20_ARMv8_barrier(一)流水线和一致性模型
carloscn opened this issue · comments

20_ARMv8_barrier(一)流水线和一致性模型
我在工作的时候,又看见osal_wmb()还有osal_rmb()的接口,而那时候有个任务就是要设计osal的套件,针对于内存屏障的接口,有一点不知所措。内存屏障是ARM编程很重要的一部分,尤其是在多核并行的程序中。我们这一节主要就是来描述内存屏障的产生的原因和解决方法。这一节主要的思路来自于《ARM64体系结果编程》,另外从ARMv8的programmer guide中:整理第十三章memory odering、第十四章Multi-core processors中的知识。
内存屏障可以从两个维度发生:
- 编译器级。编译器会把C语言转为汇编文件的时候进行优化,如内存访问指令的重排可以提高指令的效率。然而对于一些你对ordering十分care的环境下,这就发生了歧义。通常在
#define barrier() __asm__ __volatile__ ("":::"memory")告诉编译器不要对此处进行优化。 - CPU级。在指令执行的时候,由于现代的处理器都是采用的超标量的架构、乱序发射(issue)、乱序执行等等,这些技术都是提高执行效率的方法,因此在指令执行的阶段,指令在流水线中可能被打乱,直观的感受就是运行的时候发现和编写的代码不一致。
内存屏障只用于多核系统中,相对于cache而言,也可以属于多核的一致性问题。我们理解ARMv8的ordering的问题,就要首先理解流水线的乱序执行和一致性模型的理论基础。
1. 流水线技术
我们来先科普一波什么是ARM的流水技术,还有超标量、多发射、乱序执行。
1.1 CPU的流水线指令设计1
1.1.1 单指令周期处理器(历史)
程序的性能 = 指令数×CPI×时钟周期,一个CPU的时钟周期认为是可以完成一条最简单的计算机指令所需要的时间。在单指令周期处理器(Single Cycle Processor)中,一条指令的执行,最少最少包含FDE三个步骤(fetch、decode、execution),执行这三步至少需要一个时钟周期。换句话说,一个时钟周内,处理器正好处理一条指令,这种就是SCP处理器。然而这就面临着一个问题,指令的电路复杂程度不一样,所以执行时间肯定是不一样的,更有随着电路层数的增加,由于门延迟、位数多、计算复杂指令需要执行更久的时间。不同指令执行时间不同,但是要让所有指令都在一个时钟周期内完成,唯一的办法就是估算最长耗时的指令周期认为是整个SCP的时钟周期。这种情况下,我们保证了CPI=1,但是在一个周期内的时钟频率没有办法再进行提高了,如果设定太高的时钟频率,一些指令是无法在一个CPI内完成指令执行的。例如,以下汇编代码,我们先对x1寄存器和8进行乘法存入x0寄存器(为8),接着从x0寄存器读取相乘的数据之后加16,最后x0寄存器中的数字应该是(8+16=24)。
MOV x0, #1
MUL x0, x0, #8
ADD x0, x0, #16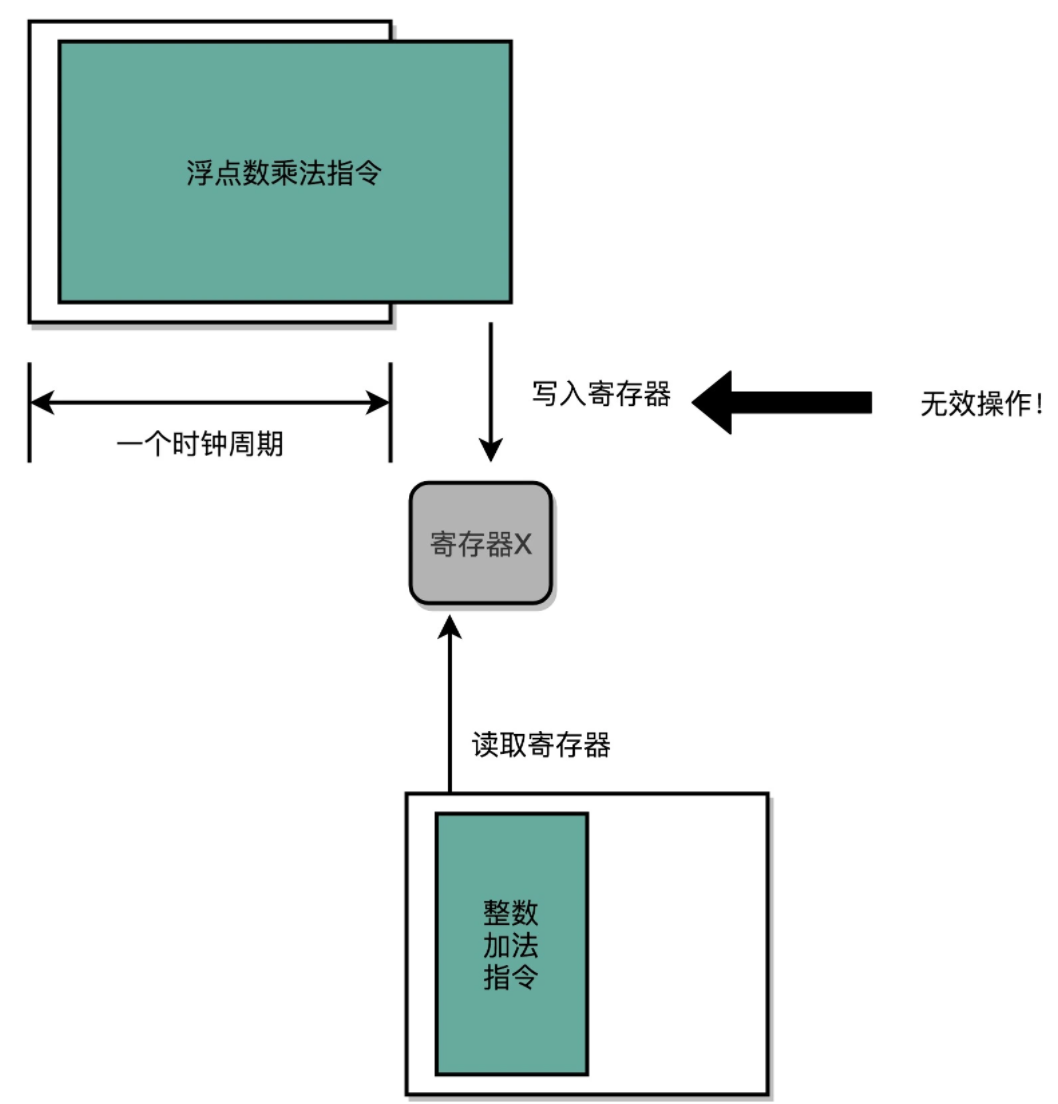
如果CPU的频率调的太高,浮点乘法的指令需要比较长的时间,运算乘法还没有完成,下一个CPU时钟周期开启之后,加法指令开始执行,加法器拿着原始的X的值进行运算,得到了一个错误的结果(17)。因此,SCP处理器有个极大的弊端,就类似于“木桶效应”,高速的指令不得不让步耗时的运算指令,浪费了CPU的performance.
1.1.2 流水线/超标量处理器
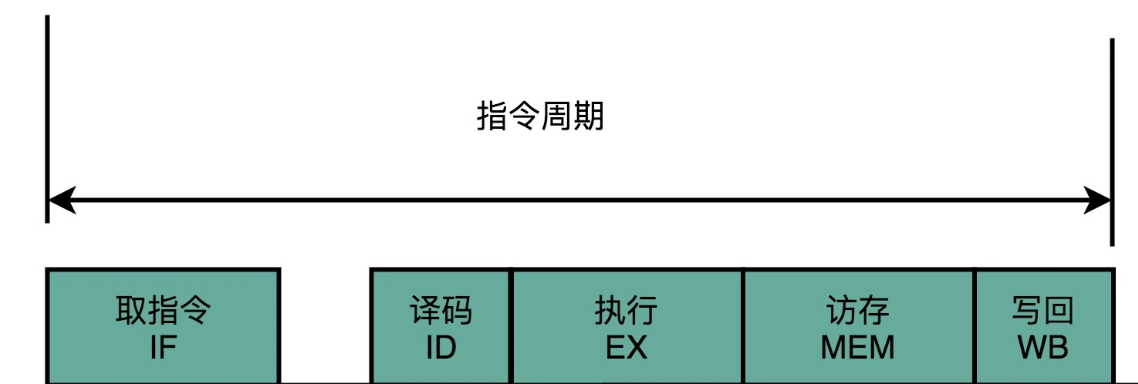
无论是Intel CPU还是ARM CPU,都摒弃了单指令周期处理器,采用了流水线技术**(Instruction Pipeline)**。流水线技术是相对于单指令周期而言的,如果单指令周期把一个CPU指令周期看成一个整体,那么流水线技术是把CPU指令周期进行了拆分,最少分为了“取指令、译码和执行”三个步骤,这三个步骤我们成为“三级流水线”。在一些处理器中,做了更多的细分,分成了五级、六级流水线或者更多,除了三级流水线的基本操作,还包含了从寄存器读数据、通过ALU运算、把结果写回到寄存器或者内存中。要注意,流水线的这些操作都是在一个CPU时钟周期内的操作。三级流水线基本操作:
- 取指令(F):需要一个译码器,把数据从内存取出来,写入到寄存器中;
- 译码(D):需要另一个译码器,把指令解析成对应控制信号、内存地址和数据。
- 执行(E):需要一个完成计算工作的ALU。
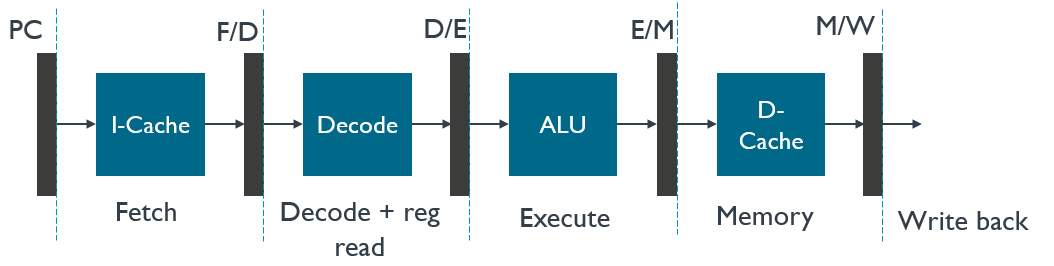
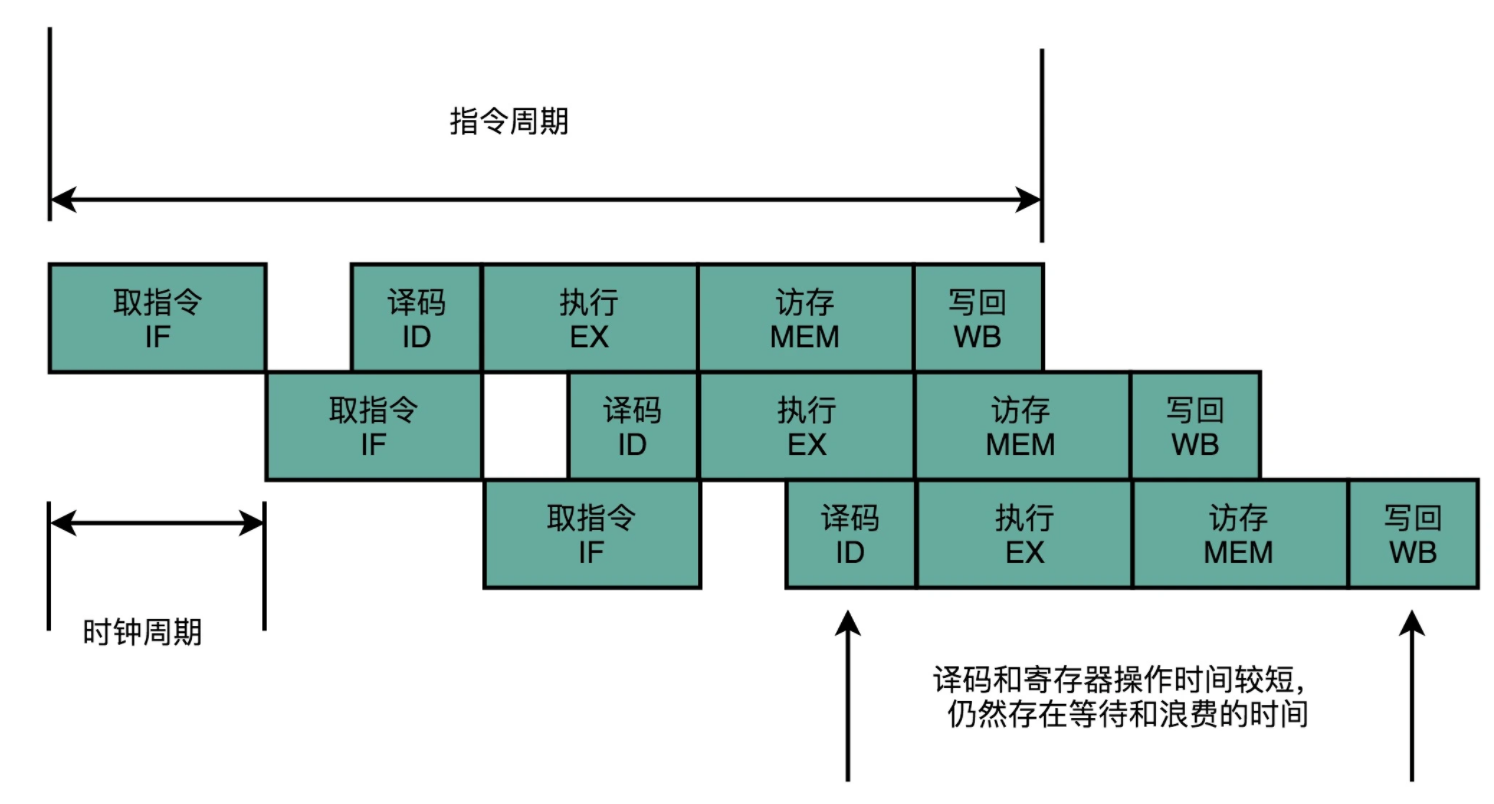
以下是一个五级流水线的示意图,流水线应该在一个指令周期(CPU周期)内完成,每一级流水线都占用一个CLK时钟周期。五级流水线实际上是把“执行指令”进行了进一步拆分,拆分成“ALU计算、内存访问和数据写回”。问题就来了,提高流水线级数意义在哪里 ?实际上这部分就涉及了CPU另一个话题,超标量技术(多条流水线并行执行)。把一个执行时间较长的流水线拆分成多条流水线,第一,有益于执行粒度细化,因为每个流水线占用一个CLK周期,在多条流水线并存的时候可以在同一个流水线位置下插入另一条流水线;第二,由于执行粒度细化,可以提高时钟频率。这就可以解决单指令周期处理器遇到的“木桶原理”的瓶颈问题。目前的处理器的流水线级数已经达到了14级之多。这种做法无非是以空间换时间,在芯片上增加RTL的电路单元,实现并行执行从而节约了时间。
如图所示,以下就是多条流水线并行执行,这就是超标量技术。
这就不用把时钟周期设置成整条指令执行的时间,而是拆分成完成这样的一个一个小步骤需要的时间。同时,每一个阶段的电路在完成对应的任务之后,也不需要等待整个指令执行完成,而是可以直接执行下一条指令的对应阶段。这样的协作模式,就是指令流水线。这里每个独立步骤,称为流水线阶段或流水线级(Pipeline Stage)。
那问题又来了:既然可以拆分流水线细化有这样的好处,为什么我直接把一个CLK长度作为一个流水线级呢?比如弄100个流水线。
超长流水线的性能是有瓶颈的,这个世界的准则告诉我们,并不是越多就越好,物极必反。流水线深度也是一样。流水线的出口和入口就像是火车的车厢一样,需要流水线寄存器(pipeline register)作为黏合,因此在流水线和流水线递交作业的时候,都会访问流水寄存器,不断加深流水线的深度,那么就增加了流水线寄存器的次数。
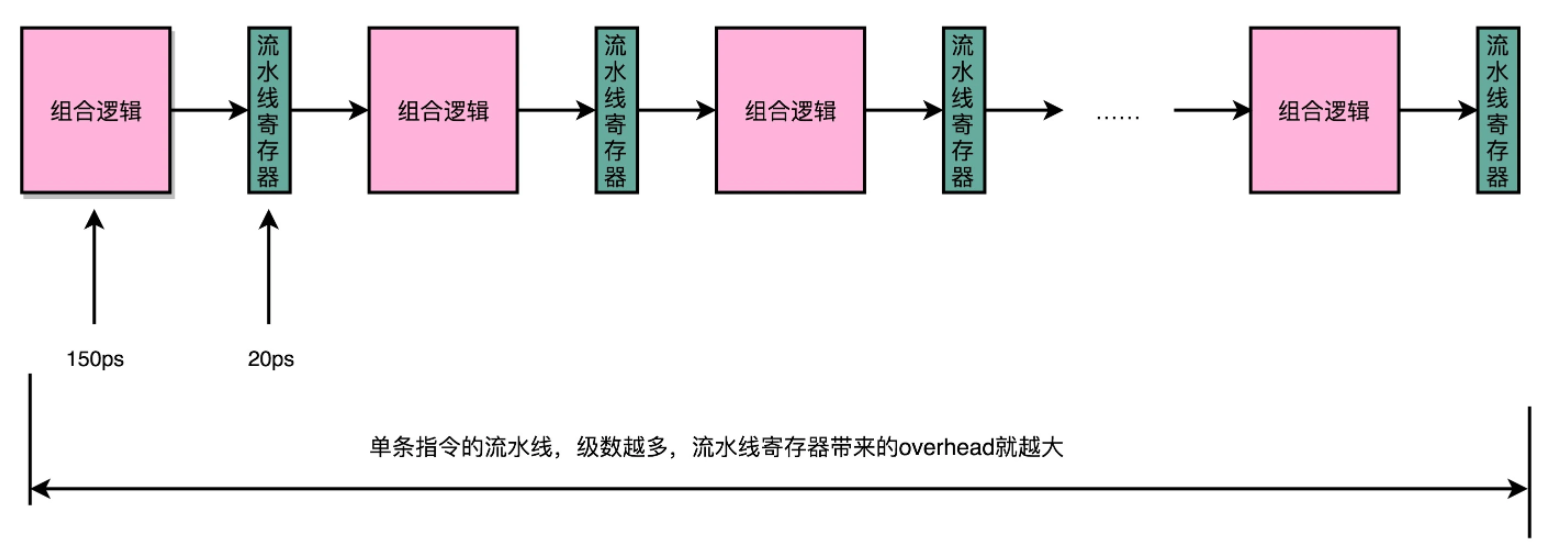
我们这里有个数字:
- 20级流水线,访问寄存器需要400ps, 占超过10%
- 50级流水线,访问寄存器需要1ns在流水线寄存器上,占25%
因此就意味着,单纯增加流水线的深度,不仅不能提升性能,反而会有过多的硬件成本开销和性能开销。CPU工程师在设计的时候,对流水线深度的论证也是不可或缺的过程。
1.1.3 乱序执行2
每次读到乱序执行的时候,就很难理解,乱序执行?如果CPU拿执行和数据乱执行,那岂不是天下大乱了。实际上,乱序执行并非“乱执行”,这种乱序也是有限度的乱序,而并非无限度的乱。处理器的技术已经发展的非常成熟了, 而为了追求性能,不得不在软件和硬件上再进一步的做优化,而这些优化是有代价的。对于一个程序,从编译和执行的两方面角度,都有对于程序的有限的序的调整,后面内存屏障也可以来说明这个问题。那么什么是乱序执行?什么情况下会乱序执行呢?
乱序执行得益于上面的流水线技术和超标量技术,他们使得多条指令可以同时地、无串扰地执行。我们这里以4条流水线和4条标量的执行空间来举例说明一下什么是乱序执行。如果指令之间没有依赖关系,后面的一条指令并不需要等到前面的指令执行完毕之后再开始执行,而是前一条指令取指完成之后,后一条指令就可以开始执行操作。比较理想的情况是,指令之间没有依赖,可以使流水线和标量并行化的效率最高:

按序执行
ldr x3, x0 // 指令1:无依赖
add x3, x3, x1 // 指令2:依赖指令1
sub x1, x6, x7 // 指令3: 无依赖
add x4, x1, x10 // 指令4:依赖指令2这里有几个ARM64的汇编,指令2依赖于1,指令4依赖指令2。如果按照序的方式执行,那么指令2需要等到指令1完成之后才可以执行;同理指令4需要依赖指令3完成之后才能执行。假设在4x4的流水线和标量的寄存器中这样的执行:

这就极大的浪费了流水线的空间,甚至需要更长的时钟周期才能完成这个指令的执行。
乱序执行
如下图所示,因为指令1和指令3没有依赖关系,所以对流水线进行重排,指令1 -> 指令3 -> 指令2 -> 指令4, 这样就充分利用了流水线。IDLE的面积和时钟周期都相应的减小。
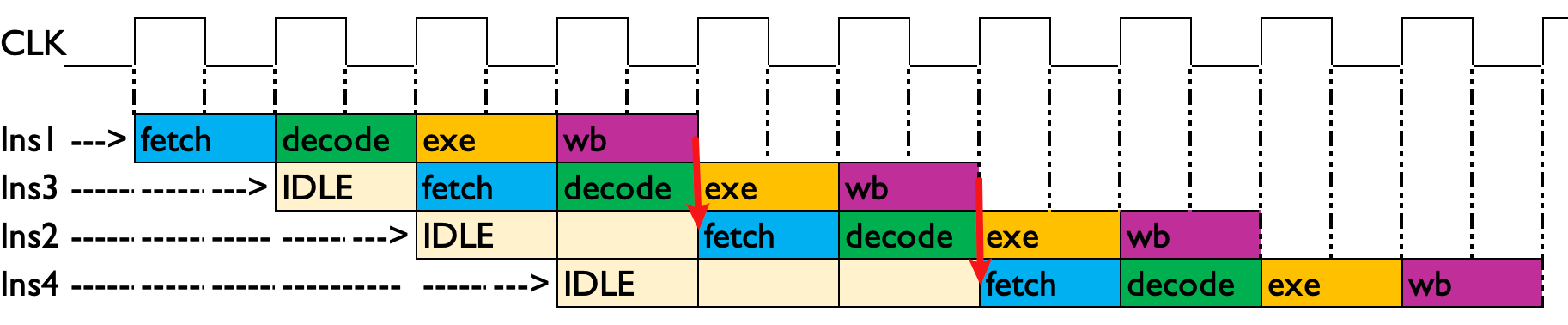
这种有限度(没有依赖关系的)的乱序可以使流水线最大可能的“充满”,提高工作效率。
Strongly-Ordered Device
这里有个Strongly-Ordered Device的概念。Strongly-ordered device是一种嵌入式设备,其内存系统中的所有操作都是按照指令的顺序执行的。在这种设备中,内存中的所有访问都被视为顺序访问,即一个访问必须在前一个访问完成后才能开始。因此,在Strongly-ordered device中,所有的指令和数据访问都是按照其在代码中的顺序执行的,而且不会发生乱序执行的情况。
在嵌入式系统中,Strongly-ordered device通常用于对外设进行访问,例如对于硬件设备的寄存器和存储器的访问。由于Strongly-ordered device的特性,它们通常比其他类型的设备具有更高的可预测性和可靠性,因为它们可以保证操作的有序性和确定性,从而减少了系统中出现的不确定因素和错误。
同时,需要注意的是,在Strongly-ordered device中,由于所有的操作都是按照指令的顺序执行的,因此执行速度可能会比其他类型的设备慢一些。因此,在设计嵌入式系统时需要根据实际需求选择不同类型的设备,以获得更好的性能和可靠性。
2. 一致性模型
一致性模型并非是CPU的专属概念,文献3中提到“微信朋友圈的评论系统最适合什么一致性模型?”,从回答中可以看出,微信评论要实现多终端、多地点的同步显示,就要保持多个客户端和服务器之间的一致性。我们CPU的角度来看,现代处理器的多层级的内存结构,能够保持处理器对存储子系统访问的一致性是研究点。在一个系统中有n个处理器p1~pn,假设每个处理器包含Si个存储器操作,这些存储器操作都没有依赖关系,那么这些操作按照乱序执行的原则,有可能的执行序列有Si个排列组合的可能性,因此,这个规则不可能让其随即组合随心所欲,我们需要制定一个规则来制约乱序执行的排序,这里引入的一致性模型,就是做这样的工作的。
2.1 顺序一致性内存模型
在一个单核系统中,保证系统一致性比较简单,每次存储器操作只要关注于最近的写入的结果。然而在多核系统中,保证一致性就变成了一个需要兼顾多因素的情形了,这个因素被拆解为:
- 第一,如何保证自己核中的存储一致性问题?
- 第二,如何保证对方核中的存储一致性问题?
第一个问题还是比较简单的,自己核中的一致性只要关注最近写入的结果就可以了。然而第二个问题,可能要引入一个全局时间比例(global time scale)部件来决定存储器访问的时序,从而判断最近访问的数据(相对于划分了一个时间尺度,在这个时间尺度内判断最近访问的数据)。我们称为这种内存一致性是严格一致性(atomic consistency)内存模型,也成为原子一致性(atomic consistency)模型。实现全局一致性代价太大,因而退而求此次,采用每一个处理器内部**局部时间比例(local time scale)**部件来确定最新数据,我们称为“顺序一致性(sequential consistency, SC)内存模型”。该模型对应两个一致性可以总结为两个约束条件:
- 对于自己核,保持严格的一致性。
- 对于对方核,所有内存访问都是原子性的,执行顺序不必遵循时间顺序。
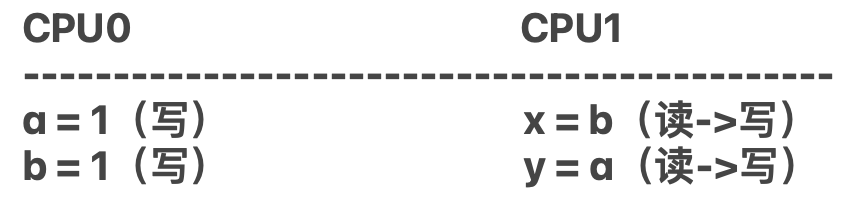
比如现在有CPU0和CPU1两个核进行运算,CPU0两次写的操作,CPU1虽然是两条语句,但实际上是4步操作,读写读写。他们采用顺序一致性原则,那么这个规则如下:
- 在CPU0内两次写保持严格的一致性。如果CPU1的x值被赋值为1,那么必然CPU0中a=1已经执行完成,因为在CPU0内部需要保证一致性。
- 在CPU1内读写读写顺序保持严格的一致性。
可以看出,顺序一致性对于核内顺序要求十分严格,这个也是开发者理想中的操作,如果处理器都采用顺序一致性模型,那就不存在内存屏障的问题,但是这样效率会下降很多。
2.2 处理器一致性模型
处理器一致性模型(Processor Consistency, PC)内存模型是顺序一致性模型的“弱化”版本,这个“弱化”如何理解?可以理解为放松约束条件。那么放松哪个条件呢?
- 在CPU0内两次写保持严格的一致性。如果CPU1的x值被赋值为1,那么必然CPU0中a=1已经执行完成,因为在CPU0内部需要保证一致性。
在CPU1内读写读写顺序保持严格的一致性。 变更为:在CPU1内保持两次写的一致性,对于两次读没有一致性要求,可能出现乱序执行。
在x86_64处理器上实现的**全序写(Total store ordering,TSO)**模型就是处理器一致性模型。
2.3 弱一致性模型
对处理器一致性模型进行进一步弱化,对!你没有听过,再弱化。不禁想问,那还有什么一致性可言。在某种程度上,我觉得弱一致性原则=没有一致性约束条件。为了达到预期的正确的结果,那么就不得不去手动去保证一致性了。
在CPU0内两次写保持严格的一致性。如果CPU1的x值被赋值为1,那么必然CPU0中a=1已经执行完成,因为在CPU0内部需要保证一致性。变更为:在CPU0内部不需要保证严格的一致性,可以乱序执行。在CPU1内读写读写顺序保持严格的一致性。在CPU1内部对于读写读写的顺序不做要求,可以乱序执行。
这种完全没有一致性的模型,给我们这些做软件的人填了不少的麻烦,这也是出现内存屏障和一些维护序的根本原因。因为ARM64为了追求更高的性能,采用的就是弱一致性模型。
CPU设计人员给了我们一些同步手段,可以把一个处理器的存储访问想要发生在另一个处理器存储访问之后,这里的手段就是内存屏障指令。对于内存访问我们可以归类为以下几种模式:
- 共享访问(读):多个处理器同时并发地访问同一个变量。(安全的)
- 竞争访问(包含至少一方的修改):多个处理器同事并发地访问同一个变量,其中至少有一个行为是写操作,因此在这种情况下存在竞争访问。这个很好理解,一个写操作之前和之后两个时间节点观测数据,会有两种不同的结果。因此就是产生竞争访问的时候就需要有序的要求(意味着,需要手动去进行同步两个核之间的操作,解决两者的竞争矛盾)
在ARM64中提供了 A.数据访问指令和 B.同步指令(内存屏障指令),以应对弱一致性模型中出现的序的问题。1986年,Dubois定义了弱一致性模定义,他使用内存屏障的指令来描述弱一致性模型的定义:在一个多处理器中,满足如下三个条件的内存访问称为若一致性的内存访问:
- 屏障指令的执行是顺序的。
- 在屏障指令之前的所有数据访问必须全部完成。
- 一个正常的数据访问可以在执行前,所有以前的同步访问(内存屏障指令)必须完成。
这个定义十分的抽象,我们会在ARM64的内存屏障指令中解读定义。
3. ARM64内存屏障
3.1 软硬分工
ARM64体系结构使用的是弱一致性模型。基于弱一致性模型,CPU的load和store操作的序列可能会和程序员编写的并不一致。但是ARM64并没有说不负责任的把所有的工作推给程序员来做。因此,在ARM64的硬件上集成了一些机制以弥补弱一致性带来的编程者手动维护缺陷。这些机制包含:
- 从内存中预取数据或者指令。
- 预测指令预取。(包含nornal memory和device memory)
- 分支预测(branch prediction)
- 乱序的数据加载(out of order data load)
- 预测的高速缓存行填充(speculative cache line fill)
- LSU(Load store unit),加载存储单元
- 存储缓冲区
- 无效队列
- 与内存相关的子系统
这些机制似的我们作为ARM的程序开发者并不需要特别在意内存屏障的问题,甚至在单核处理器下面根本不需要考虑内存屏障的事情(除非这部分代码需要和多和场景的情况复用),但最终的CPU会保证执行的结果是符合预期的,程序员更多的是需要知道在一些场景下考虑合适的内存屏障指令。这里提及:
-
在多个CPU内核之间共享数据的时候,且处理器属于弱一致性内存模型,某个CPU乱序执行指令次序会发生竞争。
-
在执行和外设相关的操作,如DMA操作,防止DMA传输错误的数据:
- 第一步,数据会被写入DMA的缓冲中;
- 插入barrier。(如果这一步没有内存屏障指令,第二步相关的寄存器可能执行在第一步之前,那么DMA就会搬运旧数据)
- 第二步,设置DMA相关的寄存器来启动DMA传输;
-
修改内存管理策略,例如上下文切换、请求缺页及修改页面属性。
-
修改存储指令的内存区域,例如自修改代码场景。
3.2 内存屏障指令
ARMv8-A提供了3条内存屏障指令,这些屏障指令范围
-
数据存储屏障(Data Memory Barrier, DMB)
-
数据同步屏障(Data Synchronization Barrier, DSB)
-
指令同步屏障(Instruction Synchronization Barrier, ISB)
-
融入到新的加载存储指令的,单方向的内存屏障(acquire\release\load-acquire\store-release)
3.2.1 DMB
仅当所有在它之前的存储器访问操作执行完毕之后才提交在它后面的访问指令(注意,仅针对存储操作,因此不能保证任何指令)。存储操作包含,load,store,还有一些d-cache维护的操作。
1: Do A instruction
2: Do DMB
3: Do B instruction
我们在A指令和B指令中间使用DMB,那么就要求B指令能够观察到A指令的执行结果,而A和B不会被乱序执行影响,B跑到A的前面。DMB指令是可以携带一些参数的。
举例 1:CPU执行一下指令:
无依赖关系会导致乱序
ldr x0, [x1] str x2, [x3]这是一个比较简单的ldr和str指令,而且从寄存器侧可以看到,两条语句没有互相依赖的关系(地址依赖或者数据依赖),因此str有可能执行在ldr之前,在执行的时候这个序的问题就可以是一个“薛定谔状态——执行的时候才知道顺序。那么如果我们想打破“薛定谔状态”就可以使用DMB指令。
使用DMB内存屏障
ldr x0, [x1] DMB ish str x2, [x3]此时,薛定谔状态被打破,ldr指令必然在str指令之前执行。
有依赖关系不会导致乱序
ldr x0, [x1] str x2, [x0]这个指令有数据依赖关系x0,因此不会被打乱执行。
非存储指令的DMB免疫
另外对于非存储操作就会对于DMB“免疫”:
ldr x0, [x1] dmb ish add x2, x3, x4 str x2, [x3]add的语句依然有机会跳到ldr之前执行,因为add并非存储操作。
cache维护要记得使用内存屏障
针对于cache指令要小心,因为cache会刷新数据或者指令,那么cache操作之后的指令乱序到cache维护之前,那么就可能拿到的是旧的指令或者数据,因此cache维护之后的操作,需要用dmb隔离开来。
dc cvac, x6 ldr x0, [x1] dmb ish str x2, [x3]
3.2.2 DSB
DSB指令要比DMB严格多,DSB仅仅针对于存储指令,而DSB作用范围有所提升,但是要注意,随着指令的严格及范围扩大,波及的CPU机制会越来越多,那么性能也会越来越慢。严格不一定是好事。DSB后面的任何指令必须满足下面两个条件才能执行:
- DSB指令前面的所有数据访问指令(内存访问指令)必须完成。
- DSB指令前面的高速缓存、分支预测、TLB等维护指令必须执行完成。
与DMB相比,DSB指令规定了DSB指令在什么条件下可以执行,而DMB指令仅仅约束屏障前后的数据访问执行次序。
示例2:
使用dsb指令,add指令必须要等到dsb执行完毕之后才能开始执行,不能重排到ldr前面。
ldr x0, [x1] dsb ish add x2, x3, x4cache维护指令,dc清空x5寄存器内存储虚拟地址的对应空间,使其失效。dsb指令限制,dc和ldr必须在dsb之前完成之后才能执行add。
dc civa x5 ldr x0, [x1] dsb ish add x3, x3, x4在一个multicore的系统中,cache和tlb维护指令会广播到其他CPU单元。DSB指令等待这些广播并收到应答信号才算执行完成。所以,当DSB指令执行完成时,其他CPU内核已经看到第一条DC指令执行完。
DSB和DMB的参数
A. 作用域
DMB和DSB后面是可以带参数的,用于指定共享属性域以及具体的访问顺序:
- 全系统共享(Full System Shareable)域
- 外部共享(Outer Shareable)域
- 内部共享(Inner Shareable)域
- 不指定共享(Non-Shareable)域
B. 读写访问before-after(访问)
除了指定内存屏障共享属性和具体的访问顺序,可以根据参数指定读写行为、读写方向:
- 读内存屏障(Load-Load/Store)指令
- 参数后缀为LD:指示在内存屏障指令之前所有的加载指令必须完成,但是对存储指令不做要求。
- 写内存屏障(Store-Store)指令
- 参数后缀为ST:指示在内存屏障指令之前所有的存储指令必须完成,但是对加载指令不做要求。
- 读写内存屏障(Any-Any)指令
- 参数后缀为SY:指示在内存屏障指令之前所有的存储+加载指令必须完成。
具体从参数介绍和使用参考4:
Several options can be specified with the
DMBorDSBinstructions, to provide the type of access and the shareability domain it applies to, as follows:
- SY
This is the default and means that the barrier applies to the full system, including all cores and peripherals.
- ST
A barrier that waits only for stores to complete.
- ISH
A barrier that applies only to the Inner Shareable domain.
- ISHST
A barrier that combines ST and ISH. That is, it only stores to the Inner Shareable.
- NSH
A barrier only to the Point of Unification (PoU). (See Point of coherency and unification).
- NSHST
A barrier that waits only for stores to complete and only out to the point of unification.
- OSH
Barrier operation only to the Outer Shareable domain.
- OSHST
Barrier operation that waits only for stores to complete, and only to the Outer Shareable domain.
3.2.3 ISB
ISB指令是最严格的,会flush掉流水线中已经装载的指令和数据,(我理解用时会重新从存储设备中装载)。那么什么时候使用这个严格的ISB指令呢?在ARMv8中,有个术语叫做更改上下文操作(Context-changing operation)。更改上下文操作包含cache、TLB、分支预测等维护以及改变系统控制寄存器操作。使用ISB确保在ISB之前执行的上下文更改操作的效果对在ISB指令之后获取的指令是可见的。更改上下文操作的效果仅仅在上下文同步事件(context synchroniztion event)之后能看到。上下文同步事件包括:
- 发生一个异常(exception)
- 从一个异常中返回。
- 执行了ISB指令。
发生上下文同步事件产生的影响包括:
- 在context同步事件发生时挂起所有的未屏蔽中断都会在context同步事件之后的第一条指令之前处理。
- 在触发context changing指令后面所有的指令不会执行,直到上下文同步时间处理完。
- 在context同步事件之前完成的使TLB失效、指令高速缓存以及分支预测操作,都会影响context同步时间后面出现的指令。比如,如果在上下文同步时间之前完成了使指令缓存失效的操作,那么在上下文同步之后,CPU会从Icache中重新取指令,相当于把流水线之前预取的指令清空。
- 修改系统控制器通常是需要ISB指令的,但是并不是修改所有系统寄存器都需要ISB指令,比如PSTATE寄存器修改就不需要ISB指令。
举例1:CPU执行如下代码打开FPU功能。
把cpacr_el1的bit[21:20]设定为0x3,打开浮点运算的功能,但是如果马上执行fadd指令就可能会发生异常,因为这个指令是一个预加载到流水线的旧指令,执行旧指令在这种配置下是有风险的。因此需要刷掉流水线中所有的指令和数据,这样才能确保是在新的配置下拿到的数据。
mrs x1, cpacr_el1 orr x1, x1 #(0x3 << 20) msr cpacr_el1, x1 isb fadd s0, s1, s2举例2:改变页表项。
str x10, [x1] // x1内是页表的地址 dsb ish // dsb指令保证str执行完成 tlbi vaelis, x11 // 使tlb失效 dsb ish //dsb指令保证tlb失效完成 isb这里的ISB是触发一个上下文同步的事件,保证ISB后面的指令可以看见前面的变更,并且从内存中预取指令到流水线中。
举例3:自修改代码。
自修改代码顾名思义,就是当代码执行的时候会修改自己的指令。因此修改的指令需要注意,需要不断的维护cache和内存屏障指令。
// CPU 0 str x11, [x1] // x1执行代码存储的地方,这里STR指令修改和更新最新代码 dc cvau, x1 //清理x1地址的d-cache,把x1对应的数据高速缓冲写回到x1指向的地址 dsb ish //dsb指令保证dc执行完成,这里所有的cpu都能看见这个结果 ic ivau, x1 // 使icache失效, 不需要使用内存屏障因为x1有依赖性 dsb ish //保证cpu都能观察到icache失效 str x0, [x2] // x2表示标志位,设定标志位为1, 通知其他cpu代码已经更新。 isb // 保证cpu0从cache中预取的最新的指令 br x1 //跳转到最新的代码中// CPU1 WAIT (x2 == 1) // 等待标志位 isb // 刷新自己的流水线 br x1 // 跳转最新代码
3.2.4 单向内存屏障
ARMv8指令集还支持隐含内存屏障操作的load和store的指令,这些内存屏障影响加载的执行顺序,按照方向可以分为:
-
获取(acquire):该屏障原语之后的读写操作不能重排到屏障指令的前面,通常该屏障指令和加载指令相结合。
-
释放(release):该屏障原语之后的读写操作不能重排到屏障指令的后面,通常该屏障指令和存储指令相结合。
-
加载-获取(load-acquire):包含acquire的操作,相当于单方向向后的屏障指令。
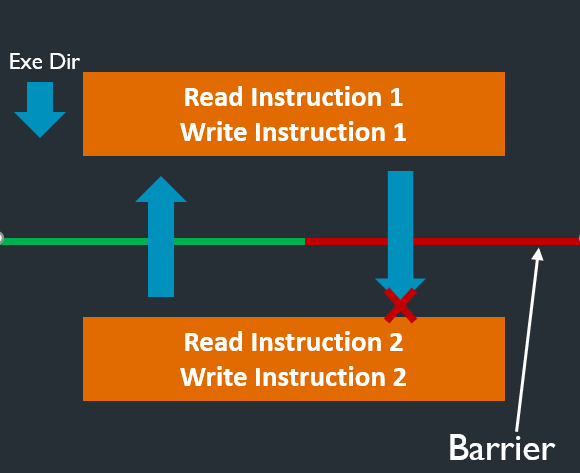
- 存储-释放(store-release):包含release的操作,相当于单方面向前的屏障指令。
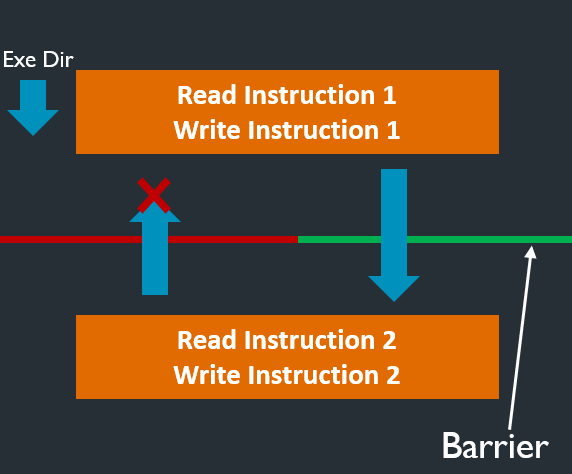
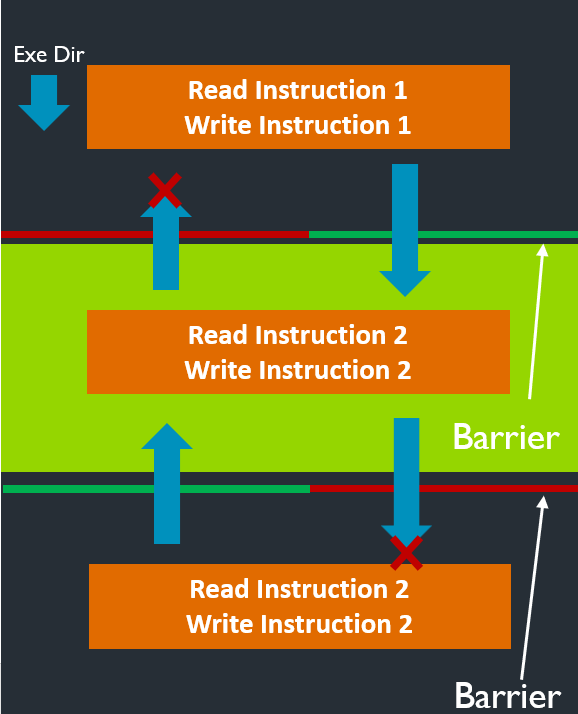
store-release和load-acquire可以组成一个临界区(绿色位置),相当于一个栅栏。
这些指令是5:
- LDR, LDRB, LDRH, LDRSB, LDRSH, LDRSW (immediate, not literal).
- LDUR, LDURB, LDURH, LDURSB, LDURSH, LDURSW (immediate).
- LDTR, LDTRB, LDTRH, LDTRSB, LDTRSH, LDTRSW (immediate).
- LDAR, LDARB, LDARH, LDXR, LDXRB, LDXRH, LDAXR, LDAXRB, LDAXRH.
- LDXP, LDAXP.
- STR, STRB, STRH (immediate)
- STUR, STURB, STURH (immediate).
- STTR,STTRB, STTRH (immediate).
- STLR, STLRB, STLRH, STXR, STXRB, STXRH, STLXR, STLXRB, STLXRH.