该资源为杨秀璋作者《Python网络数据爬取及分析从入门到精通(爬取篇)》书籍所有源代码,包括Python基础、网络爬虫基础、Urllib、BeautifulSoup、Selenium、在线百科抓取、豆瓣抓取、微博抓取等内容。所有代码已修改为Python3实现,希望对您有所帮助,一起加油。

欢迎大家去我CSDN博客留言:
最近较忙,更新中.....继续加油
"爬取篇"主要讲解Python网络数据爬取知识,如下图所示,表示爬取的基本流程及核心内容。
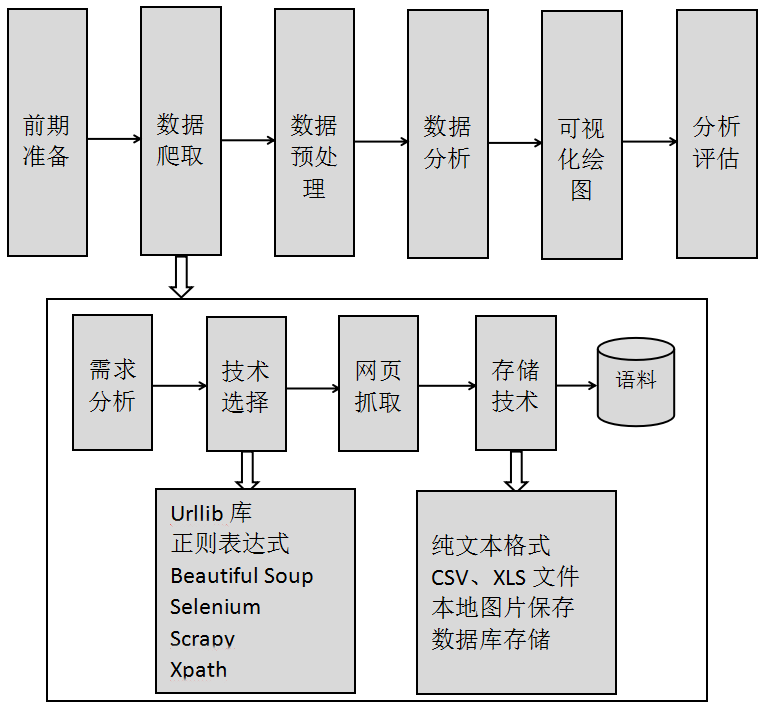
具体章节如下:
- 第1章 网络数据爬取概述
1.1 网络数据爬虫
1.2 相关技术
1.3 本章小结 - 第2章 Python知识初学
2.1 Python简介
2.2 基础语法
2.3 数据类型
2.4 条件语句
2.5 循环语句
2.6 函数
2.7 字符串操作
2.8 文件操作
2.9 面向对象
2.10 本章小结 - 第3章 正则表达式爬虫之牛刀小试
3.1 正则表达式
3.2 Python网络数据爬取的常用模块
3.3 正则表达式抓取网络数据的常见方法
3.4 个人博客爬取实例
3.5 本章小结 - 第4章 BeautifulSoup技术
4.1 安装BeautifulSoup
4.2 快速开始BeautifulSoup解析
4.3 深入了解BeautifulSoup爬虫
4.4 BeautifulSoup简单爬取个人博客网站
4.5 本章小结 - 第5章 BeautifulSoup爬取电影信息
5.1 分析网页DOM树结构
5.2 爬取豆瓣电影信息
5.3 链接跳转分析及详情页面爬取
5.4 本章小结 - 第6章 Python数据库知识
6.1 MySQL数据库
6.2 Python操作MySQL数据库
6.3 Python操作Sqlite3数据库
6.4 本章小结 - 第7章 基于数据库存储的BeautifulSoup招聘爬虫
7.1 知识图谱和智联招聘
7.2 BeautifulSoup爬取招聘信息
7.3 Navicat for MySQL工具操作数据库
7.4 MySQL数据库存储招聘信息
7.5 本章小结 - 第8章 Selenium技术
8.1 初识Selenium
8.2 快速开始Selenium解析
8.3 定位元素
8.4 常用方法和属性
8.5 键盘和鼠标自动化操作
8.6 导航控制
8.7 本章小结 - 第9章 Selenium技术爬取在线百科知识
9.1 三大在线百科
9.2 Selenium爬取维基百科
9.3 Selenium爬取百度百科
9.4 Selenium爬取互动百科
9.5 本章小结 - 第10章 基于数据库存储的Selenium博客爬虫
10.1 博客网站
10.2 Selenium爬取博客信息
10.3 MySQL数据库存储博客信息
10.4 本章小结 - 第11章 基于登录分析的Selenium微博爬虫
11.1 登录验证
11.2 初识微博爬虫
11.3 爬取微博热门信息
11.4 本章小结 - 第12章 基于图片抓取的Selenium爬虫
12.1 图片爬虫框架
12.2 图片网站分析
12.3 代码实现
12.4 本章小结 - 第13章 Scrapy技术爬取网络数据
13.1 安装Scrapy
13.2 快速了解Scrapy
13.3 Scrapy爬取贵州农产品数据集
13.4 本章小结
本书主要包括上下两册:
- 《Python网络数据爬取及分析从入门到精通(爬取篇)》 - 《Python网络数据爬取及分析从入门到精通(分析篇)》
数据爬取篇:
详细讲解了正则表达式、BeautifulSoup、Selenium、Scrapy、数据库存储相关的爬虫知识,并通过实例让读者真正学会如何分析网站,抓取自己所需的数据。
数据分析篇:
详细讲解了Python数据分析常用库、可视化分析、回归分析、聚类分析、分类分析、关联规则挖掘、文本预处理、词云分析及主题模型、复杂网络和基于数据库的分析。
上册突出爬取,下册侧重分析,强烈推荐读者两本书结合起来学习。
By:Eastmount 2021-03-14