玩转进程
fengshi123 opened this issue · comments

一、背景
单线程同步编程模型会因阻塞 I/O 导致硬件资源得不到更优的使用,多线程编程模型因为线程中的死锁、状态同步等问题让开发人员头疼,并且还会因为上下文的切换,导致系统不能很好提高 CPU 的使用率。
Node 在两者之间给出方案:利用单线程,远离多线程死锁、状态同步等问题;利用 I/O,让单线程远离阻塞,以更好地使用 CPU;从严格意义上而言,Node 并非真正的单线程架构,除了 JS 运行在 V8 上,是单线程外,Node 自身还有一定的 I/O 线程存在。
二、多进程架构
并且为了弥补单线程无法利用多核 CPU 的缺点,Node 提供 child_process 模块,并且提供了 fork 方法供我们实现进程的复制。
我们通过经典的示例代码来创建 worker 进程,保存为 worker.js 文件,如下所示
const http = require('http')
http.createServer((req, res)=>{
res.writeHead(200, {'Content-Type':'text-plain'});
res.end('Hello NodeJS\n');
}).listen(Math.round((1 + Math.random()) * 1000), '127.0.0.1');然后我们将 master 进程的代码保存为 master.js 文件,如下所示
const fork = require('child_process').fork;
const cpus = require('os').cpus();
for(let i=0; i<cpus.length; i++){
fork('./worker.js')
}我们通过 node master.js 命令来启动 master 进程,其能根据 CPU 数量复制出对应 Node 进程数。在 mac 系统中我们通过 ps aux | grep worker.js 查看进程的数量,如下截图所示

以上就是著名的 Master-Worker 模式,又称 **主从模式,**其中主进程不负责具体的业务处理,而是负责调度或管理工作进程,它是趋向于稳定的,而工作进程负责具体的业务逻辑。
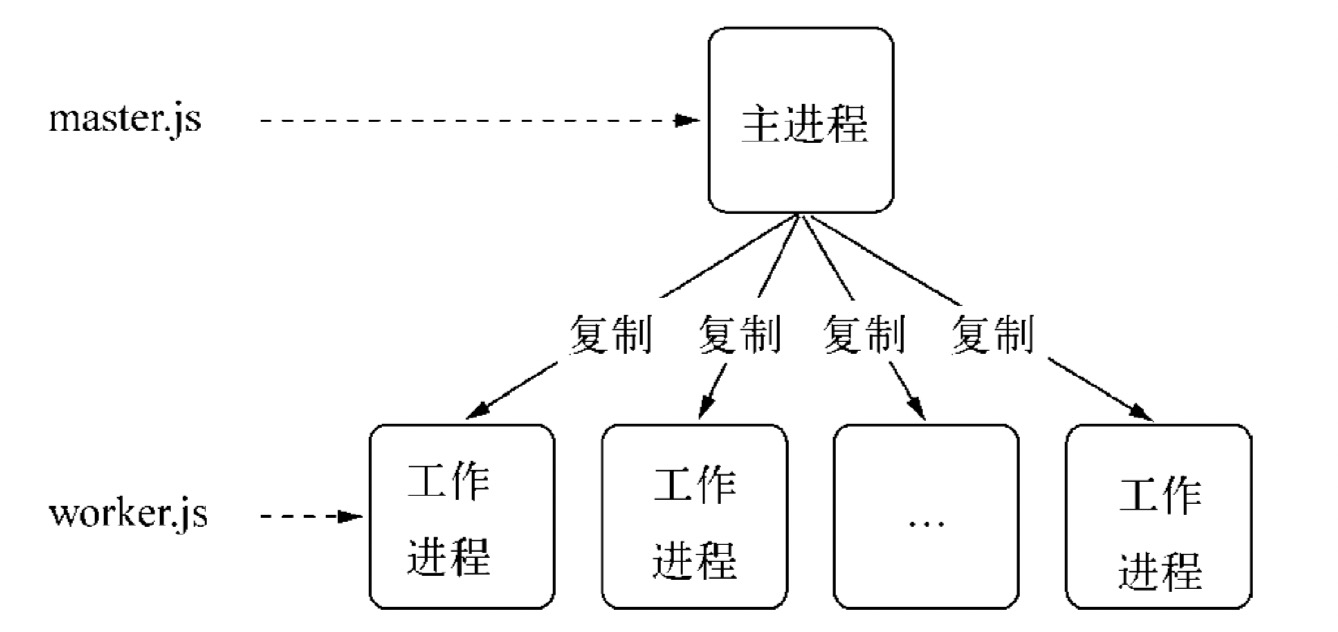
2.1、创建子进程
child_process 模块提供了以下 4 个方法用于创建子进程,并且每一种方法都有对应的同步版本:
- spawn: 启动一个子进程来执行命令;
- exec: 启动一个子进程来执行命令,与 spawn 不同的是,它有一个回调函数获知子进程的状况;
- execFile: 启动一个子进程来执行可执行文件;
- fork: 与 spawn 类似,不同点在于它创建 Node 的子进程只需指定要执行的 JavaScript 文件模块即可;
基本用法和区分点如下:
const cp = require('child_process');
// spawn
cp.spawn('node', ['./dir/test1.js'],
{ stdio: 'inherit' }
);
// exec
cp.exec('node ./dir/test1.js', (err, stdout, stderr) => {
console.log(stdout);
});
// execFile
cp.execFile('node', ['./dir/test1.js'],(err, stdout, stderr) => {
console.log(stdout);
});
// fork
cp.fork('./dir/test1.js',
{ silent: false }
);
// ./dir/test1.js
console.log('test1 输出...');差异点:
- spawn 与 exec、execFile 不同的是,后两者创建时可以指定 timeout 属性设置超时时间,一旦创建的进程运行超过设定的时间将会被杀死;
- exec 与 execFile 不同的是,exec 适合执行已有的命令,execFile 适合执行文件;
- exec、execFile、fork 都是 spawn 的延伸应用,底层都是通过 spawn 实现的;
差异列表如下:
| 类型 | 回调/异常 | 进程类型 | 执行类型 | 可设置超时 |
|---|---|---|---|---|
| spawn | 不支持 | 任意 | 命令 | 不支持 |
| exec | 支持 | 任意 | 命令 | 支持 |
| execFile | 支持 | 任意 | 可执行文件 | 支持 |
| fork | 不支持 | Node | JavaScript 文件 | 不支持 |
2.1.1、child_process.exec(command[, options][, callback])
创建一个 shell,然后在 shell 里执行命令。执行完成后,将 stdout、stderr 作为参数传入回调方法。
options 参数说明:
- cwd:当前工作路径;
- env:环境变量;
- encoding:编码,默认是 utf8;
- shell:用来执行命令的 shell,unix 上默认是 /bin/sh,windows 上默认是 cmd.exe;
- timeout:默认是 0;
- killSignal:默认是 SIGTERM;
- uid:执行进程的 uid;
- gid:执行进程的 gid;
- maxBuffer: 标准输出、错误输出最大允许的数据量(单位为字节),如果超出的话,子进程就会被杀死;默认是 200*1024(即 200k )
备注:
- 如果 timeout 大于 0,那么,当子进程运行超过 timeout 毫秒,那么,就会给进程发送 killSignal 指定的信号(比如 SIGTERM)。
- 如果运行没有出错,那么 error 为 null。如果运行出错,那么,error.code 就是退出代码(exist code),error.signal 会被设置成终止进程的信号。(比如 CTRL+C 时发送的 SIGINT)
例子 1: 基本用法
- 执行成功,error 为 null;执行失败,error 为 Error 实例;error.code 为错误码;
- stdout、stderr 为标准输出、标准错误;默认是字符串,除非 options.encoding 为 buffer;注意:stdout、stderr 会默认在结尾加上换行符;
const { exec } = require('child_process');
exec('ls', (error, stdout, stderr) => {
if (error) {
console.error('error:', error);
return;
}
console.log('stdout: ' + stdout);
console.log('stderr: ' + stderr);
})
exec('ls', {cwd: __dirname + '/dir'}, (error, stdout, stderr) => {
if (error) {
console.error('error:', error);
return;
}
console.log('stdout: ' + stdout);
console.log('stderr: ' + stderr);
})例子 2: 子进程输出/错误监听
除了例子1 中支持回调函数获取子进程的输出和错误外,还提供 stdout 和 stderr 对输出和错误进行监听,示例如下所示
const child = exec('node ./dir/test1.js')
child.stdout.on('data', data => {
console.log('stdout 输出:', data);
})
child.stderr.on('data', err => {
console.log('error 输出:', err);
})2.1.2、child_process.execFile(file[, args][, options][, callback])
跟 .exec() 类似,不同点在于,没有创建一个新的 shell,options 参数与 exec 一样;
例子 1:执行 node 文件
const { execFile } = require('child_process');
// 1、执行命令
execFile('node', ['./dir/test1.js'], (error, stdout, stderr) => {
if (error) {
console.error('error:', error);
return;
}
console.log('stdout: ' + stdout);
console.log('stderr: ' + stderr);
})例子 2:执行 shell 脚本文件
需要注意的是,我们执行 shell 脚本的时候,并没有重新开一个 shell,即:我们在根目录下运行 execFile 命令执行 ./dir/test2.sh 脚本,我们在 ./dir/test2.sh 脚本中执行与 test2.sh 同目录的 test1..js 文件,我们不能直接写成 node .test1.js 会找不到文件,应该从根目录去寻找;
注意:shell 脚本文件中如果需要访问 node 环境中的变量,可以将变量赋值给 process.env,这样在 shell 脚本中就可以通过 $变量名 进行直接访问;
const { execFile } = require('child_process');
// 2、执行 shell 脚本
// 在 shell 脚本中可以访问到 process.env 的属性
process.env.DIRNAME = __dirname;
execFile(`${__dirname}/dir/test2.sh`, (error, stdout, stderr) => {
if (error) {
console.error('error:', error);
return;
}
console.log('stdout: ' + stdout); // stdout: 执行 test2.sh test1 输出...
console.log('stderr: ' + stderr);
})
// ./dir/test2.sh
#! /bin/bash
echo '执行 test2.sh'
node $DIRNAME/dir/test1.js
// ./dir/test1.js
console.log('test1 输出...');2.1.3、child_process.fork(modulePath[, args][, options])
(1)modulePath:子进程运行的模块;
(2)args:字符串参数列表;
(3)options 参数如下所示,其中与 exec 重复的参数就不重复介绍:
- execPath: 用来创建子进程的可执行文件,默认是 /usr/local/bin/node。也就是说,你可通过 execPath 来指定具体的 node 可执行文件路径;(比如多个 node 版本)
- execArgv: 传给可执行文件的字符串参数列表。默认是 process.execArgv,跟父进程保持一致;
- silent: 默认是 false,即子进程的 stdio 从父进程继承。如果是 true,则直接 pipe 向子进程的child.stdin、child.stdout 等;
- stdio: 选项用于配置在父进程和子进程之间建立的管道,如果声明了 stdio,则会覆盖 silent 选项的设置;
例子 1:silent
const { fork } = require('child_process');
// 1、默认 silent 为 false,子进程会输出 output from the child3
fork('./dir/child3.js', {
silent: false
});
// 2、设置 silent 为 true,则子进程不会输出
fork('./dir/child3.js', {
silent: true
});
// 3、通过 stdout 属性,可以获取到子进程输出的内容
const child3 = fork('./dir/child3.js', {
silent: true
});
child3.stdout.setEncoding('utf8');
child3.stdout.on('data', function (data) {
console.log('stdout 中输出:');
console.log(data);
});2.1.4、child_process.spawn(command[, args][, options])
(1)command:要执行的命令;
(2)args:字符串参数列表;
(2)options 参数说明,其它重复的参数不在重复:
- argv0:显式地设置发送给子进程的 argv[0] 的值, 如果没有指定,则会被设置为 command 的值;
- detached:[Boolean] 让子进程独立于父进程之外运行;
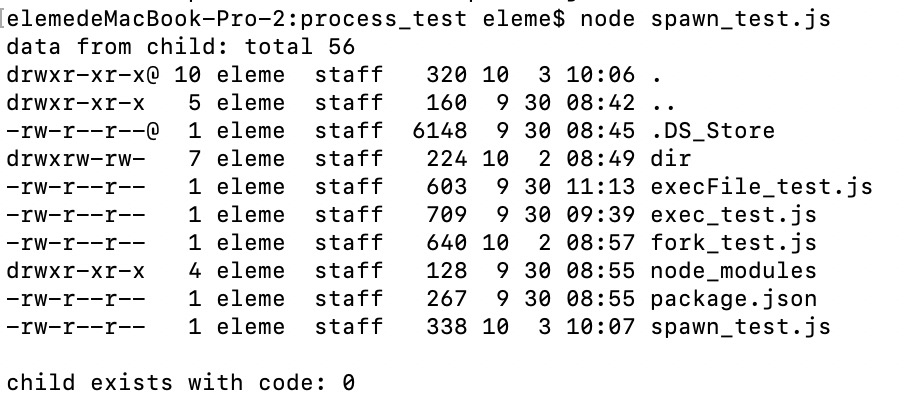
例子 1:基础例子
const spawn = require('child_process').spawn;
const ls = spawn('ls', ['-al']);
// 输出相关的数据
ls.stdout.on('data', function(data){
console.log('data from child: ' + data);
});
// 错误的输出
ls.stderr.on('data', function(data){
console.log('error from child: ' + data);
});
// 子进程结束时输出
ls.on('close', function(code){
console.log('child exists with code: ' + code);
});结果截图如下:
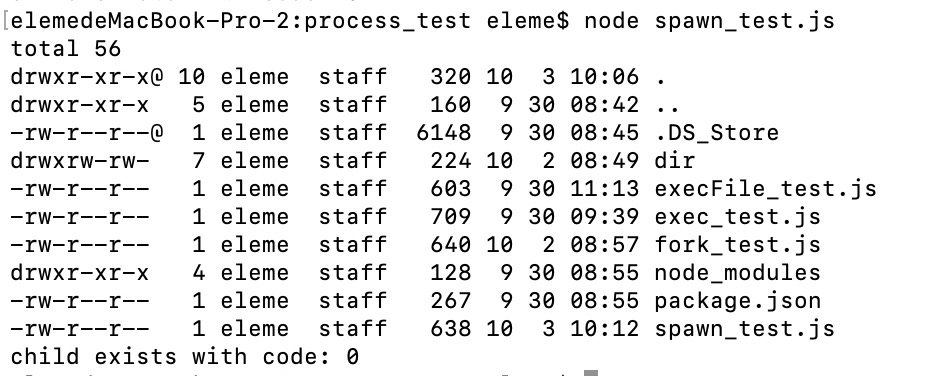
例子 2:声明 stdio
父子进程共用一个输出管道;
// 2、声明 stdio
var ls = spawn('ls', ['-al'], {
stdio: 'inherit'
});
ls.on('close', function(code){
console.log('child exists with code: ' + code);
});结果截图如下:
例子 3:错误场景
// 3、错误处理
// 3.1、场景1: 命令本身不存在,创建子进程报错
const child = spawn('bad_command');
child.on('error', (err) => {
console.log('Failed to start child process 1: ', err);
});
// 3.2、场景2: 命令存在,但运行过程报错
const child2 = spawn('ls', ['nonexistFile']);
child2.stderr.on('data', function(data){
console.log('Error msg from process 2: ' + data);
});
child2.on('error', (err) => {
console.log('Failed to start child process 2: ', err);
});2.2、进程间通信
在 Master-Worker 模式中,要实现主进程管理和调度工作进程的功能,需要主进程和工作进程之间的通信。Node 中父子进程通过 message 和 send 进行父子进程的通信,简单实例如下所示
// parent.js
const cp = require('child_process');
const child = cp.fork(__dirname + '/child.js');
child.on('message', (m)=>{
console.log('parent get message:', m);
})
child.send('hello Worker!');
// child.js
process.on('message', (m)=>{
console.log('child get message:', m);
})
process.send('hello Master!');如上,通过 fork 或其它 API 创建子进程后,父子进程之间可以通过 message 和 send 传递消息,其底层通过 IPC 通道。
IPC 的全称是 Inter-Process Communication,即进程间通信,进程间通信的目的是为了让不同的进程能够互相访问资源并进行协调工作。Node 中实现 IPC 通道的是管道(pipe)技术,具体实现由 libuv 提供,在 Windows 下由命名管道(named pipe)实现,*nix 系统则采用 Unix Domain Socket 实现。其变现在应用层上的进程间通信只有简单的 message 事件和 send 方法,使用十分简单。
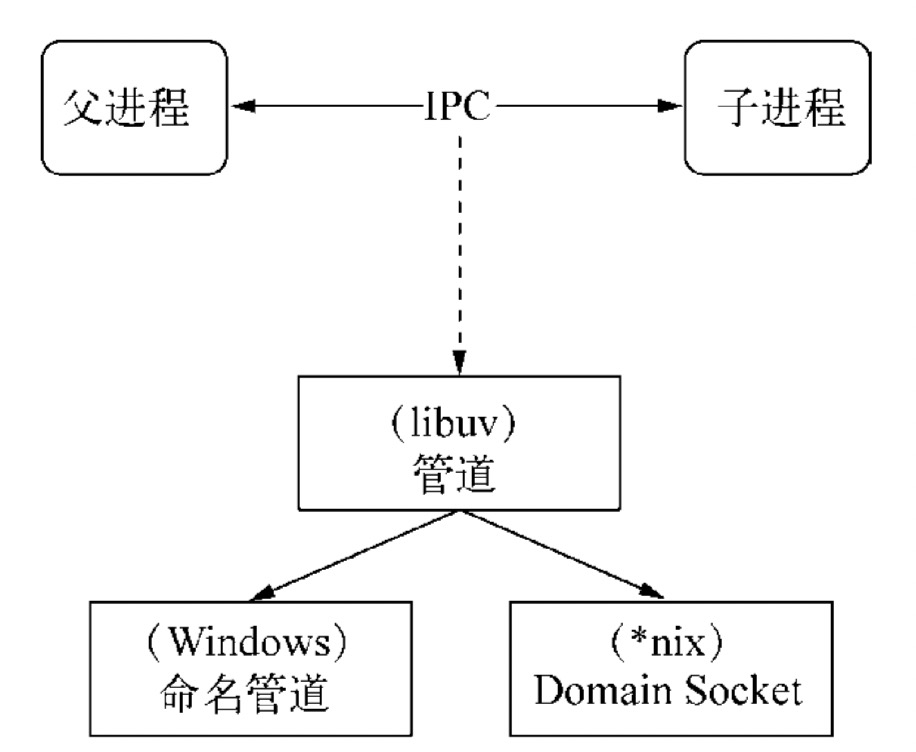
父进程在实际创建子进程之前,会创建 IPC 通道并监听它,然后才真正创建出子进程,并通过环境变量(NODE_CHANNEL_FD)告诉子进程这个 IPC 通道的文件描述符。子进程在启动过程中,根据文件描述符去连接这个已存在的 IPC 通道,从而完成父子进程之间的连接。
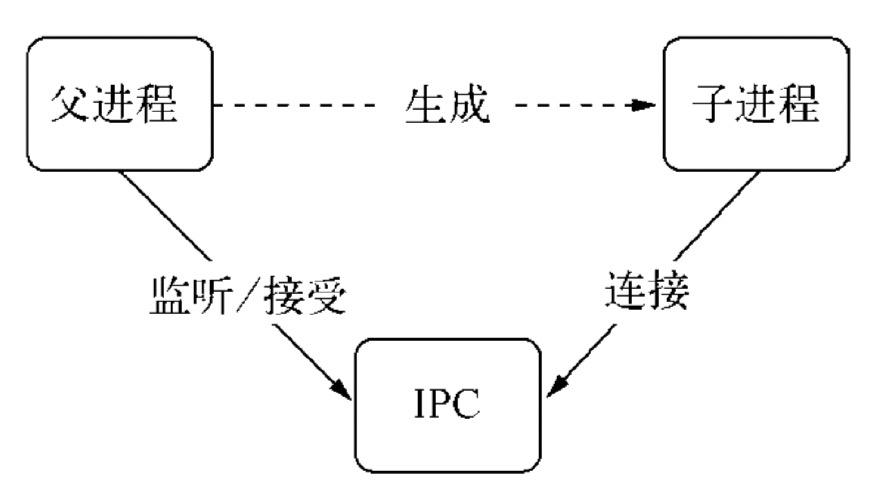
建立连接之后的父子进程就可以进行自由通信了。由于 IPC 通道是用命名管道或 Domain Socket 创建的,它们与网络 socket 的行为比较类似,属于双向通信。不同的是它们在系统内核中就完成了进程间的通信,而不用经过实际的网络层,非常高效。在 Node 中,IPC 通道被抽象为 Stream 对象,在调用 send 时发送数据(类似于 write ),接收到的消息会通过 message 事件(类似于 data)触发给应用层。
2.3、句柄传递
Node 引入进程间发送句柄的功能,send 方法除了能通过 IPC 发送数据外,还能发送句柄,第二个参数为句柄,如下所示
child.send(meeage, [sendHandle])句柄是一种可以用来标识资源的引用,它的内部包含了指向对象的文件描述符。例如句柄可以用来标识一个服务器端 socket 对象、一个客户端 socket 对象、一个 UDP 套接字、一个管道等。
那么句柄发送跟我们直接将服务器对象发送给子进程有没有什么差别?它是否真的将服务器对象发送给子进程?
其实 send() 方法在将消息发送到 IPC 管道前,将消息组装成两个对象,一个参数是 handle,另一个是 message,message 参数如下所示
{
cmd: 'NODE_HANDLE',
type: 'net.Server',
msg: message
}发送到 IPC 管道中的实际上是要发送的句柄文件描述符,其为一个整数值。这个 message 对象在写入到 IPC 管道时会通过 JSON.stringify 进行序列化,转化为字符串。子进程通过连接 IPC 通道读取父进程发送来的消息,将字符串通过 JSON.parse 解析还原为对象后,才触发 message 事件将消息体传递给应用层使用。在这个过程中,消息对象还要被进行过滤处理,message.cmd 的值如果以 NODE_ 为前缀,它将响应一个内部事件 internalMessage ,如果 message.cmd 值为 NODE_HANDLE,它将取出 message.type 值和得到的文件描述符一起还原出一个对应的对象。这个过程的示意图如下所示

这里我们提出个疑问:为何通过发送句柄,多个进程可以监听到相同的端口而不引起端口监听异常的错误?
因为独立启动的进程中,TCP 服务器端 socket 套接字的文件描述符并不相同,导致监听到相同的端口时会抛出异常。但对于 send() 发送的句柄还原出来的服务而言,它们的文件描述符是相同的,所以监听相同端口不会引起异常。
这里需要注意的是,多个应用监听相同端口时,文件描述符同一时间只能被某个进程所用,换言之就是网络请求向服务器端发送时,只有一个幸运的进程能够抢到连接,也就是说只有它能为这个请求进行服务,这些进程服务是抢占式的。
三、集群稳定之路
通过 child_process 我们可以充分利用多核 CPU 资源,但是每个工作进程依然是在单线程上执行的,它的稳定性还不能得到完全保障。
3.1、进程事件
除了 send() 方法和 message 事件外,Node 还有如下这些事件
- error: 当子进程无法被复制创建、无法被杀死、无法发送消息时会触发该事件;
- exit: 子进程退出时触发该事件,子进程如果时正常退出,这个事件的第一个参数为退出码,否则为 null。如果进程是通过 kill() 方法被杀死的,会得到第二个参数,它表示杀死进程时的信号;
- close: 在子进程的标准输入输出流中中止时触发该事件,参数与 exit 相同;
- disconnect: 在父进程或子进程中调用 disconnect() 方法触发该事件;
3.2、自动重启
基于以上的进程事件,我们能够通过监听子进程的 exit 事件来获知其退出的信息,我们在主进程上可以加入一些子进程管理的机制,比如重新启动一个工作进程来继续服务。
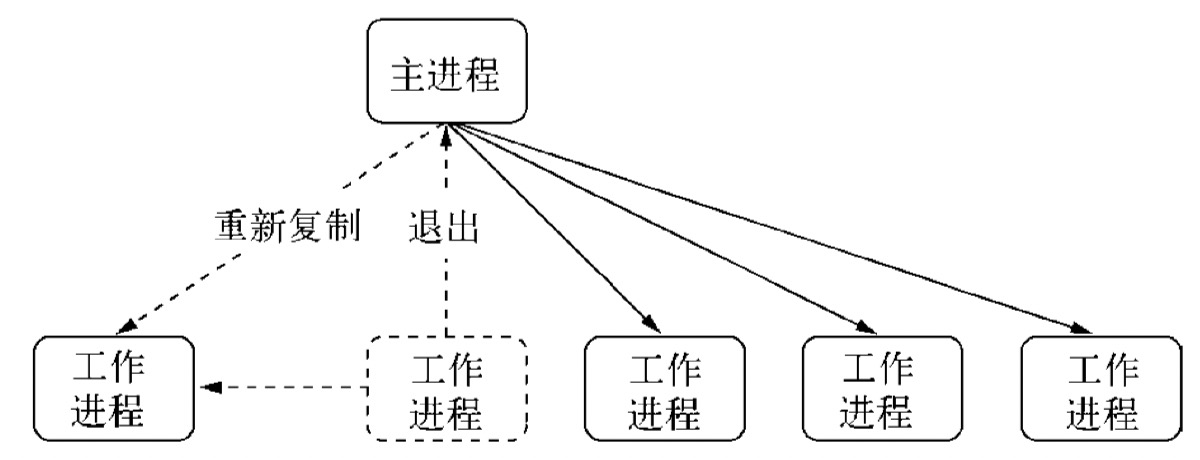
相关写法如下
// master.js
const fork = require('child_process').fork;
const cpus = require('os').cpus();
const server = require('net').createServer();
server.listen(1337);
const workers = {};
const createWorker = ()=>{
const worker = fork(__dirname + '/worker.js');
// 退出时重新启动新的进程
worker.on('exit', ()=> {
console.log('Worker' + worker.pid + ' exited.');
delete workers[worker.pid];
createWorker();
})
// 句柄转发
worker.send('server', server);
workers[worker.pid] = worker;
console.log('Create worker.pid: ' + worker.pid);
}
for(let i =0; i< cpus.length; i++){
createWorker();
}
// 进程自己退出时,让所有工作进程退出
process.on('exit', ()=>{
for(let pid in workers){
workers[pid].kill();
}
})
// worker.js
const http = require('http')
http.createServer((req, res)=>{
res.writeHead(200, {'Content-Type':'text-plain'});
res.end('handled by child, pid is ' + process.pid + '\n');
}).listen(Math.round((1 + Math.random()) * 1000), '127.0.0.1');运行以上代码,如下所示
% node ./colony/master.js
Create worker.pid: 29943
Create worker.pid: 29944
Create worker.pid: 29945
Create worker.pid: 29946
Create worker.pid: 29947
Create worker.pid: 29948
Create worker.pid: 29949
Create worker.pid: 29950当我们通过 kill 命令杀死某个进程时,如下所示
% kill 29944结果是 29944 进程退出后,自动启动了一个新的工作进程 30495,总体进程数量并没有发生改变。
Worker 29944 exited.
Create worker.pid: 30495前面我们是主动杀死一个进程,但在实际的业务中,可能有隐藏的 bug 导致工作进程退出,那我们需要处理这种异常,如下所示
// worker.js
const http = require('http')
http.createServer((req, res)=>{
res.writeHead(200, {'Content-Type':'text-plain'});
res.end('handled by child, pid is ' + process.pid + '\n');
}).listen(Math.round((1 + Math.random()) * 1000), '127.0.0.1');
const worker;
process.on('message', (m, tcp)=>{
if(m === 'server'){
worker = tcp;
worker.on('connection', (socket)=>{
server.emit('connection', socket)
})
}
})
process.on('uncaughtException', ()=>{
// 停止接收新的连接
worker.close(()=>{
process.exit(1);
})
})上述代码的处理流程是,一旦有未捕获的异常出现,工作进程就会立即停止接收新的连接,当所有的连接断开后,退出进程。主进程在侦听到工作进程的 exit 后,将会立即启动新的进程服务,以此保证整个集群中总是有进程在为用户服务的。
3.3.1、自杀信号
前面的自动重启存在问题:等到已有的所有连接断开后进程才退出,在极端的情况下,所有工作进程都停止接收新的连接,全处在等待退出的状态。所有我们需要改进这个过程,不能等到工作进程退出后才重启新的工作进程,也不能暴力退出进行,因为这样会导致已连接的用户直接断开。
我们可以在工作进程得知要退出时,向主进程发送一个自杀信号,然后才停止接收新的连接,当所有连接断开后才退出。主进程在接收到自杀信号后,立即创建新的工作进程服务。如下所示
// worker.js
process.on('uncaughtException', ()=>{
// 发送自杀信号
process.send({act: 'suicide'})
// 停止接收新的连接
worker.close(()=>{
process.exit(1);
})
})
// master.js
const createWorker = ()=>{
const worker = fork(__dirname + '/worker.js');
// 启动新的进程
worker.on('message', (message)=>{
if(message.act === 'suicide'){
createWorker();
}
})
// ...
}与前一种方案相比,创建新工作进程在前,退出异常进程在后。在异常进程退出之前,总有新的工作进程顶替它。如此,我们就完成进程的平滑重启,一旦有异常出现,主进程会创建新的工作进程来为用户服务,旧的进程一旦处理完已有连接就自动断开。这样我们的应用稳定性和健壮性大大提高。
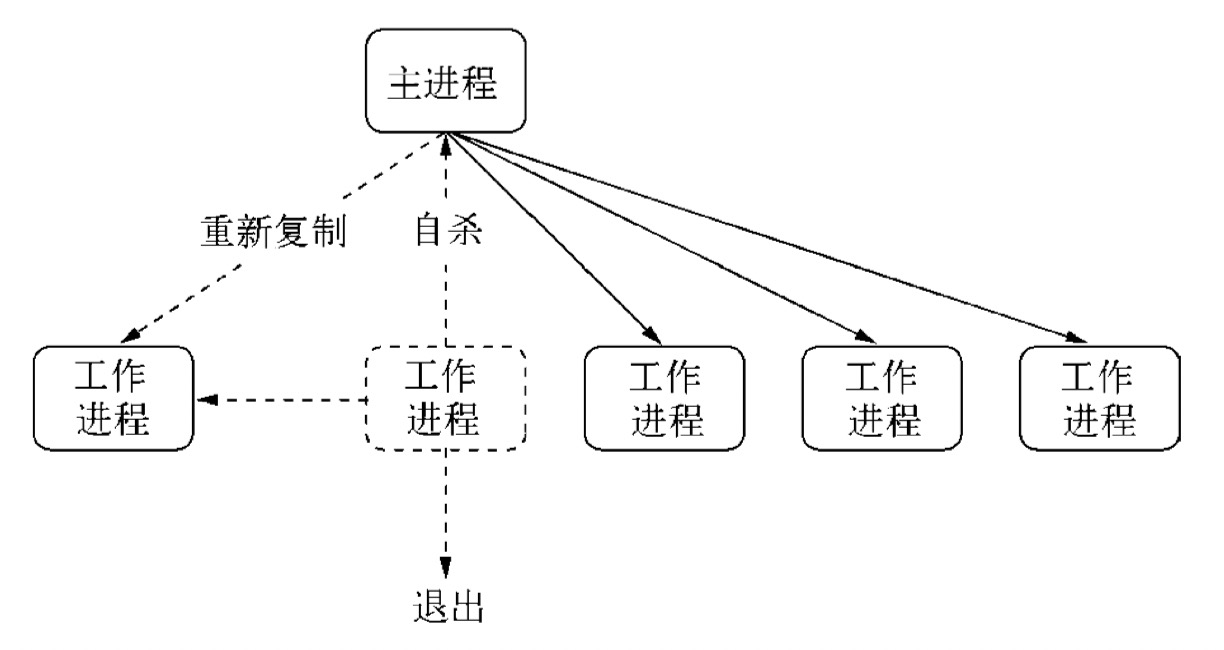
3.3.2、限定时间强制退出
如果场景不是 HTTP 这种短连接服务,而是长连接,那么等待长连接断开可能需要比较久的时间,为此,我们需要为连接的断开设置一个超时时间,在限定的时间里进行强制退出。
process.on('uncaughtException', ()=>{
// 发送自杀信号
process.send({act: 'suicide'})
// 停止接收新的连接
worker.close(()=>{
process.exit(1);
})
// 5 秒后退出进程
setTimeout(()=>{
process.exit(1)
}, 5000)
})3.3.3、异常日志收集
进程中如果出现未能捕获的异常,那意味着代码存在健壮性问题,我们需要通过日志记录下问题所在,这样便于定位和修复异常代码,如下所示
process.on('uncaughtException', (err)=>{
// 记录日志
logger.error(err);
// 发送自杀信号
process.send({act: 'suicide'})
// 停止接收新的连接
worker.close(()=>{
process.exit(1);
})
// 5 秒后退出进程
setTimeout(()=>{
process.exit(1)
}, 5000)
})3.3.4、限量重启
通过自杀信号告知主进程可以使得新连接总是有进程服务,但是依然存在极端情况。工作进程不能无限制地被重启,如果启动过程中就发了错误,会导致工作进程被频繁重启,这种频繁重启不属于我们捕获未知异常的情况。为了消除这种无意义的重启,在满足一定规则的限制下,不应当反复重启。我们可以在单位时间内规定只能重启多少次,超过限制就放弃重启工作进程。
3.3、负载均衡
在多进程之间监听相同的端口,使得用户请求能够分散到多个进程上进行处理,这带来的好处是可以将 CPU 资源都利用起来。Node 默认提供的机制是采用操作系统的抢占式策略,所谓的抢占式就是在一堆工作进程中,闲着的进程对到来的请求进行争夺,谁抢到谁服务。
对于 Node 而言,需要分清的是它的繁忙是由 CPU、I/O 两个部分构成,影响抢占的是 CPU 的繁忙度,对不同的业务,可能存在 I/O 繁忙,而 CPU 较为空闲的情况,这造成某个进程能够抢到较多请求,形成负载不均衡的情况。于是在 Node 中提供了一种新的策略使得负载均衡更合理,这种新的策略叫 Round-Robin,又叫轮叫调度。这种工作方式是由主进程接受连接,将其依次分发给工作进程。分发的策略是在 N 个工作进程中,每次选择第 i = (i + 1) mod n 个进程来发送连接。
3.4、状态共享
Node 不允许在多个进程之间共享数据,但在实际的业务中,往往需要共享一些数据,例如配置数据等,这在多个进程中应该一致的。为此,在不允许共享数据的情况下,我们需要一种方案和机制来实现数据在多个进程之间共享。
Node 提供的方案是通过第三方来进行数据储存,比如将数据存放到数据库、磁盘文件、缓存服务(如 Redis)中,所有工作进程在启动时将其读取进内存中。并且当数据发生改变时,还需要一种机制通知到各个子进程,使得它们的内部状态也得到更新。我们可以设计一种通知进程专门用来发送通知和查询状态是否更新,其不处理任何业务逻辑。
其它业务进程在启动时除了读取第一次数据外,还将进程信息注册到通知进程处,一旦通知进程轮询发现有数据更新后,根据注册信息,将更新后的数据发送给工作进程。