DQN solution results peak at ~35 reward
nerdoid opened this issue · comments

Hi Denny,
Thanks for this wonderful resource. It's been hugely helpful. Can you say what your results are when training the DQN solution? I've been unable to reproduce the results of the DeepMind paper. I'm using your DQN solution below, although I did try mine first :)
While training, the TensorBoard "episode_reward" graph peaks at an average reward of ~35, and then tapers off. When I run the final checkpoint with a fully greedy policy (no epsilon), I get similar rewards.
The DeepMind paper cites rewards around 400.
I have tried 1) implementing the error clipping from the paper, 2) changing the RMSProp arguments to (I think) reflect those from the paper, 3) changing the "replay_memory_size" and "epsilon_decay_steps" to the paper's 1,000,000, 4) enabling all six agent actions from the Open AI Gym. Still average reward peaks at 35.
Any pointers would be greatly appreciated.
Screenshot is of my still-running training session at episode 4878 with all above modifications to dqn.py:


I've been seeing the same and I haven't quite figured out what's wrong yet (debugging turnaround time is quite long). I recently implemented A3C and also saw results peak earlier than they should.
The solutions share some of the code so right now my best guess is that it could be something related to the image preprocessing code or the way consecutive states are stacked before being fed to the CNN. Perhaps I'm doing something wrong there and throwing away information.
If you have time to look into that of course it'd be super appreciated.

I saw the same on a3c after 1.9 million steps:

And attributed it to the fact that I only used 4 learners (2 are hyper threads, only 2 real cores). In the paper, the training is orders of magnitude slower due to less stochasticity from fewer agents. The variance remained huge too, and it plateaus maybe too quickly in about 38 of score.
I started reviewing DQN first (though I got a high level view of how A3c is implemented too and will come back to it later), and made some dumb questions so far, as I was seeing the same level of performance.
One thing that would help diagnose performance is building the graph so we can inspect it in TensorBoard. Other than that, it could be many things. The most impactful is exactly how the backdrop is behaving, and (for me) if the Gather operation and the way the optimization is requested result in exactly what is wanted. Probably, it is, but that's where I am looking now.
Thanks for helping out.
The most impactful is exactly how the backdrop is behaving, and (for me) if the Gather operation and the way the optimization is requested result in exactly what is wanted. Probably, it is, but that's where I am looking now.
If the backprop calculation was wrong I think the model wouldn't learn at all. It seems unlikely that it starts learning but bottoms out with an incorrect gradient. Unlikely, but not impossible. It's definitely worth looking into, but it'd be harder to debug than looking at the preprocessing. A simple thing to try would be to multiply with a mask matrix (a one hot vector) instead of using tf.gather.
Adding the graph to Tensorboard should be simple. It can be passed to the saver that is created in the code, e.g. tf.train.SummaryWriter(..., sess.graph).
Thanks for the responses.
So I manually performed some environment steps and displayed their preprocessed forms. An example is below. It looks OK to me. The paper also mentions taking the max of the current and previous frames for each pixel location in order to handle flickering in some games. It seems to be unnecessary here since I didn't observe the ball disappearing between one step and the next.
I'm happy to check out the stacking code next. Looking at TensorFlow's Convolution documentation, is it possible that information is being lost by passing the state histories to conv2d as channels? Depending on how conv2d combines channel filters, maybe history is getting reduced to one state in the first convolutional layer. Maybe depthwise_conv2d is relevant or, alternatively, flattening the stack prior to feeding in to the network. I'm more comfortable with RNNs than with CNNs, so I could be off base here though :)

Depending on how conv2d combines channel filters, maybe history is getting reduced to one state in the first convolutional layer. Maybe depthwise_conv2d is relevant or, alternatively, flattening the stack prior to feeding in to the network. I'm more comfortable with RNNs than with CNNs, so I could be off base here though :)
I think you are right in that the history is being reduced to one representation after the first convolutional layer, but I think that's how it's supposed to be - You want to combine all the historic frames to create a new representation. If you used depthwise_conv2d you would never combine information across frames.
I do agree that it seems likely that something is wrong in the CNN though... It could be a missing bias term (there is no bias initializer also in the fully connected layer), wrong initializer, etc..
I just looked at the paper again:
The final hidden layer is fully-connected and consists of 512 rectifier units. The output layer is a fully-connected linear layer with a single output for each valid action.
In my code the final hidden layer does not have a ReLU activation (or bias term). Maybe that's it?
Nice catch. That does seem like it would limit the network's expressiveness. Unless you already have something running, I'll go ahead and fire up an instance and give it a shot with ReLU on the hidden fully connected layer. Can also add biases to both fully connected layers (probably initialized to zero?).
I'm not running it right now so it'd be great if you could try. In my experience the biases never helped much but adding them won't hurt. Zero-initialized should be fine.
-
I don't know how to add the graph the right way to review with TensorBoard, since at
tf.train.SummaryWriter(..., sess.graph)time the session isn't created yet (but much later). If I try to change things I'll refactor the wrong way. -
Some other things that can affect performance and that are discussed in several forums as things that have been done by the DeepMind team:
- Clipping of rewards to range (1,-1) - I think breakout not affected
- Clipping of the gradients too, to limit any one update the hard way if necessary (not sure how they do this or how real, they'd need to mess with compute gradients output.
- They consider terminal state after LOSS OF LIFE not after episode ends. This is reported to have a large impact in the learning rate and in the score you can achieve (likely, because without it, it's hard to notice for the agent that losing a life is really very bad and not "free")
- I really suspect the backprop is causing most of the trouble, and there are two potential problems with it.
The first (a) is regarding the Gather operation instead of the one_hot (that you mentioned, Danny), the second (b) is in asking the optimizer to think of vars in relation to multiple different examples (instead of vars we want fixed in general across an entire mini batch, which is usually how it will "think", that the same rules apply to the entire mini-batch).
a) The Gather operation operates very differently than a one hot. The Gather tells the optimizer to disregard completely the impact on the actions not taken as if they didn't affect the total cost. And it results in updates that disregard that we have placed a lot of effort on fine tuning the other variables because on the next state they may be the right action, and we want Q to provide a good estimate of those state, action values. But with Gather (instead of one hot) the optimizer reduces the cost in one action, without balancing the need to not change the value estimates for the other actions. So, regardless of how Gather works, a one hot is needed so that when the optimizer starts looking at the derivatives, it takes into account the other actions cost, and thus tries to find the direction which improves the current action cost (lowering it) while affecting the other action values (ie. current output value) as little as possible.
b) The other is regarding the mini-batch. I am not sure how TensorFlow mini-batch works, but it may be possible that it's not designed to have Variables corresponding to different examples within a single Batch. Another way to say it is that I think mini-batch assumes you don't change the variables to be fixed between examples within a batch, and one way to look at it is to notice how the optimizer always works across Trainable Vars, and the List of Variables that minimize takes as argument, most likely expect to be vars used across the mini match for each example. eg. you may be optimizing only x1 and not x2. But may not work if you want to optimize x1 in the first example of the batch and then x2 in the second example of the batch. This I only suspect must be so, as in many other context mini-batch is derived from a cost function that is static (not fixing vars across the batch).
I hope I am not saying something too stupid. If so apologies. Bottom line is that reward and gradient clipping (I just noticed tensorflow makes that easy to implement), ending episode when life is lost, using a one hot instead of gather, and ReLU at the final fully connected layer, may combined boost learning significantly, here, and in what may apply from here to a3c (then I care the most about).
Depending on how conv2d combines channel filters, maybe history is getting reduced to one state in the first convolutional layer. Maybe depthwise_conv2d is relevant or, alternatively, flattening the stack prior to feeding in to the network. I'm more comfortable with RNNs than with CNNs, so I could be off base here though :)
I just edited my response which was wrong. I really don't know how conv usually combines the channels. Simplest case is averaging, in cs231 hey say sum as in many other resources. The history isn't necessarily lost, and will be spread along the filters.
Unfortunately, it seems to have plateaued again. Currently at episode 3866. Here's the code I used:
fc1 = tf.contrib.layers.fully_connected(flattened, 512, activation_fn=tf.nn.relu, biases_initializer=tf.constant_initializer(0.0))
self.predictions = tf.contrib.layers.fully_connected(fc1, len(VALID_ACTIONS), biases_initializer=tf.constant_initializer(0.0))

Is something like this possible? If the action is not taken, set the target value be equal to the current Q prediction for that action. For the (one) Action taken, set the target y value be the one of our target value q(s',a'). Or does it need a one hot? If possible, then
self.y_pl is filled with the TD target we calculated (using s',a') when the index corresponds to the action taken, and all other y targets (actions not chosen) are filled with just the predicted value from self.predictions (same value in Q vs target y). Then just:
# Calcualte the loss
self.losses = tf.squared_difference(self.y_pl, self.predictions)
self.loss = tf.reduce_mean(self.losses)
Thanks for the comments. Here are a few thoughts:
Clipping of rewards to range (1,-1) - I think breakout not affected
Good point. Likely to make a difference for some of the games.
Clipping of the gradients too, to limit any one update the hard way if necessary (not sure how they do this or how real, they'd need to mess with compute gradients output.
This won't make a difference in learning ability, it'll only help you avoid exploding gradients. So as long as you don't get NaN values for your gradients this is not necessary. It's easy to add though.
They consider terminal state after LOSS OF LIFE not after episode ends. This is reported to have a large impact in the learning rate and in the score you can achieve (likely, because without it, it's hard to notice for the agent that losing a life is really very bad and not "free")
Really good point and may be the key here. This could make a huge difference. I looked at the paper again and I actually can't find details on this. Can you point me to it?
But with Gather (instead of one hot) the optimizer reduces the cost in one action, without balancing the need to not change the value estimates for the other actions. So, regardless of how Gather works, a one hot is needed so that when the optimizer starts looking at the derivatives, it takes into account the other actions cost, and thus tries to find the direction which improves the current action cost (lowering it) while affecting the other action values (ie. current output value) as little as possible.
I don't think this is right. It is correct to only take into the account the current action. Remember that the goal of the value function approximator is the predict the total value of a state action pair, q(s,a). The value of an s,a pair is completely independent of other actions in the same state. In fact, the only reason our estimator even outputs values for all actions is because it's faster. In theory you could have a separate estimator for each actions (as it is done in regular Q-Learning). You may be thinking of policy-based methods like policy gradients that predict probabilities for all actions. There we need to take into account the actions that are not taken, but not here. I'm pretty confident the current code is correct.
The other is regarding the mini-batch. I am not sure how TensorFlow mini-batch works, but it may be possible that it's not designed to have Variables corresponding to different examples within a single Batch
I'm not sure if I understand this point. Can you explain more? However, I'm pretty confident that the optimization is right.
So I think it may be worth looking at the reward structure of the environment and what they do in the original paper...
I'll try to refactor the code on the weekend to look at the gradients in Tensorboard. That should give some insight into what's going on.
Denny,
Really good point and may be the key here. This could make a huge difference. I looked at the paper again and I actually can't find details on this. Can you point me to it?
In the paper, under Methods, Training, they mention this:
For games where there is a life counter, the Atari 2600 emulator also sends the number of lives left in the game, which is then used to mark the end of an episode during training.
I've seen in some forums that they take this for granted, and they tried it in at least Breakout and it made a large difference.
SKIP THIS - It's just background on how I was confused...
Regarding the optimization, thanks for taking the time to explain. I highly appreciate it, and will sit on it and try to become more familiar with the concepts. My comment was inspired by comment by Karpathy that implemented REINFORCE.js and that in that page literally mentions under Bell & Whistles, Modeling Q(s,a):
Step 3. Forward fθ(st) and apply a simple L2 regression loss on the dimension a(t) of the output, to be y. This gradient will have a very simple form where the predicted value is simply subtracted from y. The other output dimensions have zero gradient.
But I see how I miss-read it. It confuses me a bit that having 10 outputs can be the same as having 10 networks dedicated to each action (not that both don't work, but how the 10 outputs can be as expressive).
I am also probably mixing things...such as when doing classification with softmax, we set labels for all classes, the wrong ones we send closer to 0 and the one that was right towards 1. So it trains the network to not only output something closer to one for the right label, but also trains the other labels to be closer to 0. In this case (DQN) I though similarly, that our "0" for the other actions was whatever value the function estimates (which is not relevant in the current state, but we don't want to change much because those action where not taken), thus I thought their equivalent to "0" was to set them to the value the function estimates, and the "1" was the cost we actually calculate for the action taken. I know I am still pulling my hair, ... :-)
For games where there is a life counter, the Atari 2600 emulator also sends the number of lives left in the game, which is then used to mark the end of an episode during training.
Hm, but that doesn't mean the end of an episode happens when a life is lost. It could also mean that they use the life counter to end the episode once the count reaches 0. It's a bit ambiguous. It's definitely worth trying out.
I'm having a hard time wrapping my head around the impact of ending an episode at the loss of a life considering that training uses random samples of replay memory rather than just the current episode's experience. Starting a new episode is not intrinsically punishing, is it? A negative reward for losing a life is obviously desirable though. I'd love to be wrong because this would be an easy win if it does make a difference.
On another note, I manually performed a few steps (fire, left, left) while printing out the processed state stack one depth (time step) at a time, and it checks out. The stacking code looks good to me.
@nerdoid I'm not 100% sure either, but here are some thoughts:
- Since the episode isn't ended you could potentially stack frames across lives. That doesn't seem right since there's a visual reset when you lose a life. But I agree this isn't likely to make a huge difference given that these samples from the replay memory should be pretty rate.
- Intuitively, the agent isn't punished by losing a live because it knows that it can get rewards with the next life. Imagine a scenario where you are just about to lose a life. What should be Q value be? It depends on how many lives you have left. With no lives left the value should be 0, but with multiple lives left the value should be > 0. However, the estimator doesn't have a notion of how many lives are left (it's not even in the image) so it would make sense that it becomes confused about these kind of states. It becomes an easier learning problem when the target values of states just before losing a life are set to 0.
I know it's a bit far fetched of an explanation and I don't have a clear notion of how it affects things mathematically, but it's definitely worth trying.
@fferreres I think your main confusion is that you are mixing up policy based methods (like REINFORCE and actor critic) with value-based methods like Q-Learning. In policy-based methods you do need to take all actions into account because the predictions are a probability distribution. However, in the DQN code we are not even using a softmax ;)
Just to clarify the above: By not ending the episode when a life is lost you are basically teaching the agent that upon losing the visual state is reset and it can accumulate more reward in the same episode starting from scratch. In a way you are even encouraging it to get into states that lead to a loss of life because it learns that these states lead to a visual reset, but not end of episode, which is good for getting more reward. So I do believe this can make a huge difference. Does that make sense?
Ahhh, yeah that makes a lot of sense. Thanks. I wonder then about the relative impact of doing a full episode restart vs. just reinitializing the state stack and anything else like that. Either way it's worth trying.
Although I do still have this nagging feeling that the environment could just give a large negative reward for losing a life. Is that incorrect?
Thanks. I wonder then about the relative impact of doing a full episode restart vs. just reinitializing the state stack and anything else like that.
I think the key is that the targets are set to 0 when an life is lost, i.e. this line here:
targets_batch = reward_batch + np.invert(done_batch).astype(np.float32) * discount_factor * np.amax(q_values_next, axis=1)
So when a life is lost done should be true and the env should have a full reset.
Although I do still have this nagging feeling that the environment could just give a large negative reward for losing a life. Is that incorrect?
It could. I agree this should also improve things but the learning problem would still be confusing to the estimator. The Q value (no matter if negative or positive) depends on how many lives you have left, but that information is nowhere in the feature representation.
I added a wrapper: 18528d0#diff-14c9132835285c0345296e54d07e7eb2
I'll try to run this for A3C, would be great if you could try it for Q-Learning. Crossing my fingers that this fixes it ;)
Awesome! Yes, I will give this a go for the Q-Learning in just a bit here.
@dennybritz, yeah, I have things mixed up. Too many things to try to understand too quickly (new to Python, Numpy, TensorFlow, vim, Machine Learning, RL, refresh statistics/prob 101 :-)
Not sure if either of you have encountered this yet, but when a gym monitor is active, attempting to reset the environment when the episode is technically still running results in an error with message: "you cannot call reset() unless the episode is over." Here is the offending line.
A few ideas come to mind:
- Wrap the
env.reset()call in atry/except. If we end up in theexcept, it just means we lost a life rather than finishing. Skip resetting the state stack, and instead just continue like nothing happened. Important then to move theif done: breakafter thestate = next_stateat the end of the episode loop. We still benefit from the correctdoneflag being added to replay memory in the previous step. - Start and stop the monitor every
record_video_everyepisodes. So we do the bookkeeping manually, and start the monitor only when we want to record a new video. There is probably overhead with starting and stopping the monitor repeatedly. IDK though.
The first option seems less hacky to me, but I might be overlooking something.
Here are a few threads discussing low scores vs paper. It can be a source of troubleshooting ideas:
https://groups.google.com/forum/m/#!topic/deep-q-learning/JV384mQcylo
https://docs.google.com/spreadsheets/d/1nJIvkLOFk_zEfejS-Z-pHn5OGg-wDYJ8GI5Xn2wsKIk/htmlview
I re-read all the DQN.py (not the notebook) and assuming all np slices and advanced indexing and functions operating over axis are ok, I still can't find what could be causing the score to flatten at ~35.
I think troubleshooting may be time consuming but it is also a good learning experience
Insome of the posts some mention doing a max among consecutive frames, some that the stacking is for consecutive frames I've seen a karpathy post explaining policy gradients and he did difference of frames.
This was reported regarding loss of life:
I regarded the loss of life as the terminal state but didn't reset the game, which is different from DeepMind.
Without the modification (original simple_dqn), it was 155 test score in 22 epoch in kung_fu_master.
With this modification, I got 9,500 test score in 22 epoch and 19,893 test score in 29 epoch.
Thanks for researching this. I made a bunch of changes to the DQN code on a separate branch. It now reset the env when losing a life, it writes gradient summaries and the graph to Tensorboard, and has gradient clipping: https://github.com/dennybritz/reinforcement-learning/compare/dqn?expand=1#diff-67242013ab205792d1514be55451053c
I'm re-running it now. If this doesn't "fix" it the in my opinion most likely source of error is the frame processing. Looking at the threads:
- They use a fixed frame skip in the Atari environment. OpenAI gym defaults to a random frame skip in (3, 5). It seems like you can use a
DeterministicBreakout-v0environment to get a fixed frame skip. - It seems like they max-pool the colors over 4 frames, but the gym implementation seems to just skip frames and take the last one.
- They extract luminance from the RGB data, I do grayscale (I have no idea if this is actually different)
I can't imagine that each of these makes a huge difference, but who knows. Here's the full paragraph:
Working directly with raw Atari 2600 frames, which are 2103 160
pixel images with a 128-colour palette, can be demanding in terms of computation
and memory requirements.We apply a basic preprocessing step aimed at reducing
the input dimensionality and dealing with some artefacts of the Atari 2600 emulator.
First, to encode a singlef rame we take the maximum valuefor each pixel colour
value over the frame being encoded and the previous frame. This was necessary to
remove flickering that is present in games where some objects appear only in even
frames while other objects appear only in odd frames, an artifact caused by the
limited number of sprites Atari 2600 can display at once. Second, we then extract
the Y channel, also known as luminance, from the RGB frame and rescale it to
84 x 84. The function w from algorithm 1 described below applies this preprocessing
to the m most recent frames and stacks them to produce the input to the
Q-function, in which m=4, although the algorithm is robust to different values of
m (for example, 3 or 5).
Something entirely plausible is that we didn't try "hard enough". Look for example at breakout in this page:
https://github.com/Jabberwockyll/deep_rl_ale/wiki
It remains close to 0 even at 4 million steps, then starts climbing but beed millions and millions to make a difference. Also, in many of the kearning charts there are long periods of diminishing scores, but they recover later. It takes a million sometimes to do that.
Our tries are about 2-3 millions. I may have to check the reward curves from the paper, but maybe there's nothing wrong, if the plateu is actually just the policy taking a "nap". Unfortunately, I am stuck with an Apple Air (slow). Maybe with $10 I could try a3c on a 32 cpu processor...not very familiar with aws though but a spot instance for a day would do it
I'd stick with trying DQN instead of A3C for now - there are fewer potential sources of error.
If the implementation you linked to works correctly (it seems like it does) it should be easy to figure out what the difference is:
- Reward/State Preprocessing
- Network Architecture
- Optimizer (They also used a different implementation of RMSProp)
Looking at it again there another difference from my code. They take 4 steps in the environment before making an update. I update after each step. That's not shown in the algorithm section in the paper, but it's mentioned in the appendix. So that's another thing to add.
Good point about the training time. If it takes 10M steps that's 2.5M updates (assuming you update only after 4 steps) and that'd be like 2-3 days looking at the current training speed I have on my GPU.
There's also the original DeepMind code here, although the Lua code can be less than intuitive at times :)
- They definitely don't don't train every step. That might be a fatal difference. But could also be something to keep in mind when comparing our training times with theirs, ie, they could have 1/4th the updates for the same number of steps.
- Very good to know about
DeterministicBreakout-v0as that makes it easier to reproduce their specs. - Regarding the pixel max op, they say they do that because some games flicker in the emulator. I stepped through a good 30 steps in the openai gym and never observed flickering. Could have just been lucky though if the default
Breakout-v0steps a random amount of frames. - Still a very good point about training times, especially considering that insane dip for Breakout at step 25M which might otherwise be demoralizing to observe :)
- I'm currently running an implementation very similar to:
This was reported regarding loss of life:
I regarded the loss of life as the terminal state but didn't reset the game, which is different from >>DeepMind.
Meaning I don't reset the environment. I did this because a) the gym crashes if I reset the environment when the episode isn't really over (@dennybritz I'm confused about why I'm getting that crash but you don't seem to be), and b) I'm not 100% sure it's better to actually reset the state stack with a loss of life, rather than just continuing and exposing the agent to late game states. Not sure though. Anyway, I'm running that with episode limit of 50,000, and it's averaging maybe ~50 steps per "episode", which will give a max of 2.5M steps. Which I guess is not nearly enough from the jabberwocky graphs that @fferreres linked to. Crap.
@nerdoid just set max episodes to 200k. It won't really affect anything but give more time to see how learning evolves. Also, another thing for om DQN paper is that iirc they store the best policies. This is critiziced, and not so "pure" but that's what was reporter and getting the higher scores. i.e.. for some games, after a while, they may start to "un-learn" too.
I have a limit in testing in my laptop which is 4GB (not expandable). I think I need a new laptop or rig, can't test much.

Dears
I would like to thank you all for the fruitful discussion. I have tried the A3C code and for around 1 million frames, and the performance looked fine (enhancing over time).

Regarding your discussion, I understand that the agent actually learns, but at some point it does not get any better.
My first guess would be playing with hyper parameters, mainly the learning rate should we use smaller and decaying learning rate?
Second, should the agent get punished for losing a life?
My answer would be yes (it is bad to lose life) without resetting the episode. If the agent is not punished, my guess, the learning will be slower (progressing but slower because of delayed negative reward).
Entropy, In A3C paper, it was mentioned that:
We also found that adding the entropy of the policy π to the objective function improved exploration by discouraging premature convergence to suboptimal deterministic policies .... The hyperparameter β controls the strength of the entropy regularization term.
I think β was 0.01 in the code as in the paper. However, Is it possible, for some reason, that the agent converged to suboptimal policy?
Finally, I understand that Atari 2600 and OpenAi Gym are not compatible, and results should not be compared. However the differences should be marginal not that big as we see here.
What do you think?
Thank you
the differences should be marginal not that big as we see here.
We don't know until someone trains to to 10M to 50M steps. Denny did many improvements in the dqn version and awaiting how it impacts learning.
I'm still looking into it (and training)
I think it would be good to not talk about A3C in this thread. This is about DQN, not A3C. There may be other issues with A3C that are completely unrelated to this and talking about both algorithms here is more confusing than helpful. We should make sure that DQN works first.

Hi everybody, I have been training a DQN based on Denny's code and I would like to join the debug process.
I took a look at the original code and I have one comment that may be useful in the current context:
- What I see in the code is that they train in such a way that an episode is considered to be over when the agent loses a life. However, they have a parameter called eval_freq (evaluation frequency) which determines how often do they check the performance of the current model. Moreover, when they evaluate the performance, they run eval_steps games where they do not consider losing a life as the end of the episode, and they keep adding up the received rewards until the game is over. This would mean that the scores presented in the paper may refer to the total reward received by the model when performing evaluation.
I am willing to make some experiments and check the performance of the model. I would like to know, however, how long does it usually take for you guys to train the DQN. I have been training one model for over a week already and I estimate it will need a couple of days more... If this is the case, debugging will be quite complicated XD
By the way, what do you guys mean with DeterministicBreakout-v0? I have not been able to find anything about that online...
Check out the dqn/ branch in this repo. I made some changes there, but it's not done yet. In particular, the eval is still missing. I also realized what you mentioned above about the eval, but somehow gym got stuck when evaling over multiple episodes and I couldn't get it to work. That was a while ago though, they may have fixed it by now.
If you look at the gym code you can see that they have deterministic environments, but I don't think it really matters for DQN here. Doubt that it'll make a difference.

Hi guys, I have spent a lot of time implementing my DQN code and I have solved many of the same challenges that you seem to be facing.
Right now I am crazy busy and I don't have the time to help you debug your code but I can give you some pointers of the things that are important and the things that aren't.
Also, I haven't read all of discussion or the code so I might be pointing out things that you already know. Sorry about that.
Important stuff:
- Normalise input [0,1]
- Clip rewards [0,1]
- don't tf.reduce_mean the losses in the batch. Use tf.reduce_max
- initialise properly the network with xavier init
- use the optimizer that the paper uses. It is not same RMSProp as in tf
Not really sure how important:
- They count steps differently. If action repeat is 4 then they count 4 steps for action. So divide all pertinent hyper-parameters by 4.
Little difference (at least in breakout):
- pass terminal flag when life is lost
- gym vs alewrap. Learning rate is different but If one works so will the other
I am probably missing a lot of other important titbits. If I remember anything else I will come back. But probably you will see big improvements if you implement all of this correctly.
If you have any doubts you can check out my code
Thanks a lot @cgel, I'll try to spend some time next weekend to implement these changes. The optimizer seems like quite a bit of work though so I may skip that part and hope it still works. Intuitively I can't imagine that the optimizer would explain the difference between working and not working.
I am not 100% sure how big the effect was, but I think that it was more than considerable.
Just copy the function from my repo it is in DRL/agents/commonOps.py and it is called graves_rmsprop_optimizer. It is interchangeable with the call to the tf optimizer.
Otherwise you will probably need to run a very expensive optimizer-hyper-parameter sweep.
Hey @cgel, thanks a lot for the comments. I have been checking your code and I have two basic questions:
- You said that we should pass terminal flag when life is lost, but I do not see that happening in your code. Are you also using the gym environment? Because both when training and testing, you have the following code, and you won't get a terminal flag when a life is lost, only when the game is over:
while not done:
action = agent.step(x, r)
x, r, done, info = env.step(action)
score += r
- I noticed that you use a thread for training the network which starts running when steps_before_training have been performed (nice idea by the way). This means that you do not really train the network after a fixed amount of steps, but you count on the computer to collect several experiences before the thread has finished executing the training function. Is that right?
- What I said is that passing a terminal flag when life is lost does not matter much. It will help the agent learn a bit quicker but it is not critical. And, since in gym we simply don't have the life count I decided to not use the life count. Keep in mind that I only evaluated on breakout. There might be a game for which it really does make a difference.
- I am not sure I fully understand your question. The agent collects transitions without training for
steps_before_training. Then it collects transitions and trains. My usage of multi thread is a bit messy. The objective is to have the update computation running parallel to the step in the environment. A few commits ago I simply calledupdateoncestep_count > steps_before_training.

Hi all,
if you're wondering about the optimizer that the NATURE paper used, the deep_q_rl library has a file, updates.py which uses what presumably was the correct gradient update rule, and indeed it wasn't RMSProp (@cgel is correct).
Edit: and I should add that I've run the deep_q_rl library many times and have gotten Breakout scores in the 300s-400s so something's going right. Actually, there was an issue over there in deep_q_rl that's similar to this one where the author wasn't getting the correct scores, but it looks like he/they resolved it. Part of it may have been due to gradient clipping.
-Daniel
Denny, and progress or ideas regarding these? It's a bummer emotionally - after DQN failed, I lost lot of faith in my own skills too. I can't fathom what's wrong at all.
Sorry, I've been busy with conference deadlines and haven't had time to look into this yet. Will do soon.
Awesome. I was checking some twitter posts, surely sore so much new and exciting it's almost impossible to cover everything.

@cgel Could you please elaborate a bit more on this suggestion?
don't tf.reduce_mean the losses in the batch. Use tf.reduce_max
Yes. The final scalar loss you are trying to optimise should be the sum of the individual losses of the batch (as opposed to their mean)
Dears
Any updates regarding this issue?
I wish someone else with time could help diagnose what's wrong. I know Denny is probably very busy with Language Translate stuff.
The value of this repository is that the code from Denny is very easy to follow (documented, commented) even if takes time at points. I stopped learning about RL when I couldn't figure out why DQN could not be diagnosed by anyone reading this repo, and stuck in general. I am reading slowly on new algorithms like Neural Episodic Control (https://arxiv.org/pdf/1703.01988.pdf). I take blame, in that this RL literature is fascinating, but the details and fine tuning are not for gentle on amateurs.
Any kind soul that knows what may be causing things in the DQN code, please help us get unstuck.
I should have time again to look into it starting late next week, I've been busy with another project. Thanks for all the suggestions so far.
Thank you Denny,
I think the same cause is affecting both DQN and A3C ...

@cgel I think the optimizer doesn't actually matter very much. In my own DQN implementation I just used no-brainer AdamOptimizer as usual and it's working fine.
I had the same experience that the terminal flag makes little difference.
To this issue itself, it looks like the score you're looking at is the training score (i.e. with epsilon greedy). Using greedy evaluation would improve a lot (and that's what everyone is using). When my agent gets 400 test score, the training score (with eps=0.1) is only around 70.
And btw, in evaluation, lost of life is not end of episode (unlike training).

I'm currently training DQN with some small changes mentioned by @ppwwyyxx . WIll let you know the results asap.
Btw, thanks @dennybritz for this nice repo.
No improvement. But I think it's just a misunderstanding by me.
Don't know if @dennybritz has already tried it but I changed the environment so every time a life was lost the episode should be considered finished and the environment should restart.
This is where I did wrong, because this way you are not letting the agent see advanced states of the game. So the key is to just set the reward to -1 when a life is lost and don't reset the environment, just keep playing so the agent gets to play 5 episodes per game. The key here is that every state-action pair that lead to a loss of life should get a Q value of -1. So we should still be putting a done==True to a loss of life so np.invert() can make his job but only reset the environment when env.env.ale.lives() == 0.
Next week I'll have some time to try this out and will let you know. Maybe it's not the root cause of the problem but I though it might be worth sharing it in case it can help someone or give some ideas.
Let's fix this once and for all between all of us ;)
If someone gets to try this please let us know :)
@ppwwyyxx I have not run an extensive optimizer search but in my experience DQN is very sensitive to it. Regarding what epsilon should you use, the original DQN used 0.1 for the training and 0.05 the testing. The numbers that you give seem a bit strange to me. When I see a testing score > 300 the training score is > 150.
@ered you are right in saying that you should not reset the environment but you seem to be over complicating the solution. There is no reason for the Q value of a life lost being -1, it should be 0. The easiest solution is to pass a terminal flag to the agent and keep the game running. But again, I have already tried it and it barely made any difference.

Marking loss of life as termination of the game can bring big improvement in some game (at least in SpaceInvader as I tested). I think the intuition is that, if not, the q-value for the same state under different number of lives should be different but the agent cannot differentiate this difference given only the raw pixel input. In spaceinvader, this can increase the score from ~600 to ~2000 with other variates controlled.

@dennybritz Hi, I think I met the same problem as you, I tried in Open AI Gym baseline BreakoutNoFrameskip-v4, and the reward converges to around 15[In DQN nature paper, it's around 400]. Did you figure out the problem, if possible, pease give me some suggestion about this.


I've found more success with ACKTR than with Open AI's deepq stuff. Here's a video of it getting 424: breakout. This wasn't an especially good score, it was just a random run I recorded to show a friend. I've seen it win the round and score over 500.

@dennybritz firstly, thank you for creating this easy to follow DeepRL repo. I've been using it as a reference to code up my own DQN implementation for Breakout in PyTorch. Is the current avg_score that the agent is achieving still saturating around 30? In your dqn implementation the Experience Replay buffer has a size=500,000 right, I feel that the size of the Replay is very critical to replicating DeepMind's performance on these games. would like to hear your thoughts on this? Have you tried increasing Replay size to 1,000,000 as suggested in the paper?

Wonder if anyone is still following this post.
DQN is very sensitive to your optimizer, and your random seed. Shown below is 4 runs with same setting.
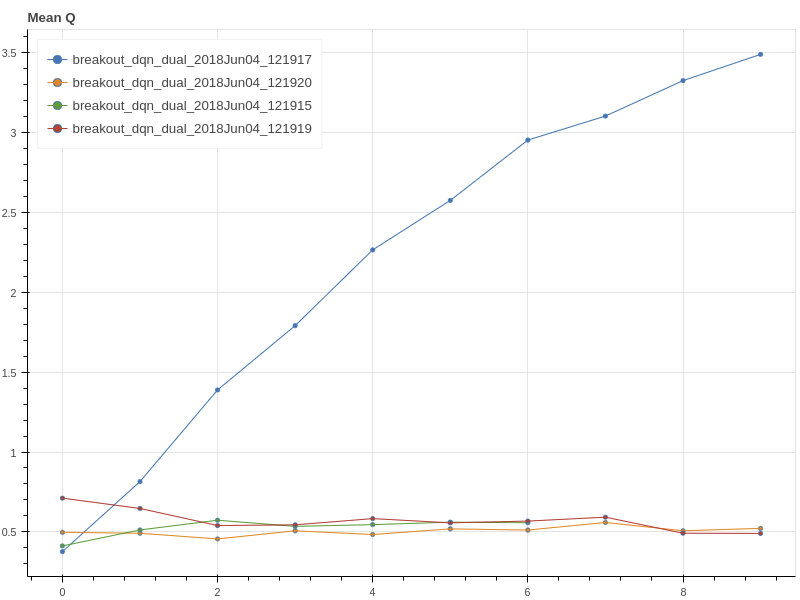

It is very hard to find a good optimizer as below one:


This one use Adagrad: lr=0.01, epsilon = 0.01 (You need to change adagrad.py for pytorch for this optimizer). It is strange that, use rmsprop: lr=0.01, epsilon=0.01, decay=0, momentum=0, which according to source code is exactly the same, but it will be simply not working. Same for Adam. Good luck to your RL research.
DQN is very sensitive to your optimizer, and your random seed
... in certain implementation and certain tasks.
Breakout is in fact very stable given a good implementation of either DQN or A3C. And DQN is also quite stable compared to policy-based algorithms like A3C or PPO.
@ppwwyyxx Notice in your implementation:
gradproc.GlobalNormClip(10)This may be very important ....
Actually, PPO and TRPO could be regarded as gradient clip which makes it stable.
IIRC that line of code has no visible effect on training breakout as the gradients are far from large enough to reach that threshold. I'll remove it.
@ppwwyyxx I tried Adam optimizer with epsilon=1e-2 same as your setting, it works.

I tested with the gym environment Breakout-v4 and found that the env.ale.lives() will not change instantly after losing a life (i.e. the ball disappears from the screen). Instead, the value will change roughly 8 steps after a life is lost. Could somebody verify what I said? If this is true, then the episode will end (according to whether a life is lost) at a fake terminal state that is 8 steps after the true terminal state. This is probably one reason why DQN using gym Atari environment cannot get high enough scores.

I've done a brief search over RMSProp momentum hyperparameters and I believe it could be the source of the issue.
I ran three models for 2000 episodes each. The number of frames varies based on the length of the episodes in each test. For scale, the red model ran for around 997,000 frames while the other two ran for around 700k.
The momentum values were as follows:
dark blue - 0.0
red - 0.5
light blue - 0.9
Because red performed best at 0.5, I will run a full training cycle and report back with my findings.

It seems strange to use a momentum value of 0.0 while the paper uses 0.95. However, I feel the logic here could be that momentum doesn't work well on a moving target but I haven't seen hard evidence of this being the case.

@fuxianh I met the same problem as you when running the DQN code from Open AI Gym baseline on BreakoutNoFrameskip-v4. Have you solved this problem and could you share the experiences?Thank you very much!

hey guys,
I've been working on implementing my own version of DQN recently and I encountered the same problem: the average reward (over the last 100 rounds in my plot) peaked at around 35 for Breakout.
I used Adam with a learning rate of 0.00005 (see blue curve in the plot below). Reducing the learning rate to 0.00001 increased the reward to ~50 (see violet curve).
I then got the reward to > 140 by passing the terminal flag to the replay memory when a life is lost (without resetting the game), so it does make a huge difference also for Breakout.

Today I went over the entire code again, also outputting some intermediate results. A few hours later at dinner it struck me that I saw 6 Q values this morning while I had the feeling that it should be 4.
A quick test confirms that for BreakoutDeterministic-v3 the number of actions env.action_space.n is 6:
NOOP, FIRE, RIGHT, LEFT, RIGHTFIRE, LEFTFIRE
Test this with env.unwrapped.get_action_meanings()
DeepMind used a minimal set of 4 actions:
PLAYER_A_NOOP, PLAYER_A_FIRE, PLAYER_A_RIGHT, PLAYER_A_LEFT
I assume that this subtle difference could have a huge effect, as it alters the tasks difficulty.
I will immediately try to run my code with the minimal set of 4 actions and post the result as soon as I know :)
Fabio
I recently implemented DQN myself and initially encountered the same problem: The reward reached a plateau at around 35 in the Breakout environment.
I certainly found DQN to be quite fiddly to get working. There are lots of small details to get right or it just doesn't work well but after many experiments, the agent now reaches an average training reward per episode (averaged over the last 100 episodes) of ~300 and an average evaluation reward per episode (averaged over 10000 frames as suggested by Mnih et al. 2013) of slightly less than 400.
I commented my code (in a single jupyter nb) as best as I could so that it hopefully is as easy as possible to follow along if you are interested.

Opposed to previous posts in this thread I also did not find dqn to be very sensitive to the random seed:

My hints:
-
Use the right initializer! The dqn uses the Relu activation function and the right initializer is He.
https://www.youtube.com/watch?v=s2coXdufOzE&t=157s
In tensorflow usetf.variance_scaling_initializerwithscale = 2 -
I found that Adam works fairly well so before implementing the RMSProp optimizer DeepMind used (not the same as in TensorFlow) I would try to get it to work with Adam. I used a learning rate of 1e-5. In my experiments larger learning rates had the effect that the reward plateaued at around 100 to 150.
-
Make sure you are updating the networks in the right frequency: The paper says that the target network update frequency is "measured in the number of parameter updates" whereas in the code it is measured in the number of action choices/frames the agent sees.
-
Make sure that your agent is actually trying to learn the same task as in the DeepMind paper!!!
4.1) I found that passing the terminal flag to the replay memory, when a life is lost, has a huge difference also in Breakout. This makes sense since there is no negative reward for losing a life and the agent does "not notice that losing a life is bad".
4.2) DeepMind used a minimal set of 4 actions in Breakout, several versions of open ai gym's Breakout have 6 actions. Additional actions can alter the difficulty of the task the agent is supposed to learn drastically! The Breakout-v4 and BreakoutDeterministic-v4 environments have 4 actions (Check withenv.unwrapped.get_action_meanings()). -
Use the Huber loss function, the Mnih et al 2013 paper called this error clipping.
-
Normalize the input to the interval [0,1].
I hope you can get it to work in your own implementation, good luck!!
Fabio

Has anyone solved this problem for denny's code?

Is there anything to do to solve the problem? Should we use the deterministic environment, like 'BreakoutDeterministic-v4' and should we change the optimizer from RMSprop to Adam since it seem s that DeepMind change to using Adam in their rainbow paper.
If you want to try to improve Denny's code, I suggest you start with the following:
-
Use Adam and a learning rate of 0.00001. DeepMind used 0.0000625 in the Rainbow paper for all the environments. I don't think that RMSProp is the problem in Denny's code in general but maybe the learning rate is not right and I can confirm that Adam with 0.00001 works well in Breakout.
-
Make sure that the terminal flag is passed when a life is lost!
-
Use the tf.variance_scaling_initializer with scale = 2, not Xavier (I assume the implementation uses RELU as activation function in the hidden layers like in the DeepMind papers?!).
-
Does the implementation put 1 million transitions into the replay memory or less?
-
I don't think the "Deterministic" matters that much atm...
-
Make sure you are updating the networks in the right frequency (see my previous post).
Keep us updated, if you try these suggestions :)

From what I can see, this behavior might be due to the size of replay memory used. Replay memory plays a very critical role in the performance of DQN (read extended table-3 of the original paper https://daiwk.github.io/assets/dqn.pdf).
I also implemented DQN (in Pytorch) with replay memory size of 80,000. After training the model for 12000 episodes (more than 6.5 M steps), it could only reach the evaluation score of around 15. So, my guess is that Denny's code might also be having the same problem.
For those who have seen/solved this or similar issues, it would be great if you can shed some light on whether you observed the same behavior.

Hello everyone, interesting thread here.
I would like some help to clarify my confusion here:
- We have agreed on (confirmed by the DQN nature paper) that during training, whenever a life is lost (even if the agent still has more lives left), we would send a terminal tag to the DQN (which terminates the summation of Q values to be just including the reward at last step for the state leading towards the life lost). Is this correct?
- Also during training, after losing a life and sending the terminal tag, we would however still carry on with the agent using its remaining lives, rather than resetting the game. This is beneficial since the agent will go deeper into the game, and will see more advanced game states. Is this correct?
- The question: when evaluating the agent playing the game, how are the reward results computed as they present in DQN papers?
3.1 Are they just summing up the rewards over a single life, or over all lives? They mentioned "episodic rewards" in testing, is the term "one episode" meaning just "one life"?
3.2 If that's indeed the case (the rewards reported in testing are just summed over a single life), then during testing, after a life is lost, do they reset the environment, or let the agent to use remaining lives for obtaining more "episodic rewards", as separate trials of results to be averaged or compared for max?
Thanks a lot if anyone can confirm on this!

Hello. I have tried many different things before, including changing the optimizer to what the paper has said, or preprocess the frames as closs as possible to the paper did, but still has a low value. The key thing I found is set "done" flag after every time the agent loses its life. This is super important. I have some benchmark results in https://github.com/wetliu/dqn_pytorch. Thank you for the help in this thread. I deeply appreciate it!

Sorry for reviving this thread again, but did anyone figure out what the issue was? I'm attempting the same task (Breakout) and my train reward is stuck at 15-20 at 10M steps. I'm using a replay buffer of 200k, 4 gradient updates per iteration, 5e-4 as the learning rate.
Also using the He initializer as @fg91 mentioned in his comment, DDQN and all other optimizations mentioned as well. I'm not sure if I'm doing it wrong or I just need to wait to train it more.
@GauravBhagchandani The key thing I found is set "done" flag after every time the agent loses its life. This is super important.
@wetliu Thanks for the reply! I have done that as well, hasn't made much of a difference. It's such a pain because the training takes so long for any small change. Do you know how many steps are needed to reach at least 100+ on the train score?
@GauravBhagchandani I have tried a bunch of environments after that update and can successfully train the models with less steps reported in the paper. You can refer the code here https://github.com/wetliu/dqn_pytorch.
I got past the 20 train reward barrier. I was using SGD as the optimizer with 0.9 as the momentum. I switched to Adam with an epsilon of 1e-4 and that seemed to do the trick for me. It's currently training but I'm at 6.7M samples so far with train rewards around 30-40 and test up to 300. Currently, the model gets stuck after it tunnels through and breaks a lot of the blocks. It just stops moving. I think that'll get resolved as it trains more.

Update: It plateaued at 30-40 for even 20M steps. I'm a bit lost now on what to do to fix this. It's really annoying.
@wetliu Is there any chance I could show you my code and get some guidance?