # 此时FREQ('台中')=69
>>> print('/'.join(jieba.cut('「台中」正确应该不会被切开')))
「/台中/」/正确/应该/不会/被/切开可见不是。这是因为刚刚说过,首先,单字词频大于双字属正常现象,故此时虽然'台'和'中'的词频大于'台中',还是可以分出‘台中’。刚才又说过,词频相对越大越能分出词,故FREQ('台中')=69可以分出词,但FREQ('台中')=3时就无法分出词。
如果你要问怎么根据词频精确计算出是否能分出词,这涉及到数学知识了(截个图):

不过,对于我们使用者来说,有一种办法可以获得正好能/不能分出词的词频界限,即suggest_freq的返回值:
>>> jieba.suggest_freq('台中', True)
69
现在回到你的问题,有以下办法解决:
- 减小'太贵'的词频,有以下几种办法:
>>> jieba.add_word('太贵', 0) # 设置'太贵'词频为0,这=把字典中“太贵”直接删掉,应该是一样的,我不清楚你为什么不行
>>> print('/'.join(jieba.cut('藏宝阁太贵')))
藏宝阁/太/贵
或
>>> print(jieba.suggest_freq(('太', '贵'), True)) # 获取建议的分词词频
0
>>> print('/'.join(jieba.cut('藏宝阁太贵')))
藏宝阁/太/贵
或
>>> jieba.del_word('太贵') # 直接删除此词,相当于词频=0
>>> print('/'.join(jieba.cut('藏宝阁太贵')))
藏宝阁/太/贵
- 大幅增大'太'和'贵'的词频:
>>> jieba.add_word('太', 10000000000000)
>>> jieba.add_word('贵', 10000000000000)
>>> print('/'.join(jieba.cut('藏宝阁太贵')))
藏宝阁/太/贵
@09wthe 我后来发现问题是jieba在分词时只能引用一个词典,我导入了自己的词典后jieba分词就没有使用原来的词典,之所以还能分词是因为HMM处在开启状态。
我后来直接把发现的新词加入到原词典里就没问题了。
另外我发现如果不写词频的话会报
ValueError: invalid dictionary entry
这样一个bug,似乎是字典格式要求必须有词频才可以,我试了一下,可以没有词性但必须要有词频才能不报错。
另外感谢您的指导
不太同意您的观点,我测试了一下,只load_userdict一个含有很少词的自定义字典,同时禁用HMM,依旧可以完成文章分词。说明load_userdict是和源字典共同起作用的。
测试set_dictionary:set_dictionary一个含有很少词的自定义字典,同时禁用HMM。分词系统崩溃,除了自定义字典里的词其余都分不出来了,如图:

说明set_dictionary是设置唯一的字典。
在此印证和感谢PlayDeep的观点:
@zxqchat 请问你搞清楚了么?我想把“二手手机” 分为“二手” 和 “手机”,自定义词典后, 我用load_userdict 没有任何作用,但是用set_dictionary 就能分开了。。。
@JimCurryWang @mali-nuist 已经很久没弄了,回忆了这个问题,我记得是由于词频影响的。
set_dictionary 是将自定义词典设置为分词的词典,load_userdict 是加载一个自定义词典与源词典共同构成分词的词典,假如加载的词典所定义的词频依旧低于源词典,所以就不会生效,故应当在加载的自定义词典中设置合理的词频。

不知道能不能添加正则表达式作为新词呢?例如第1科室,第2科室,第x科室这些不想每一个都加入到自定义词典中。

@fxsjy 你好~我在词典里添加了自定义词,jieba.add_word("分°"),但是最后结果里面还是并没有把‘分’和‘°’判定为一个词,这个是为什么呢?是不支持符号和文字的为一个词的自定义分词嘛?

@aileen0823
结巴的 default 汉字里面没有你这个符号,这是个全局变量,你可以在外部改一下:
jieba.re_han_default = re.compile("([\u4E00-\u9FD5a-zA-Z0-9+#&\._%\-°]+)", re.U)
有个小小的问题,添加词典后,并没有起作用,有小伙伴遇到这样的情况吗?

import jieba
jieba.add_word('9+8')
jieba.add_word('9-8')
print('/'.join(jieba.cut('请问 9+8 9-8 的结果是多少', HMM=False)))
请问/ /9+8/ /9/-/8/ /的/结果/是/多少
请问为什么‘9+8‘能分对‘9-8’分不对呢?谢谢!

@09wthe 我后来发现问题是jieba在分词时只能引用一个词典,我导入了自己的词典后jieba分词就没有使用原来的词典,之所以还能分词是因为HMM处在开启状态。
我后来直接把发现的新词加入到原词典里就没问题了。
另外我发现如果不写词频的话会报
ValueError: invalid dictionary entry
这样一个bug,似乎是字典格式要求必须有词频才可以,我试了一下,可以没有词性但必须要有词频才能不报错。
另外感谢您的指导不太同意您的观点,我测试了一下,只load_userdict一个含有很少词的自定义字典,同时禁用HMM,依旧可以完成文章分词。说明load_userdict是和源字典共同起作用的。
测试set_dictionary:set_dictionary一个含有很少词的自定义字典,同时禁用HMM。分词系统崩溃,除了自定义字典里的词其余都分不出来了,如图:
说明set_dictionary是设置唯一的字典。
在此印证和感谢PlayDeep的观点:
@zxqchat 请问你搞清楚了么?我想把“二手手机” 分为“二手” 和 “手机”,自定义词典后, 我用load_userdict 没有任何作用,但是用set_dictionary 就能分开了。。。
@JimCurryWang @mali-nuist 已经很久没弄了,回忆了这个问题,我记得是由于词频影响的。
set_dictionary 是将自定义词典设置为分词的词典,load_userdict 是加载一个自定义词典与源词典共同构成分词的词典,假如加载的词典所定义的词频依旧低于源词典,所以就不会生效,故应当在加载的自定义词典中设置合理的词频。
同意@LinuxerAlan 的观点,如果要使用自定义词典,为了避免麻烦,可以直接set_dictionary合适的词典以及修改其中的频数
import jieba
jieba.add_word('9+8')
jieba.add_word('9-8')
print('/'.join(jieba.cut('请问 9+8 9-8 的结果是多少', HMM=False)))请问/ /9+8/ /9/-/8/ /的/结果/是/多少
请问为什么‘9+8‘能分对‘9-8’分不对呢?谢谢!
@nelsonair 可以设置一下频数,如jieba.add_word('9+8',10)
我加了以后分出来:请问/ /9+8/ /9-8/ /的/结果/是/多少

jieba 自定义词语 不一定生效..
>>> import jieba
>>> jieba.__version__
'0.42.1'
>>> text = '银行客服'
>>> list(jieba.cut(text))
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.879 seconds.
Prefix dict has been built successfully.
['银行', '客服']
>>> jieba.add_word('行客', 9999999999)
>>> list(jieba.cut(text))
['银', '行客', '服']
>>> text = '招商银行客服'
>>> list(jieba.cut(text))
['招商银行', '客服']
最后的 招商银行 一定会被分为一个词,除非 jieba.del_word('招商银行')
@fxsjy

使用自定义词典,导入词条报错,词条是法语的。支持法语分词?

词条如附件所示
Uploading user_dict.txt…