- SSH access in most workspaces is not allowed any more
- Jupyter features like
ipywidgetsare now supported in Databricks Notebooks
This package allows to connect to a remote Databricks cluster from a locally running JupyterLab.
- Support of Databricks Runtimes 6.4(ESR) and 7.3, 7.6, 8.0, 8.1, 8.2, 8.3 (both standard and ML)
- Upgrade to ssh_ipykernel 1.2.3 (security fixes for the Javascript Jupyterlab extension of ssh_ipykernel)
- Security fixes for the Javascript Jupyterlab extension of databrickslabs-jupyterlab

-
Operating System
Jupyterlab Integration will run on the following operation systems:
- macOS
- Linux
- Windows 10 (with OpenSSH)
-
Anaconda
JupyterLab Integration is based on Anaconda and supports:
- A recent version of Anaconda with Python >= 3.8
- The tool conda must be newer than 4.7.5, test were executed with 4.9.2.
Since Jupyterlab Integration will create a separate conda environment, Miniconda is sufficient to start
-
Python
JupyterLab Integration only works with Python 3 and supports Python 3.7 and Python 3.8 both on the remote cluster and locally.
-
Databricks CLI
For JupyterLab Integration a recent version of Databricks CLI is needed. To install Databricks CLI and to configure profiles for your clusters, please refer to AWS / Azure.
Note:
- JupyterLab Integration does not support Databricks CLI profiles with username password. Only Personal Access Tokens are supported.
- Whenever
$PROFILEis used in this documentation, it refers to a valid Databricks CLI profile name, stored in a shell environment variable.
-
SSH access to Databricks clusters
Configure your Databricks clusters to allow ssh access, see Configure SSH access
Note:
- Only clusters with valid ssh configuration are visible to
databrickslabs_jupyterlab.
- Only clusters with valid ssh configuration are visible to
-
Databricks Runtime
JupyterLab Integration has been tested with the following Databricks runtimes on AWS and Azure:
- '6.4 (ESR)'
- '7.3' and '7.3 ML'
- '7.6' and '7.6 ML'
- '8.0' and '8.0 ML'
- '8.1' and '8.1 ML'
- '8.2' and '8.2 ML'
- '8.3' and '8.3 ML'
Newer runtimes might work, however are subject to own tests.
A docker image ready for working with Jupyterlab Integration is available from Dockerhub. It is recommended to prepare your environment by pulling the repository: docker pull bwalter42/databrickslabs_jupyterlab:2.2.1
There are two scripts in the folder docker:
- for Windows:
dk.dj.batanddk-jupyter.bat - for macOS/Linux:
dk-djanddk-jupyter
Alternatively, under macOS and Linux one can use the following bash functions:
-
databrickslabs-jupyterlab for docker:
This is the Jupyterlab Integration configuration utility using the docker image:
function dk-dj { docker run -it --rm -p 8888:8888 \ -v $(pwd)/kernels:/home/dbuser/.local/share/jupyter/kernels/ \ -v $HOME/.ssh/:/home/dbuser/.ssh \ -v $HOME/.databrickscfg:/home/dbuser/.databrickscfg \ -v $(pwd):/home/dbuser/notebooks \ bwalter42/databrickslabs_jupyterlab:2.2.1 /opt/conda/bin/databrickslabs-jupyterlab $@ }
-
jupyter for docker:
Allows to run jupyter commands using the docker image:
function dk-jupyter { docker run -it --rm -p 8888:8888 \ -v $(pwd)/kernels:/home/dbuser/.local/share/jupyter/kernels/ \ -v $HOME/.ssh/:/home/dbuser/.ssh \ -v $HOME/.databrickscfg:/home/dbuser/.databrickscfg \ -v $(pwd):/home/dbuser/notebooks \ bwalter42/databrickslabs_jupyterlab:2.2.1 /opt/conda/bin/jupyter $@ }
The two scripts assume that notebooks will be in the current folder and kernels will be in the kernels subfolder of the current folder:
$PWD <= Start jupyterLab from here
|_ kernels
| |_ <Jupyterlab Integration kernel spec>
| |_ ...
|_ project
| |_ notebook.ipynb
|_ notebook.ipynb
|_ ...
Note, the scripts dk-dj / dk-dj.bat will modify your ~/.ssh/config and ~/.ssh/know_hosts!
If you you do not want this to happen, you can for example extend the folder structure to
$PWD <= Start jupyterLab from here
|_ .ssh <= new
| |_ config <= new
| |_ id_$PROFILE <= new
| |_ id_$PROFILE.pub <= new
|_ kernels
| |_ <Jupyterlab Integration kernel spec>
| |_ ...
|_ project
| |_ notebook.ipynb
|_ notebook.ipynb
|_ ...
and create the necessary public/private key pair in $(pwd)/.ssh and change the parameter
-v $HOME/.ssh/:/home/dbuser/.ssh to -v $(pwd)/.ssh/:/home/dbuser/.ssh
in both commands.
-
Install Jupyterlab Integration
Create a new conda environment and install databrickslabs_jupyterlab with the following commands:
(base)$ conda create -n dj python=3.8 # you might need to add "pywin32" if you are on Windows (base)$ conda activate dj (dj)$ pip install --upgrade databrickslabs-jupyterlab[cli]==2.2.1The prefix
(db-jlab)$for all command examples in this document assumes that the conda enviromnentdb-jlabis activated. -
The tool databrickslabs-jupyterlab / dj
It comes with a batch file
dj.batfor Windows. On MacOS or Linux bothdjanddatabrickslabs-jupyterlabexist
Ensure, ssh access is correctly configured, see Configure SSH access
-
Create a kernel specification
In the terminal, create a jupyter kernel specification for a Databricks CLI profile
$PROFILEwith the following command:-
Local installation
(db-jlab)$ dj $PROFILE -k -
With docker
(db-jlab)$ dk-dj $PROFILE -k
A new kernel is available in the kernel change menu (see here for an explanation of the kernel name structure)
-
-
Start JupyterLab
-
Local installation
(db-jlab)$ dj $PROFILE -l # or 'jupyter lab'
-
With docker
(db-jlab)$ dk-dj $PROFILE -l # or 'dk-jupyter lab'
The command with
-lis a safe version for the standard command to start JupyterLab (jupyter lab) that ensures that the kernel specificiation is updated. -
-
Check whether the notebook is properly connected
When the notebook connected successfully to the cluster, the status bar at the bottom of JupyterLab should show

if you use a kernel with Spark, else just

If this is not the case, see Troubleshooting
-
Test the Spark access
To check the remote Spark connection, enter the following lines into a notebook cell:
import socket from databrickslabs_jupyterlab import is_remote result = sc.range(10000).repartition(100).map(lambda x: x).sum() print(socket.gethostname(), is_remote()) print(result)
It will show that the kernel is actually running remotely and the hostname of the driver. The second part quickly smoke tests a Spark job.
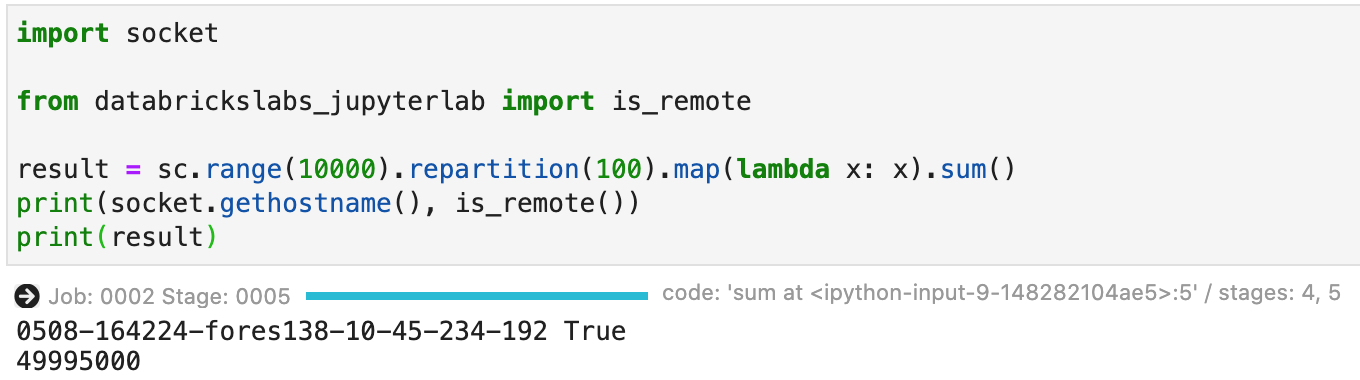



Success: Your local JupyterLab is successfully contected to the remote Databricks cluster
7.1 Switching kernels and restart after cluster auto-termination
7.2 Creating a mirror of a remote Databricks cluster
7.3 Detailed databrickslabs_jupyterlab command overview
Please note that all projects in the /databrickslabs github account are provided for your exploration only, and are not formally supported by Databricks with Service Level Agreements (SLAs). They are provided AS-IS and we do not make any guarantees of any kind. Please do not submit a support ticket relating to any issues arising from the use of these projects.
Any issues discovered through the use of this project should be filed as GitHub Issues on the Repo. They will be reviewed as time permits, but there are no formal SLAs for support.
To work with the test notebooks in ./examples the remote cluster needs to have the following libraries installed:
- mlflow==1.x
- spark-sklearn