0x31_LinuxKernel_内存管理(一)物理页面、伙伴系统和slab分配器
carloscn opened this issue · comments

0x31_LinuxKernel_内存管理(一)物理页面、伙伴系统和slab分配器
我们在ARM的博客里面了解到从CPU的角度来看内存管理,里面涉及了很多细节,包括整个的内存分层机制,cache-TLB-ddr如何工作的,并且在ARM上面提供了寄存器里面包含了内存的地址。可以参考以下内容:
Linux系统内核如何使用ARM的MMU机制呢?Linux内核又是如何给用户提供一些使用内存的接口或者方法规则呢?这将是本章的重点,I will work you through memory management between the linux kernel and the linux userspace.
The memory management of linux kernel is a very complex mechanism. To easily understand the mechanism, we get it from the perspective of the linux userspace. 笨叔书里面写的这句话不错:
- 如果从Linux的使用者角度来看内存管理,经常使用的
free命令; - 如果从Linux编程者角度来看,主要就是使用分配函数
malloc,mmap等 - 如果从Linux内核角度来看,那么又可以分角度了:
- 系统模块角度
- 进程角度
我们一步步的揭开Linux的内存管理的面纱,和我们的ARM的MMU机制联合在一起。
1. 非内核角度来看内存管理
本节站在Linux使用者角度 + 编程者角度来看内存管理。
1.2 使用者角度
从使用者的角度来看free是一个查看linux内存的工具,他表示当前系统中已经使用的内存和空闲的内存情况。

total:总共内存数目,如果是-m参数也按照兆字节显示;used:表示已经使用的内存free:未被分配的物理内存大小shared:共享内存大小,主要用于进程之间的通信buff/cache:buff指的是buffers,用来给设备作为缓冲;cache为page cache,用来给文件作为缓冲,提高文件访问速度。available:当内存短缺的时候,系统可以回收buffers和page cache。那么公式available = free + buffers + page cache - 不可回收部分(不可回收部分在page cache里面包含内存共享段、tmpfs、ramfs等)
1.3 从应用编程者角度
Linux的userspace空间提供了malloc()这类的函数,是可以让用户直接访问到内存的最直接的接口。malloc()是从虚拟内存分配内存的函数。除此之外,C库中还提供了一下管理内存的接口,他们是:
void *malloc(size_t size)void free(void *ptr)void *mmap(void *addr, size_t len, int prot, int flags, int fd, off_t offset)int munmap(void *addr, size_t len)int getpagesize(void)int mprotect(const void *addr, size_t len, int prot)int mlock(const void* addr, size_t len)int munlock(const void *addr, size_t len)int madvise(void* addr, size_t len, int advice)void *mremap(void *old_addr, size_t old_size, size_t new_size, int flags....)int rmap_file_pages(void *addr, size_t size, int prot, ssize_t pgoff, int flags)
我们从Linux用户空间来看内存,需要注意以下几种情况:
分配大量的内存
现象一:假如我们的Linux系统的物理内存只有2GB大小,我们申请了一个比物理内存还要大的空间,例如4GB,我们会发现一眨眼的功夫就malloc完毕(如果你不使用的话)。
现象二:如果我们无限度的分配内存,就会发现执行的很慢,最后可能还会收到Out of Memory:killed process xxxx的log输出(在一些操作系统里只可能退出不会输出任何内容)。
这两个现象我们可以浅显的解释一下从编程者角度遇到的问题:
-
因为MMU的存在因此可以分配比物理内存还大的空间,得益于MMU的换页原理和swap技术。
-
malloc在开始分配而没有使用的时候感觉速度特别快,那是因为延迟分配策略。如果不使用这个内存,将不会提取该页面。我们在malloc之后使用memset对这个内存进行初始化,用户侧只是两句话的事儿,实际上linux内核内部执行了非常复杂的逻辑。
- 用户态程序使用malloc接口,分配虚拟地址。
- 0用户程序访问该虚拟地址,比如memset。
- 硬件(MMU)需要将虚拟地址转换为物理地址。
- 硬件读取页表。
- 硬件发现相应的页表项不存在,硬件自动触发缺页异常。
- 硬件自动跳转到page fault的处理程序(内核实现注册好)
- 内核中的page fault处理程序执行,在其中分配物理内存,然后修改页表(创建页表项)
- 异常处理完毕,返回程序用户态,继续执行memset相应的操作。
-
超过一定数量会被Kill,这是Linux的内存耗尽(术语:OOM)保护机制。是Linux保护自己资源的一种手段。
这里就引入了一个话题:既然Linux系统提供了如此丰富的内存保护机制,在资源耗尽前甚至可以直接杀死进程,而且有MMU的存在,那我们是否要对malloc的返回值进行合法性检查呢?答案是肯定的,肯定要检查。那我们检查哪一类错误呢?
通俗来讲,如果我们使用了malloc申请了内存,而我们并没有合法的使用这部分内存(越界访问),此时非法的内存访问可能不会第一时间让程序崩溃,但实际上已经破坏了malloc的分配结构,等下一次进行malloc分配的时候,那么malloc就由于结构性的破坏而无法使用了,因此,我们还是需要对申请的内存进行合法性检查。malloc失败很难因为空间耗尽,而是因为结构性破坏,这个问题会非常难调试(也不一定会出现),通常需要一些辅助的调试工具。
除了malloc,还有calloc和realloc这些函数。calloc结构数组分配,并初始化为0,malloc没有初始化功能;realloc函数改变之前分配的长度(记得实用realloc重新返回的指针,旧的指针不要用了)
1.4 从内存布局角度看内存管理
要了解Linux的内存机制,必然要掌握Linux的内存布局。在内核代码:arch/arm/mm/init.c:472:void __init mem_init(void)函数内部,可以把Linux的内存布局打印出来。
/*
* mem_init() marks the free areas in the mem_map and tells us how much
* memory is free. This is done after various parts of the system have
* claimed their memory after the kernel image.
*/
void __init mem_init(void)
{
#ifdef CONFIG_HAVE_TCM
/* These pointers are filled in on TCM detection */
extern u32 dtcm_end;
extern u32 itcm_end;
#endif
set_max_mapnr(pfn_to_page(max_pfn) - mem_map);
/* this will put all unused low memory onto the freelists */
free_unused_memmap();
free_all_bootmem();
#ifdef CONFIG_SA1111
/* now that our DMA memory is actually so designated, we can free it */
free_reserved_area(__va(PHYS_OFFSET), swapper_pg_dir, -1, NULL);
#endif
free_highpages();
mem_init_print_info(NULL);
#define MLK(b, t) b, t, ((t) - (b)) >> 10
#define MLM(b, t) b, t, ((t) - (b)) >> 20
#define MLK_ROUNDUP(b, t) b, t, DIV_ROUND_UP(((t) - (b)), SZ_1K)
pr_notice("Virtual kernel memory layout:\n"
" vector : 0x%08lx - 0x%08lx (%4ld kB)\n"
#ifdef CONFIG_HAVE_TCM
" DTCM : 0x%08lx - 0x%08lx (%4ld kB)\n"
" ITCM : 0x%08lx - 0x%08lx (%4ld kB)\n"
#endif
" fixmap : 0x%08lx - 0x%08lx (%4ld kB)\n"
" vmalloc : 0x%08lx - 0x%08lx (%4ld MB)\n"
" lowmem : 0x%08lx - 0x%08lx (%4ld MB)\n"
#ifdef CONFIG_HIGHMEM
" pkmap : 0x%08lx - 0x%08lx (%4ld MB)\n"
#endif
#ifdef CONFIG_MODULES
" modules : 0x%08lx - 0x%08lx (%4ld MB)\n"
#endif
" .text : 0x%p" " - 0x%p" " (%4td kB)\n"
" .init : 0x%p" " - 0x%p" " (%4td kB)\n"
" .data : 0x%p" " - 0x%p" " (%4td kB)\n"
" .bss : 0x%p" " - 0x%p" " (%4td kB)\n",
MLK(UL(CONFIG_VECTORS_BASE), UL(CONFIG_VECTORS_BASE) +
(PAGE_SIZE)),
#ifdef CONFIG_HAVE_TCM
MLK(DTCM_OFFSET, (unsigned long) dtcm_end),
MLK(ITCM_OFFSET, (unsigned long) itcm_end),
#endif
MLK(FIXADDR_START, FIXADDR_END),
MLM(VMALLOC_START, VMALLOC_END),
MLM(PAGE_OFFSET, (unsigned long)high_memory),
#ifdef CONFIG_HIGHMEM
MLM(PKMAP_BASE, (PKMAP_BASE) + (LAST_PKMAP) *
(PAGE_SIZE)),
#endif
#ifdef CONFIG_MODULES
MLM(MODULES_VADDR, MODULES_END),
#endif
MLK_ROUNDUP(_text, _etext),
MLK_ROUNDUP(__init_begin, __init_end),
MLK_ROUNDUP(_sdata, _edata),
MLK_ROUNDUP(__bss_start, __bss_stop));
#undef MLK
#undef MLM
#undef MLK_ROUNDUP
/*
* Check boundaries twice: Some fundamental inconsistencies can
* be detected at build time already.
*/
#ifdef CONFIG_MMU
BUILD_BUG_ON(TASK_SIZE > MODULES_VADDR);
BUG_ON(TASK_SIZE > MODULES_VADDR);
#endif
#ifdef CONFIG_HIGHMEM
BUILD_BUG_ON(PKMAP_BASE + LAST_PKMAP * PAGE_SIZE > PAGE_OFFSET);
BUG_ON(PKMAP_BASE + LAST_PKMAP * PAGE_SIZE > PAGE_OFFSET);
#endif
if (PAGE_SIZE >= 16384 && get_num_physpages() <= 128) {
extern int sysctl_overcommit_memory;
/*
* On a machine this small we won't get
* anywhere without overcommit, so turn
* it on by default.
*/
sysctl_overcommit_memory = OVERCOMMIT_ALWAYS;
}
}图片可以表示如下:
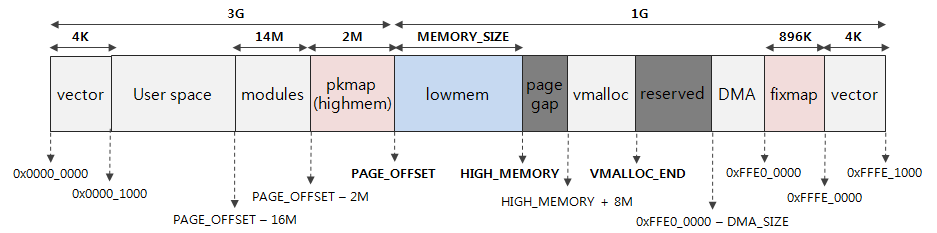
ARM64架构处理器采用的48位物理寻址机制,最大可以寻找256T的内存,足以应付现在的物理内存。在Linux架构中,会把内存空间分为用户空间和系统空间。
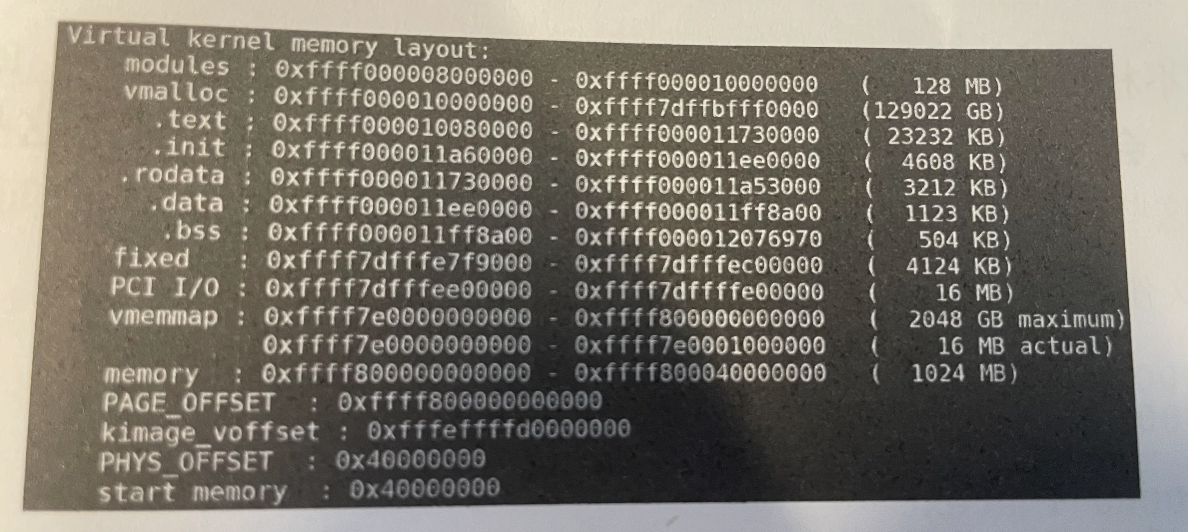
从上面的图片可以看出:
- modules 占用128M的空间;
- vmalloc,大小为129022GB,奇大无比,远大于物理内存空间;
.text.init.rodata.data.bss区域这些内存大小也就几M的样子,这部分是在arch/arm64/kernel/vmlinux.ld.S中定义结束和起始地址。- fxied区域,大小为4124KB
- PCI I/O区域为 16MB
- vmemmap区域: 2048GB,也是奇大无比
- 线性映射区域 memroy: 1024MB (关于线性映射区域参考1)
Linux 的内核使用空间仅仅是1GB大小,通常kernel把物理地址与其他地址空间做了线性映射,也就是一一映射,这样可以提高访问速度。但当Linux内核吃完1GB内存的时候,这时候就有问题了。因此,Linux在的内核空间对这部分内存做了划分,分为线性映射区域和非线性映射区域。1G内存划分896MB为线性区域(低端区域),还是按照原来的方式映射,另外的128MB为非线性映射,非线性顾名思义,是在使用的时候使用kmap动态映射。
类似的还有 ioremap映射到非线性区域,或直接用mmap映射到进程空间。
- PAGE_OFFSET,表示物理内存在内核空间做的线性映射的起始地址。在ARM64架构下面这部分被定义为
0xffff000000000000~0xffff000040000000。因为是线性映射区域,因此在内核初始化的时候会对物理空间直接完成映射。 - KIMAGE_VADDR: 表示将内核image文件映射到内核空间的起始虚拟地址。
- PHYS_OFFSET: 表示物理内存在地址空间的偏移量,不少SoC设计的时候并不是0x0,而是0x40000000。
在内核编译完成之后,所有的符号地址都被统一到System.map的文件中,这个文件非常大,有几十万行,里面映射了空间的虚拟地址和符号。
1.4 从进程的角度来看内存
进程的角度来看内存,我们在ELF文件中已经涉及了这部分。04_ELF文件_加载进程虚拟地址空间 。
一方面可以使用readelf工具来查看链接地址分布;另一方面,在linux shell中,找到 cat /proc/721/maps可以查看虚拟内存映射地址分布(cat /proc/721/smaps会提供更多信息。)
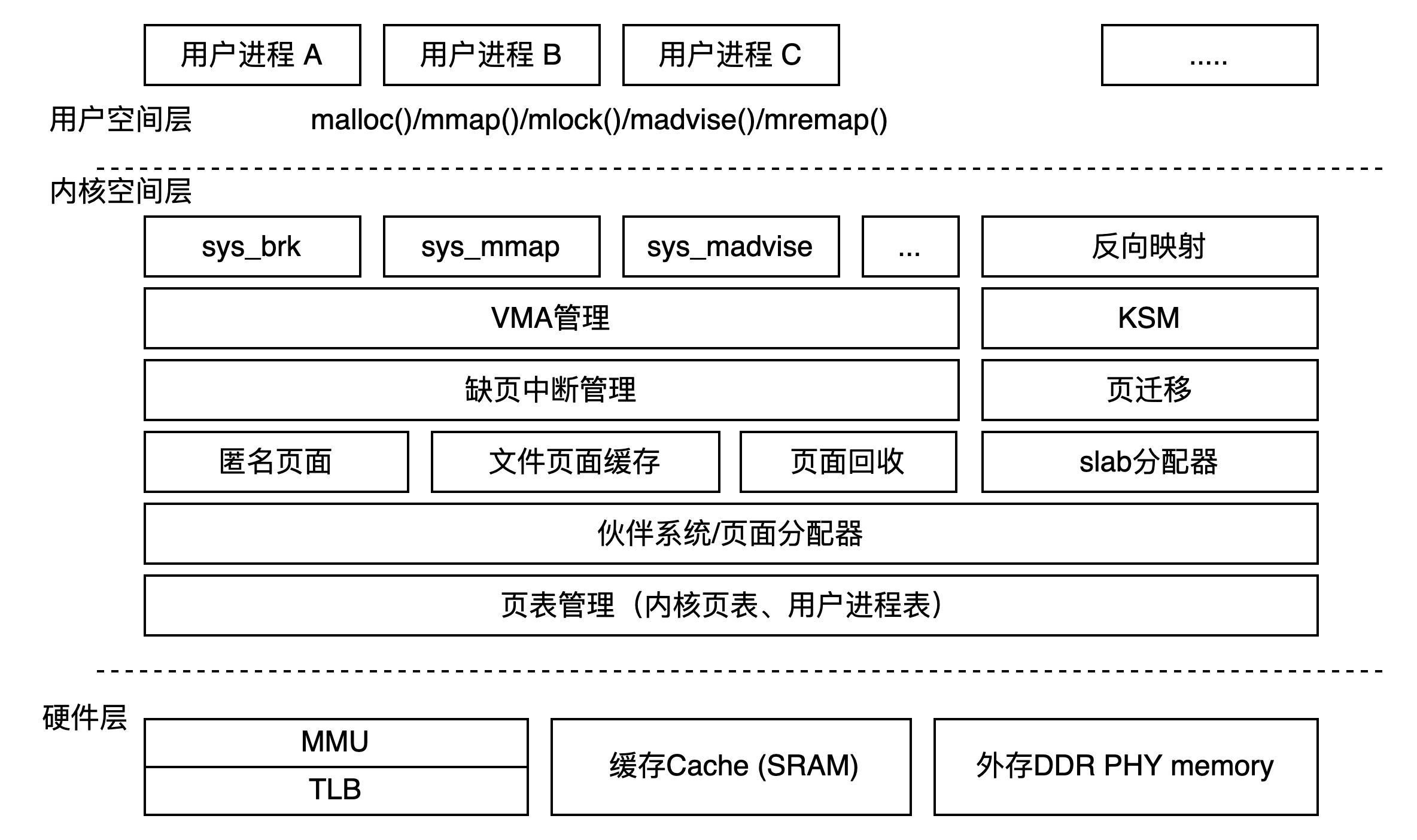
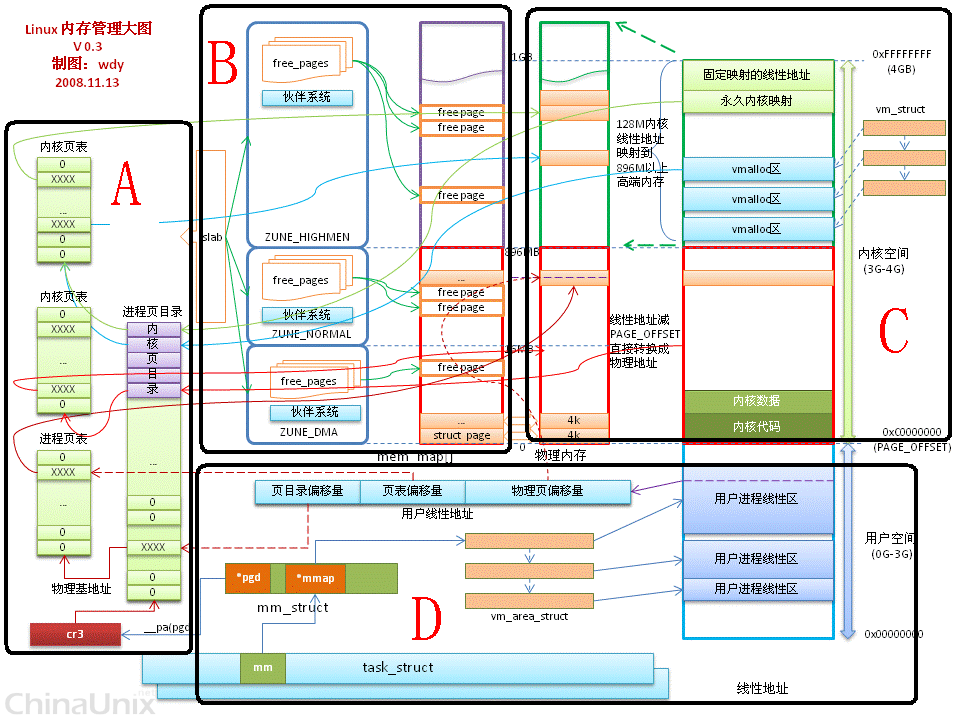
1.5 内核角度来看内存
我们可以用一个图像来表示:
2 物理内存管理
我们知道页面是MMU管理物理内存的最小单位,1页默认是4K的大小,所以Linux就按照4K为单位的大小对物理内存进行管理。在设计上,Linux把物理内存视为一个宝贵资源,因此在设计上能省则省。我们在这节需要思考和解决几个问题:
- 当物理内存不足的时候,该Linux系统采取什么策略?
- 系统运行了很长时间就会有碎片的问题,Linux对于碎片如何进行管理的?
- 如何分配几十字节的小块内存?
- Linux在提高物理内存分配上面使用了什么方法?
本节从这几个问题从Linux的视角来看如何对于物理内存进行管理的。
2.1 物理页建模
Linux内核本质是一堆数据结构,那么在Linux的世界如何表示物理页呢?一方面我们要让Linux能够找到物理页处于哪个内存;另一方面,我们是不是还要知道我们所指向的物理页的状态在哪里?我们学习了ARM,我至少能想到这一页是不是失效了,这一页的访问属性是什么?因此我们就要对物理页进行丰富的描述。那么Linux有哪些属性需要描述呢?我相信这些属性是非常重点且必须描述的,有冗余的信息在大范围使用后根据叠加原理势必会造成很大的浪费,当然在设计的时候也采用了一些技巧来节约空间。物理页建模的了解是解释上述4个问题的基石,因此我们不得不花一定的篇幅来了解物理页建模。
参考2,Linux为了描述物理页建立了struct page结构体来对物理页进行抽象。
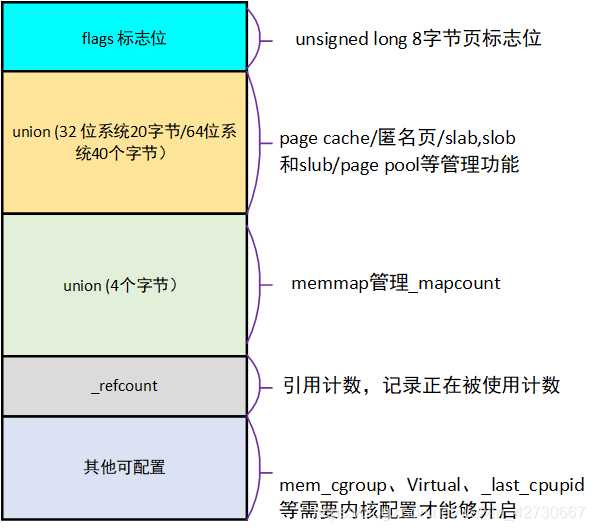
物理页建模设计之初就采用了很多技巧节约空间,这些技巧包含:
- 在定义的结构的时候使用联合体;
- 使用flags页标志(将flags页标志位一些划分出一部分给nodeid和zone使用,低44位自己用)
- list_head lru链表复用(在不同时期,不同的用途会指向不同的链表,以节约空间,例如mapping字段)
page结构体定义在include/linux/mm_types.h中。
flags
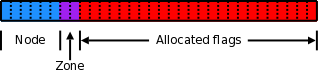
flags标志位一共是64位,低44位自己使用,即表示真正的flags,这部分是枚举类型,在include/linux/page-flags.h中定义,里面用于指示页面是否已经上锁、是否发生了错误、页面内容是否有效、内容是否修改过、是否为混合页面、是否要被回收了,等等等,非常多的种类。这部分可以参考2。
_refcount和_mapcount成员
_refcount和_mapcount是page结构体非常重要的计数引用,并且都是atomic_t类型的。啥意思呢?refcount表示内核页面引用的次数,如果这个值为0的时候,表示空闲和即将被释放的页面;如果大于0,表示这个页面正在被使用,暂时不会被释放。Linux内核提供了用于加减这个数的接口get_page()和put_page()
_mapcount表示页面被进程映射的个数,即有多少个PTE。每个用户进程都有自己独一份的虚拟空间和独一份的页表,所以有可能出现多个用户进程地址空间同时映射到同一个页面的情况,所以mapcount的作用就是用于用户进程的映射次数。如果为-1,表示没有pte页表映射到页面中;如果等于0,表示只有父进程映射到了这个页面。
内核代码同样也不会直接访问这两个变量,而是采用两个宏来计算。page_mapcount和page_count两个函数。
mapping字段
mapping字段可以被“重映射”。当页面用于缓存文件的时候,mapping字段指向一个与文件缓存关联的address_space对象。这个address_space对象属于内存对象的页面集合。而用于匿名映射时候,mapping指向anon_vma数据结构,主要用于反向映射。(暂时不理解什么意思)
lru字段
lru字段主要是用于页面回收的LRU链表算法中。LRU链表算法按定义了多个链表,比如活跃链表和非活跃链表。在slab机制中,lru字段还用来把一个slab添加到slab满链表、slab空闲链表和slab部分链表中。
virtual字段
virtual字段指向页面对应的虚拟地址的指针。在高端内存情况下,高端内存不会线性映射到内核地址空间。在这种情况下,这个字段的值为NULL,只有当需要时才会动态的映射高端内存的页面。
总结
内核使用page的物理页,可以获得如下信息:
- 内核知道当前的物理页状态(通过flags)
- 内核知道页面是否空闲(通过refcount和mapcount)
- 内核知道谁在用这个页面(通过mapping)
- 内核知道这个页面是否被slab机制使用(通过lru字段)
- 内核知道这个页面是否是线性映射(通过virtual字段)
Linux内核为每一个物理页面都创建一个page结构体,并且采用mem_map[]数组结构来保存page 结构体3。如图表示:
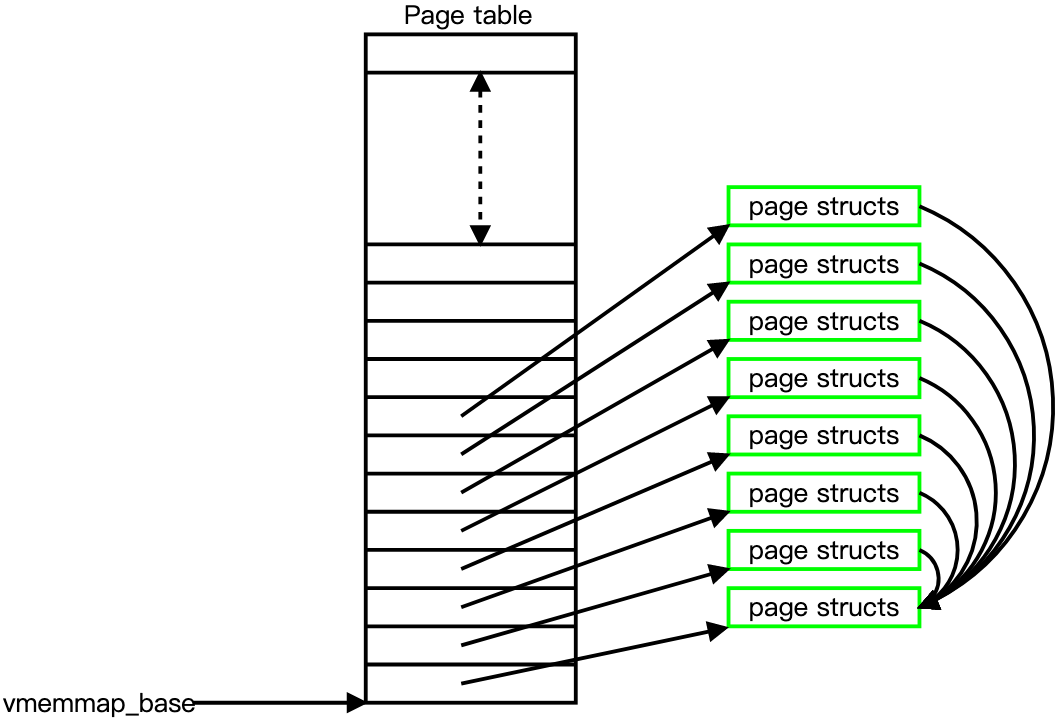
2.2 内存管理区
前面我们谈论,Linux为了更好的利用内存,不完全是对内存进行一一映射(有一一映射的,也有没有一一映射的),因此就要对内存区域进行概念上的划分。我们定义对内存进行一一映射的区域叫做线性映射区,对内存没有一一映射的区域叫做非线性区。为了表示这些区域,Linux定义了宏定义:
ZONE_DMA: 用于DMA操作通常是有0-16M(ARM处理器没有这个区域)ZONE_NORMAL:用于线性映射的物理内存。ZONE_HIGHMEM:用于管理高端内存,也就是非线性区域。在ARM64下不需要这个内存管理区域。
同样的内存管理区一样有数据结构来描述:include/linux/mmzone.h
struct zone {
/* Read-mostly fields */
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long watermark[NR_WMARK];
long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA
int node;
#endif
unsigned int inactive_ratio;
struct pglist_data *zone_pgdat;
struct per_cpu_pageset __percpu *pageset;
unsigned long dirty_balance_reserve;
#ifndef CONFIG_SPARSEMEM
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
#ifdef CONFIG_NUMA
unsigned long min_unmapped_pages;
unsigned long min_slab_pages;
#endif /* CONFIG_NUMA */
unsigned long zone_start_pfn;
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
const char *name;
int nr_migrate_reserve_block;
#ifdef CONFIG_MEMORY_ISOLATION
unsigned long nr_isolate_pageblock;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
seqlock_t span_seqlock;
#endif
wait_queue_head_t *wait_table;
unsigned long wait_table_hash_nr_entries;
unsigned long wait_table_bits;
ZONE_PADDING(_pad1_)
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
/* zone flags, see below */
unsigned long flags;
/* Write-intensive fields used from the page allocator */
spinlock_t lock;
ZONE_PADDING(_pad2_)
/* Write-intensive fields used by page reclaim */
/* Fields commonly accessed by the page reclaim scanner */
spinlock_t lru_lock;
struct lruvec lruvec;
/* Evictions & activations on the inactive file list */
atomic_long_t inactive_age;
unsigned long percpu_drift_mark;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* pfn where compaction free scanner should start */
unsigned long compact_cached_free_pfn;
/* pfn where async and sync compaction migration scanner should start */
unsigned long compact_cached_migrate_pfn[2];
#endif
#ifdef CONFIG_COMPACTION
unsigned int compact_considered;
unsigned int compact_defer_shift;
int compact_order_failed;
#endif
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
bool compact_blockskip_flush;
#endif
ZONE_PADDING(_pad3_)
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
} ____cacheline_internodealigned_in_smp;由于ZONE数据结构经常被访问到,因此该数据结构要求以L1高速缓存对齐,____cacheline_internodealigned_in_smp。Zone的数据结构总体可以分为以下部分:
- 只读区
- 写敏感区域
- 统计信息
这里采用ZONE_PADDING使后面的变量与L1的cache line对齐,以提高性能。
Linux提供几个辅助函数for_each_zone来遍历所有的zone空间。还有is_highmem来判断是否是高端内存;其次zone_idx可以获取zone的内存节点编号。
3 页面分配和释放
3.1 伙伴系统
内存页面的分配,Linux内核采用伙伴系统(buddy system)来完成,伙伴系统并非Linux专用,而是一般性操作系统都会用到的方法,它是操作系统中常见的动态管理和存储的方法。用户提出申请的时候,伙伴系统分配一个大小合适的内存给用户;用户释放的时候,回收内存块。
在伙伴系统中内存块的大小是2的order次幂个页面(Linux内核中MAX_ORDER来表示最大阶数,通常是11),也就是把所有的空闲页面组成11个内存块的链表,这些链表的项包含1个、2个、4个、8个.....1024个连续的页面。1024个连续页面所占的内存是4MB的大小。所以在图形上你看到的应该是这样的:
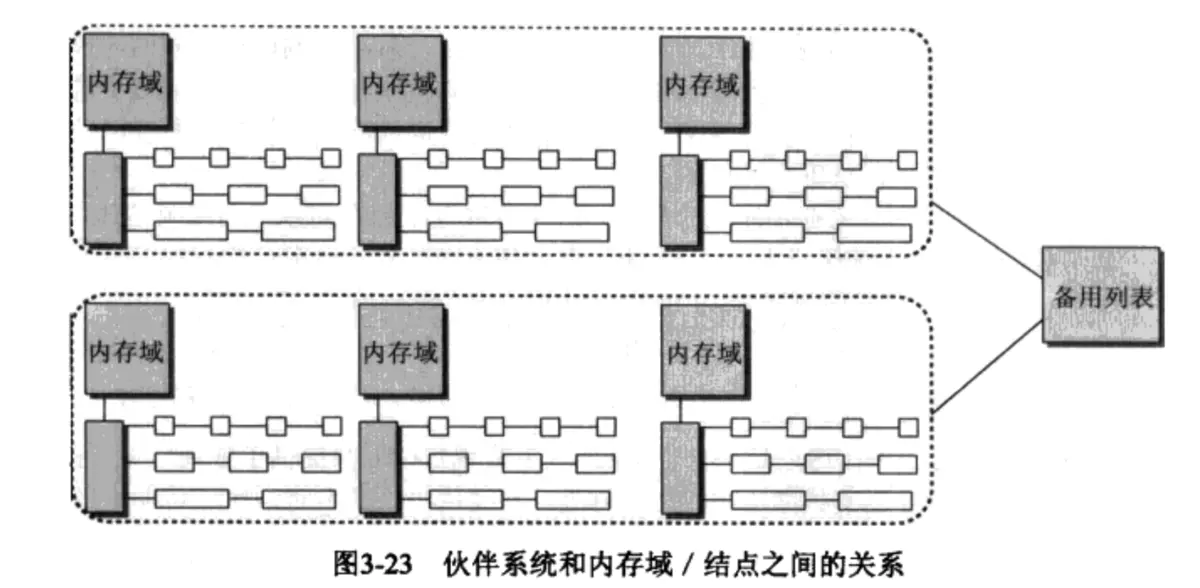
3.2 页面管理函数
- alloc_page:用来分配2的n次方的连续个物理页面,返回是第一个物理页面的page;
- get_free_page:返回的是所分配内存的内核空间虚拟地址,如果是线性映射的物理内存,直接返回线性区域的内核空间。这个函数不能访问高端内存,如果要用高端内存,最佳办法是alloc_page和kmap函数的搭配。
- free_page:释放函数
- gfp_mask:分配掩码,这里的函数设计属性通过掩码的方式进行传递:
- 内存管理修饰符:是从dma分配还是从高端内存分配
- 移动修饰符
- 水位修饰符
- 页面回收修饰符
- 行动修饰符
- 类型标志位:包括KERNEL、ATOMIC、USER、NOIO这些
3.3 内存碎片化
物理内存页分配会出现外部碎片和内部碎片问题,所谓的内部和外部是针对 “页内外” 而言的,一个页内的内存碎片是内部碎片,多个页间的碎片是外部碎片。13_ARMv8_内存管理(一)-内存管理要素 提到了外部碎片(孔和孔之间的)和内部碎片(孔内的),在Linux系统中概念在页管理模式下有一些延伸:4
外部碎片:当需要分配大块内存的时候,需要用好几页组合起来才够,而系统分配物理内存页的时候会尽量分配连续的内存页面,频繁的分配与回收物理页导致大量的小块内存夹杂在已分配页面中间,形成外部碎片。
内部碎片:当实际只需要很小内存的时候,也会分配一张至少 4K 的页面,而内核中有很多需要以字节为单位分配内存的场景,这样本来只想要几个字节而已却不得不分配一页内存,除去用掉的字节剩下的就形成了内部碎片。
客观手段,即良好的编程习惯:
- 少用动态内存分配的函数,尽量使用栈空间。
- 分配内存和释放的内存尽量实现在同一个函数中。
- 尽量一次性申请较大的内存,而不要反复申请小内存。
- 尽可能申请大块的 2 的指数幂大小的内存空间。
- 自己进行内存管理工作,设计内存池程序模块。
主观手段,即操作系统自身的内存分配算法:
- 伙伴系统算法:避免外部碎片。
- Slab 算法:避免内部碎片。
内存碎片化是内存管理中比较难以解决的问题。Linux采用伙伴系统时也考虑了减少碎片的设计。在伙伴系统中,两个什么样的内存可以成为伙伴呢?需要同时满足:
- 两个内存块的大小相同
- 两个内存块的地址连续
- 两个内存块是从同一个区域分配出来的
这样的区域可以被合并。学术上常用的解决外存碎片的技术叫做“内存规整”,方法是利用移动页面的位置让空闲的页面连成一片。然而这种方法在内核中不一定奏效,因为迁移这些页面需要断开内核与内存之间的关系映射,如果刚好内核使用这个页面,那么系统就会崩溃掉。后来就引入了“反碎片法”,方法和“内存规整”一直也是靠移动页面完成,但对内存进行分类:
- 不可移动类型:有固定的的位置,不能移动,比如内核就放在这个区域、GFP_KERNEL标识就是标识这个属性。
- 可移动类型:标识可以移动的位置,这部分malloc,mmap分配的匿名页面都属于这个属性。
- 可回收页面:这些页面不可以被移动,但是可以被回收,然后再去被分配。
因此伙伴系统中内存又被分为了以上三类,如图5
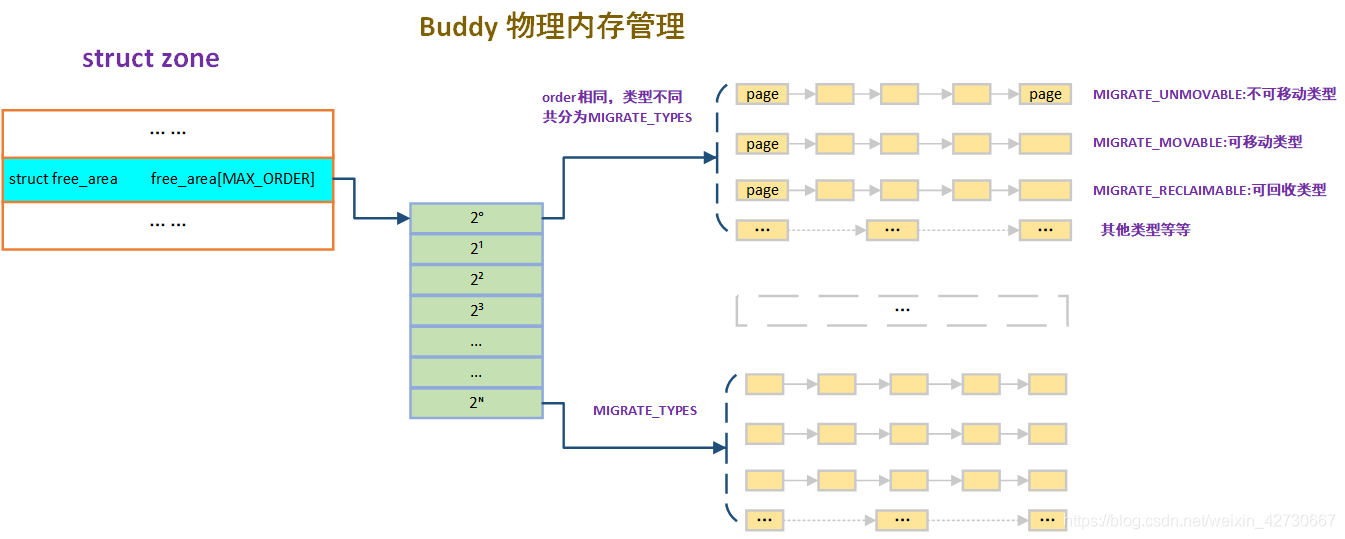
这样伙伴系统就大大减小了内存碎片。另外我们通过cat /proc/buddyinfo能够看到本机的伙伴系统的内存区域。

4 分配小块内存slab
图片来源6:
4.1 啥是slab
之前一直slab/slob的,我们进一步的来看一下slab是个什么东西。当内核需要几十字节的小内存的时候,如果分配一个4k页面实在是有点浪费,再想一想,如果为了几十字节的小内存独占一份4k页面的内存,这也大大增加未来缺页的可能性,会严重的浪费空间和性能,因此不可能为了小内存而直接使用伙伴系统分配页面。所以就建立了slab分配器,专门去处理小内存的需求。slab还有两个变种就是slob和slub,slab在大型服务器上面表现不是很好,管理成本高,所以出现了slub机制;在嵌入式平台,slab又很复杂,对于嵌入式平台不是很友好,所以出现了slob机制。这就是slab、slob和slub三个机制的连续和区别,他们目的是一样的,分配小内存,但是因为平台特性又有自身的特点。
Slab 的好处:
- Slab 内存管理基于内核小对象,不用每次都分配一页内存,充分利用内存空间,避免内部碎片。
- Slab 对内核中频繁创建和释放的小对象做缓存,重复利用一些相同的对象,减少内存分配次数。
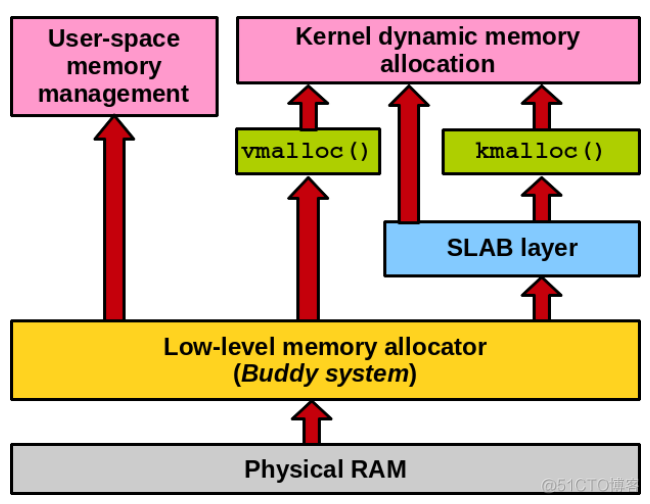
伙伴系统的分配方式在Linux内存中也有分配小内存的机制在使用,比如kmalloc,他的原理是分配基于2的order次幂的内存块,然后也不需要分配页面。如图所示,这就很清晰一个经常问到的面试问题,kmalloc和vmalloc有什么区别?我们经常听到的回答是vmalloc用于分配更大的内存,kmalloc分配小内存用的。实际上这个回答就不是很root casue,vmalloc直接touch伙伴系统,伙伴系统可以直接分配物理页面,而kmalloc是slab机制服务出的一层接口,用于高效分配小内存的,避免产生碎片。
而slab机制使用的是预先分配缓冲池的方式。例如,linux经常分配mm_struct这个结构体的空间,slab机制会建立mm_struct的缓冲池,如果空间充足,那么直接把缓冲池分配好的空闲对象推出去,这样速度相当的快,这比伙伴系统去建立page映射要快得多;而slab也有缺点,第一个分配的对象(比如mm_struct)不一定是2的整数次幂对齐的,一定会有空间的浪费,第二个缺点就是,Linux页面分配器中申请物理页面的时候,有可能会被阻塞,也就是发生睡眠等待,因此在内存紧张的时候,在观感上就会觉得申请的很慢,就是因为有一些阻塞过程。
4.2 slab接口
slab分配器提供了一些接口来创建、释放slab描述符和分配缓存对象,而这些接口并不是以slab命名的,kmem_cache是slab的核心结构体。
struct kmem_cache *kmem_cache_createkmem_cache_destroykmem_cache_allockmeme_cache_free
这里面的参数包含了一些文件描述符、缓存大小、对齐字节、分配掩码、构造函数等等。
在ext4文件系统中使用kmem的相关接口创建自己的描述符:
int __init ext4_init_es(void)
{
ext4_es_cachep = kmem_cache_create("ext4_extent_status",
sizeof(struct extent_status),
0, (SLAB_RECLAIM_ACCOUNT), NULL);
if (ext4_es_cachep == NULL)
return -ENOMEM;
return 0;
}
void ext4_exit_es(void)
{
if (ext4_es_cachep)
kmem_cache_destroy(ext4_es_cachep);
}这算是一个使用slab的实例。
4.3 slab分配**
我们这里对slab功能进行阐述,具体如何实现不涉及。内核经常需要分配几十字节的小内存,仅仅为此创建物理页面十分浪费且麻烦。早期内核实现了2的n次方的大小内存分配算法,但是并不高效,直到sun公司提供了slab算法。这种slab的好处在于:
- 把分配内存作为object,可以自定义构造函数和析构函数来初始化和释放内存对象。
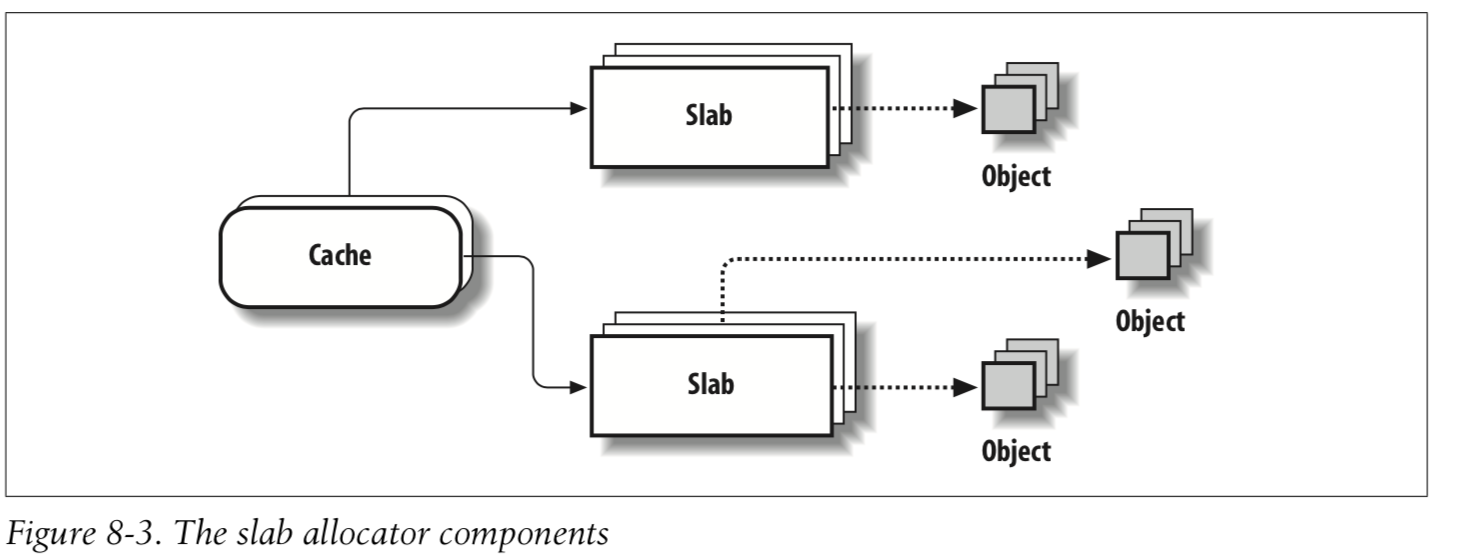
- slab释放之后不会被立即丢弃,而是进入到缓冲池中,等待下一次有机制使用,就不需要再向伙伴系统分配页面。
- slab算法可根据特定大小创建slab描述符,比如内存的常见数据结构大小,这样就可以避免内存碎片的产生,还可以快速获得频繁访问的数据结构。slab也支持2的n次方的大小分配**。
- slab算法创建了多层缓冲池,充分的利用了空间换时间,有效解决效率问题。
- 每个CPU都有本地对象的缓冲池,避免了多核之间的锁竞争的问题。
- 每个内存节点都有共享对象缓冲池。
最后不得不提一下slab所服务的kmalloc机制。类似于伙伴系统机制,kmalloc机制按照内存2的n次方创建多个slab描述符,例如16字节,32字节,64字节,128字节大小,系统会创建名为kmalloc-16, kmalloc-32, kmalloc64 这些描述符。当系统启动的时候会在create_kmalloc_caches函数完成的。
void *kmalloc(size_t size, gfp_t flags)
void kfree(const void *)
Slab 高速缓存分为两类:4
通用高速缓存:slab 分配器中用 kmem_cache 来描述高速缓存的结构,它本身也需要 slab 分配器对其进行高速缓存。cache_cache 保存着对高速缓存描述符的高速缓存,是一种通用高速缓存,保存在 cache_chain 链表中的第一个元素。另外,slab 分配器所提供的小块连续内存的分配,也是通用高速缓存实现的。通用高速缓存所提供的对象具有几何分布的大小,范围为 32 到 131072 字节。内核中提供了 kmalloc() 和 kfree() 两个接口分别进行内存的申请和释放。slab 分配器所提供的小块连续内存的分配是通过通用高速缓存实现的。
专用高速缓存:内核为专用高速缓存的申请和释放提供了一套完整的接口,根据所传入的参数为指定的对象分配 Slab 缓存。内核为专用高速缓存的申请和释放提供了一套完整的接口,根据所传入的参数为具体的对象分配 slab 缓存。kmem_cache_create() 用于对一个指定的对象创建高速缓存。它从 cache_cache 普通高速缓存中为新的专有缓存分配一个高速缓存描述符,并把这个描述符插入到高速缓存描述符形成的 cache_chain 链表中。kmem_cache_alloc() 在其参数所指定的高速缓存中分配一个 slab。相反, kmem_cache_free() 在其参数所指定的高速缓存中释放一个 slab。
随着大规模多处理器系统和 NUMA 系统的广泛应用,Slab 也暴露出了一下问题:
- 复杂的队列管理。
- 管理数据和队列存储开销较大。
- 长时间运行 partial 队列可能会非常长。
- 对 NUMA 支持非常复杂。
为了解决问题,基于 Slab 推出了 Slub:改造 Page 结构来削减 Slab 管理结构的开销、每个 CPU 都有一个本地活动的 slab(kmem_cache_cpu),对于小型的嵌入式系统存在一个 Slab 模拟层 Slob,在这种系统中它更有优势。
``
ChangeLog
- [2022-9-13]:
- 增加Slab论述;
- 增加内存碎片化论述;