03_ARMv7-M_存储系统结构
carloscn opened this issue · comments

1. Overview
Cortex-M是32位的处理器,因此处理器能够寻址到4GB的地址空间。M-CPU采用的是哈佛结构,因此数据空间和指令空间在同一个空间维度。这些空间被分为多个区域,后面会介绍memory map。关于M核的存储系统,有以下比较重点features:
- 多总线接口允许指令和数据并发访问地址空间。
- AMBA总线协议
- 大小端存储都支持
- 支持非对齐的数据传输
- 支持排他访问(操作系统的信号量)
- 比特级的内存访问宽度
- 内存属性和访问权限的配置(指定区域)
- MPU
2. Memory Map
4GB的寻址空间,一部分被内部的外设预留,作为外设访问的地址空间,例如NVIC和一些调试的组件。这些外设的预留的空间都是固定的。还有一部分的空间被分配如图:

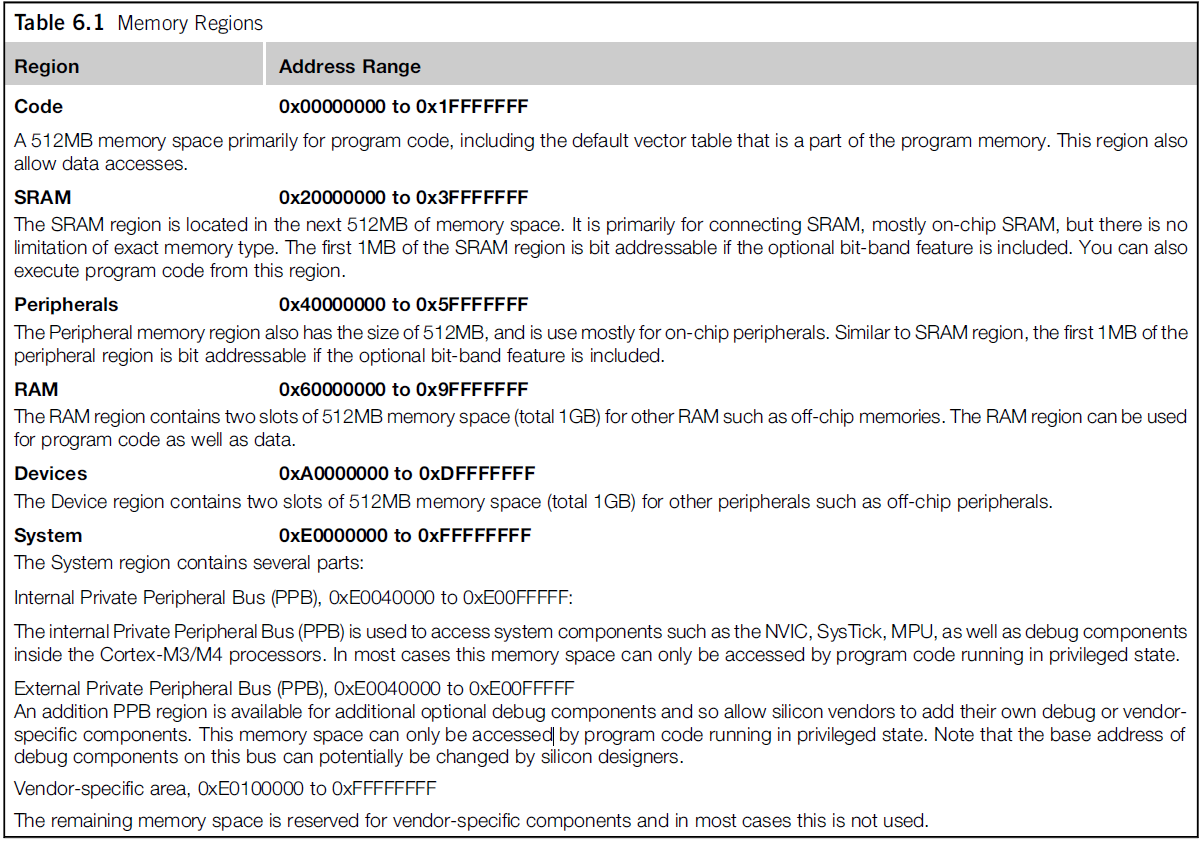
这样的分配:
- 处理器这样设计是为了支持多种内存,并且对于二级厂家开箱即用。
- 内存的分区编排也是为了提更高的性能;
在ARM公司层面,给出memory map只是一个参考建议,对于数字芯片设计者,他们可以根据自己的case来对内存进行设计。对于NXP,ST的这些ARM芯片,他们都是有自己的memory map的。ARM提供的仅仅是一个很简单的内存映射的demo。
大致上分为:
- Code区域(低地址:0-1FFF_FFFF):512MB的空间,包含默认的向量表和部分程序。这部分允许数据访问(写:写入程序;读:CPU读指令);
- SRAM(2000_0000-3FFF_FFFF):512MB的空间,通常是on-chip RAM,可以从该位置执行程序;
- 外设(4000_0000-5FFF_FFFF):512MB的空间,通常是on-chip 外设区域;
- RAM(6000_0000-9FFF_FFFF):1GB的空间,off-chip内存,可以存储数据,也可以执行程序;
- Devices(A000_0000-DFFF_FFFF):512MB空间,off-chip外设区域;
- System(E000_0000-FFFF_FFFF):系统区域
- IPPB(内部私有外设总线)用于访问系统组件例如NVIC和SysTick和MPU等。
- EPPB(外部私有外设总线)用于下游厂商加入自己的IP
参考STM32F37xxx的手册中的memory map章节,可以看到意法半导体也基本follow ARM的原生设计:

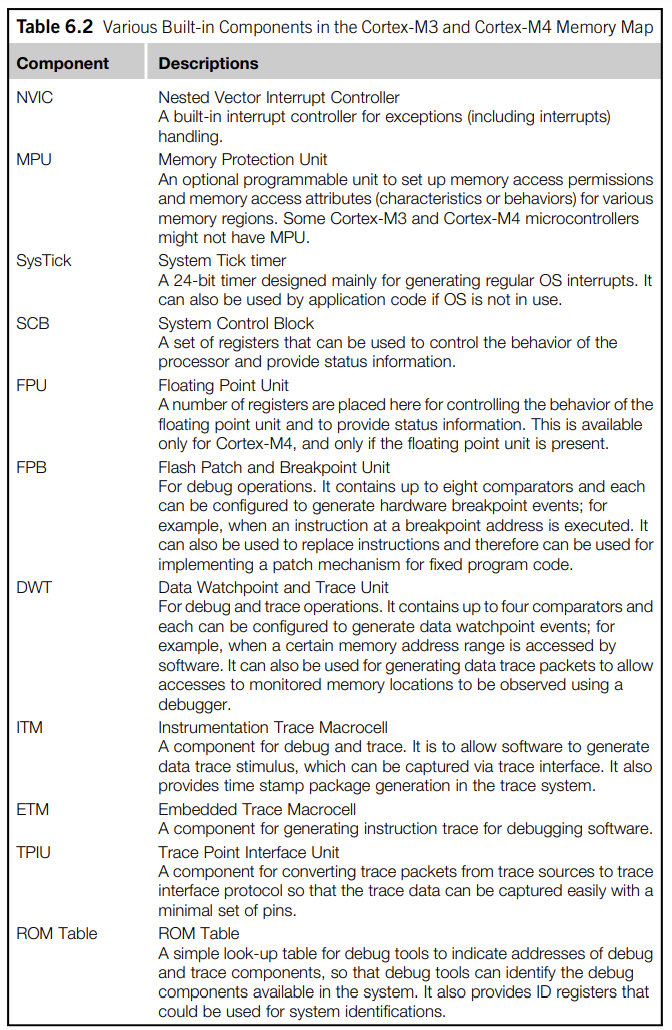
我们通常都会把执行的程序存储到RAM或者SRAM上,CPU在执行的时候从RAM里面读取指令然后执行。不过从memory map上看,显然这个是笨拙的,因为要花费额外的时钟周期从RAM中读取指令,远不如从地址总线的内存区域直接读取。但是要知道,地址总线映射区域并不是存储空间,是无法执行程序的。因此,这里就引出了地址属性的概念。对于NVIC与MPU和SCB,这些系统外设占用的空间叫做System Control Space (CSC)。
一些系统组件如图所示:
3. 内存+外设与处理器如何连接
ARM使用AMBA来对内存和外设进行连接,AMBA中还包含多种总线协议,应对不同场景,不同的处理器访问对象。
- AMB Lite Protocal:干路总线的接口
- APB Protocal: 用于PPB,访问调试组件

为了获取更好的性能,CODE区域和其他的总线访问分开,这样的意图也是数据访问和取址能够并行执行。
还有一个好处就是,分开的总线能够提高中断的响应效率,试想,在应用层经常出现,在中断处理一个queue的时候,处理器需要进入栈空间的访问vector table读取中断的地址信息,如果总线分开之后可以并行进行处理。
处理器的总线接口有一个等待机制,这个等待机制就位不同速率的存储提供了一个可能,例如处理器处于高速运行状态,当访问速率较低的内存或者速度较慢的外设的时候,该等待机制可以让处理器从总线接口获取等待数据的状态,因此可以引入更多的逻辑来处理高低速不平衡的use case。
处理器总线还有一个error response机制,在总线层级就可以检测内存的合法性,如果访问一个非法区域的空间,总线就会返回一个错误,无需处理器来做判断处理,只需从总线拿到错误汇报即可,减少了CPU的负担。
以上的好处都是得益于总线协议。一个简单的处理器,访问指令空间使用I-CODE和D-CODE总线,而SRAM和外设都接入到系统总线上,如图所示:
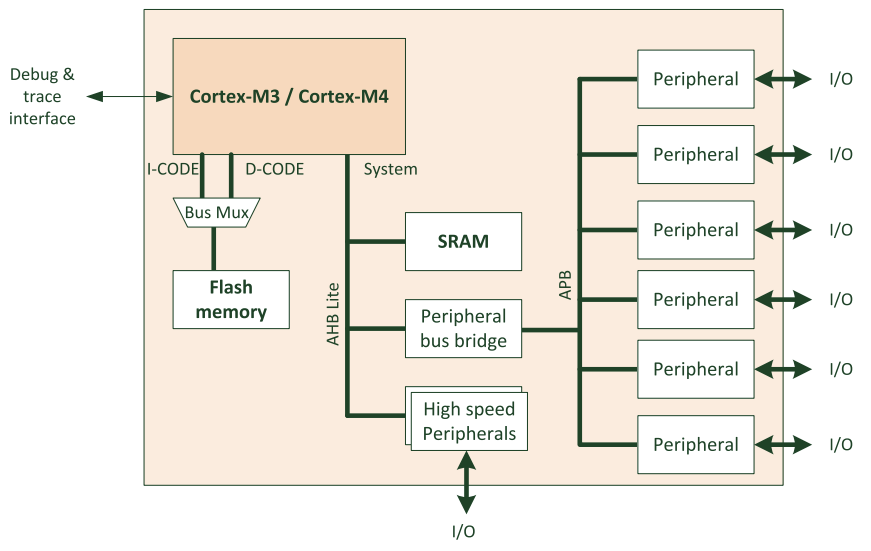
我们可以从这个图看到,低速的外设通过总线桥(APB)接入到系统总线(AHB Lite),高速器件都是直接接入到系统总线(AHB Lite)上。这样做的目的是对于不同速率的外设访问一致性的优化,可以最大程度的区分开高速和低速器件,使访问效率以及带宽达到最高。例如DMA属于高速器件,DMA直接使用系统总线,对于USB和网卡的高速数据,都是使用系统总线进行传输。
还需要注意PPB不能用于不同的外设,PPB更像是ARM自己使用的简单高效的工具,但是没有太强的保护措施,所以相比于外设的总线:
- PPB 是CPU私有化的访问;
- 只能够32位访问,无法使用bit级的访问粒度;
- PPB写入需要更多的时钟周期,而且没有写入的缓冲区(针对于Strongly-Ordered设备);
- 只能是小端访问,外设总线可以配置为小端或者大端模式;
I-CODE和D-CODE总线提供程序的访问。在比较简单的处理器demo中(ARM的设计),两个总线能够被一个BUS MUX混合到一起。二级厂商也能够使用这两条总线来开发定制化flash的访问的加速器,这样允许处理器更快的访问flash memory。

对于意法半导体的Embedded Flash memory的设计,就是用了该方法:


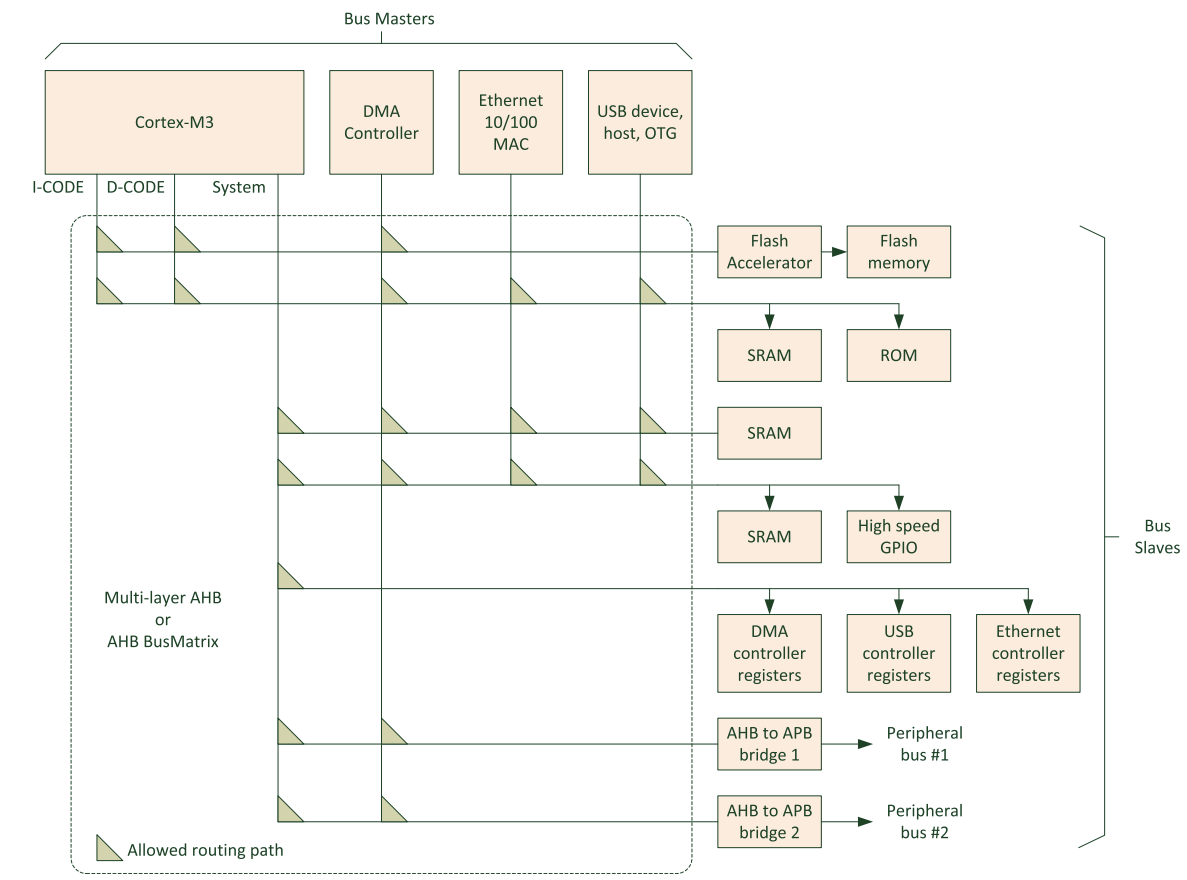
在很多M3和M4的产品中,有很多设计能够找到muliple bus masters的身影,例如DMA,以太网和USB这些高速器件。二级厂商喜欢用“bus matrix” or “multi-layer AHB”来描述。如图所示:
4. 内存要求
不同种类的内存能够使用相应的内存接口逻辑和AHB Lite总线连接。尽管总线是32位访问宽度,但是访问的时候还是可以以不同的位宽进行访问,例如(8/16/64/128等)。
尽管市面上有很多种类的RAM,比如SRAM和RAM或者是PSRAM,SDRAM,DDR RAM。对于处理器而言,对于RAM的类型没有限制。针对于ROM空间也是,无所谓FLASH、EEPROM还是OTPROM。只有一点,访问的内存必须是可以寻址的,而寻址的宽度必须要支持byte,半word,一个word这些宽度的访问。
5. 大小端
Cortex-M3/M4支持大端模式也支持小端模式。在默认情况下,使用的是小端模式。但在一个power-cycle只能有一种模式的存在。换句话说,处理器在复位的时候会决定自己是在小端模式还是在大端模式,一旦被设定,大小端模式就不能被更改,除非处理器复位。
在极少数的use case中,一些外设寄存器,混合使用大小端模式。在这种case中就需要软件工程师在编写程序时,通过软件的手段妥善处理数据,对数据进行大小端的转换,让其从寄存器中读取到正确的数据。
通过union来确定是不是大端:
#define IS_BIG_ENDIAN (!(union { uint16_t u16; unsigned char c; }){ .u16 = 1 }.c)转换:
uint32_t ntohl(uint32_t n)
{
unsigned char *np = (unsigned char *)&n;
return ((uint32_t)np[0] << 24) |
((uint32_t)np[1] << 16) |
((uint32_t)np[2] << 8) |
(uint32_t)np[3];
}以下是存储32位的大端小端在内存中存储的字节序:

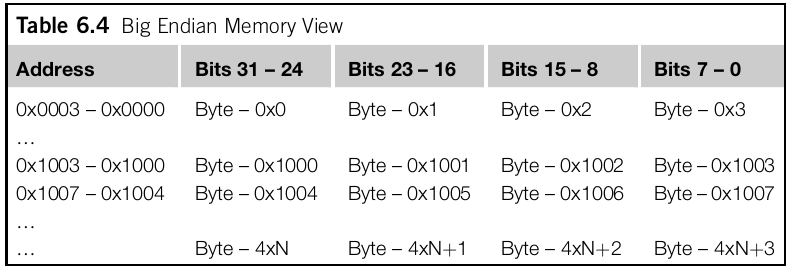
在M处理器中,大端的存储形式被叫做byte-invariant big endian, or BE-8被v6, v6-M, v7, and v7-M所支持。在经典ARM处理器中,大端的存储形式被叫做word-invariant big endian, or BE-32. 他们在内存排布的方式是一致的,区别就在于AHB总线传输方面。 具体参考: https://developer.arm.com/documentation/ddi0344/k/programmers-model/memory-formats/byte-invariant-big-endian-format
关于ARM大小端模式和CPU有关还是编译器有关
结论,ARM大小端模式和CPU有关也和编译器有关系。ARM默认状态配置为小端模式,编译器不指定编译模式也默认是小端模式。但有些ARM是可以配置为大端模式的。例如:
- ARMv7-A: In ARMv7-A, the mapping of instruction memory is always little-endian.
- ARMv7-R: SCTLR.IE, bit[31], that indicates the instruction endianness configuration.
- ARMv7-M: Armv7-M supports a selectable endian model in which, on a reset, a control input determines whether the endianness is big endian (BE) or little endian (LE). This endian mapping has the following restrictions: The endianness setting only applies to data accesses. Instruction fetches are always little endian. All accesses to the SCS are little endian, see System Control Space (SCS) on page B3-595.
- ARMv8-aarch32: aarch32: When using AArch32, having the CPSR.E bit have a different value to the equivalent System Control register EE bit when in EL1, EL2, or EL3 is now deprecated
- ARMv8-aarch64: aarch64: This data endianness is controlled independently for each Execution level. For EL3, EL2 and EL1, the relevant register of SCTLR_ELn.
如果在ARM上面配置了大端模式,gcc编译器则需要增加参数
-mbig-endian-mlittle-endian
Generate code for a processor running in little-endian mode. This is the default for all standard configurations.
-mbig-endian
Generate code for a processor running in big-endian mode; the default is to compile code for a little-endian processor.
与CPU配置保持一致。https://gcc.gnu.org/onlinedoc...
https://developer.arm.com/doc...
https://developer.arm.com/doc...
对于M系列的CPU:
- 处理器取指令总是使用小端模式;
- 访问E000_0000 - E00F_FFFF的
System Control Space (SCS),调试模块还有PPB总线总是使用小端模式; - 指令REV, REVSH, and REV16可以转换大小端数据;
6. 数据对齐和非对齐访问
内存系统是32位的,则一个数据的访问可以是32位的(4字节,或一个字),或者16位的(2个字节,半个字)。从编程者的角度,这个数据的访问可以是对齐的,也可以是非对齐的。对齐的数据传输意味着地址是字节大小的倍数。例如,一个32位的数据传输能够被搬移到地址 0x0000_0000, 0x0000_0004,... , 0x0000_1000(这些地址都是32位对齐的,可以整除32);一个16位的数据可以被移动到0x0000_0000,0x0000_0002,0x0000_1000,0x0000_0002。
下面的图表示非对齐和对齐数据传输的实例:
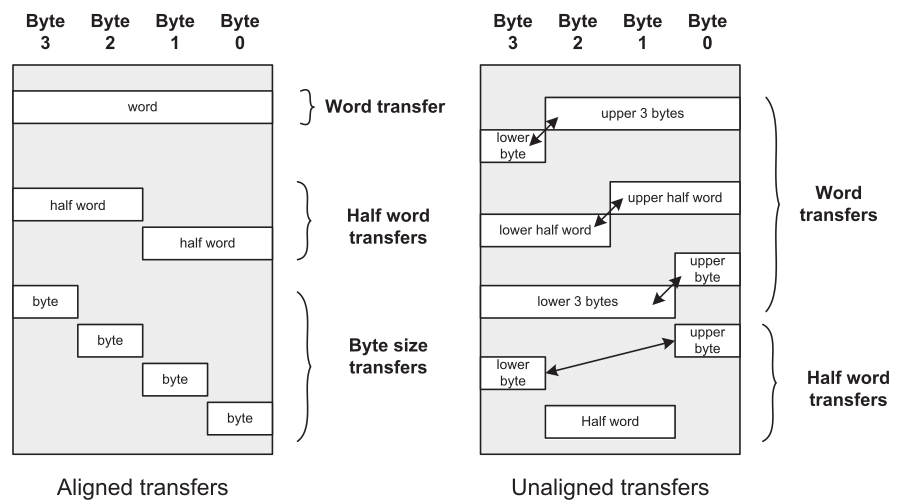
在经典的ARM处理器中,仅仅允许对齐的数据传输。从数据地址规律来看,32位的对齐数据,地址1比特位和地址0比特位都是0;一个16位的数据地址0比特位是0。(ARM就是通过这个方法来检测数据对齐异常的)。
Cortex-M3和Cortex-M4在架构层级就支持非对齐的数据传输,使用LDR,LDRH,STR,STRH指令就可以完成。但是这些指令也有一些限制:
- 非对齐的访问不支持Load/store多条指令;
- Stack的操作(PUSH/POP)必须对齐;
- 独占访问(Exclusive accesses)
LDREX和STREX必须对齐;否则 ,就会发生异常; - 非对齐的数据不支持bit-band级别的内存操作
还需要注意的是,在处理器层面,对于非对齐的操作本质上是拆分成多个对齐的操作进行处理。在软件层面的确是不需要关心数据是否对齐了,然而,对于处理器而言,非对齐数据需要增加额外的开销,因此,如果要达到最好的性能,需要让数据对齐。
在编译器层面,编译器会对数据进行优化,不去产生非对齐数据访问。因此非对齐访问发生在:
- 直接使用指针操作数据;
- 访问一个数据结构体
__packed属性,且这个结构体中包含非对齐的数据; - Inline 内嵌汇编程序。
我们也可以对M处理器进行配置,让其不支持非对齐数据的访问,行为是当发生非对齐的内存访问,就会发生一个非对齐的异常。通过UNALIGN_TRP (Unaligned Trap) 比特位在CCR上面(Configuration Control Register,0xE000_ED14)在SCB上。
7. bit级访问
在 Cortex-M3 和 Cortex-M4 处理器中,引入 Bit-banding 操作是为了提高对于特定寄存器或内存位操作的执行效率。Bit-banding 可以让单个位的读写操作变得更加高效。
在传统的寻址方式中,要对某个位进行操作,需要对整个字或半个字进行读取、修改、写入操作。而对于特定寄存器或内存位的 Bit-banding 操作则可以将这个单独位映射到一段物理地址空间内,这段地址空间和原始内存地址是等价的。这样,在进行位操作时,可以通过直接访问 Bit-banding 区域的物理地址来实现对于单个位的操作,而无需进行读取和修改整个字或半个字的操作。
通过使用 Bit-banding 操作,可以提高对于特定寄存器或内存位操作的执行效率,同时也可以减少程序代码的复杂度。
bit-band操作能够支持load/store访问一个数据位(bit)。但并不是针对所有地址,在M3和M4中,仅支持在两个预定义的内存区域(bit-band regions)才能够使用bit-band操作。这区域是:
- SRAM 开始的1MB区域;
- 外设开始的1MB区域;
下面是一个实例,在普通的内存区域,1个地址可以访问到的数据长度是32位的,而在bit-band区域,对地址进行了重定义,重定义后的地址叫做bit band alias address,使之增加1个地址,访问的数据长度只有1bit。
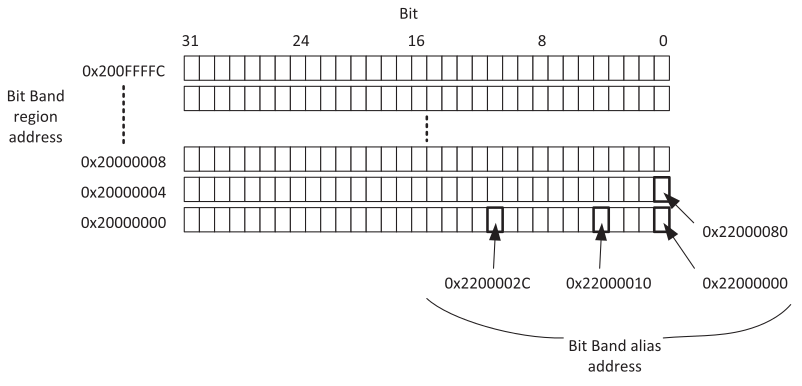
例如,当我们设定一个在2000_2000地址32位的数据的两个bit位,如果是没有bit访问的,那么需要把32位数据从地址中读取出来,修改值,接着把32位数据回写到地址上。但是这三个步骤对于bit-band而言只需要一步指令。

注意,我们在C语言中访问的地址,实际上是操作的总线,而具体访问什么,需要看总线映射的是什么。可能是一个寄存器,也可能是一段SRAM。所以访问地址前需要映射。
我们从汇编的角度来看一下访问的区别,对于没有bit操作的数据访问是:
LDR R0,=0x20000000
LDR R1, [R0]
ORR.W R1, #0x4
STR R1, [R0]而对于有bit访问的操作:
LDR R0,=0x22000008
MOV R1, #1
STR R1, [R0]需要注意的是,Cortex-M3 and Cortex-M4处理器使用下面的条件对于bit-band内存地址:
- Bit-band region:这个内存区域支持bit-band操作
- Bit-band alias:bit-band访问的地址(因为存储宽度不一致,内存会重新被映射)
进行bit-band操作的区域是:
- 0x20000000e0x200FFFFF (SRAM, 1MB)
- 0x40000000e0x400FFFFF (Peripherals, 1MB)
下面是bitband的一些使用实例:
- 串行访问GPIO口的时候,bit-band发挥很大空间;
- 读一些状态寄存器的标志位的时候,可以只读一个bit,而不需要把整个状态寄存器读出来;
- 避开一些竞争的场景。由于READ-MODIFY-WRITE操作属于硬件级别操作,是原子操作。试想A读了寄存器然后修改某个值,此时B修改者先写入了自己的值返回,接着A回写寄存器,此时A把B的值覆盖掉了。
- 对于一些bool定义,处理器可以专门分配一个区域,此时一个bool值只占1个比特位。
在C语言中,C特性无法支持bit-band的操作。因为C语言无法区分开地址到底是bit-band还是word-band。为了在C语言上使用bit-band的feature,不得不去做一些处理。
#define DEVICE_REG0
*((volatile unsigned long *) (0x40000000))
#define DEVICE_REG0_BIT0 *((volatile unsigned long *) (0x42000000))
#define DEVICE_REG0_BIT1 *((volatile unsigned long *) (0x42000004))
...
DEVICE_REG0 = 0xAB; // Accessing the hardware register by normal
// address
...
DEVICE_REG0 = DEVICE_REG0 | 0x2; // Setting bit 1 without using
// bit-band feature
...
DEVICE_REG0_BIT1 = 0x1; // Setting bit 1 using bit-band feature
// via the bit-band alias address// Convert bit-band address and bit number into
// bit-band alias address
#define BIT BAND(addr,bitnum) ((addr & 0xF0000000)+0x2000000+((addr &
0xFFFFF)<<5)+(bitnum <<2))
// Convert the address as a pointer
#define MEM_ADDR(addr) *((volatile unsigned long *) (addr))
#define DEVICE_REG0 0x40000000
#define BIT BAND(addr,bitnum) ((addr & 0xF0000000)+0x02000000+((addr &
0xFFFFF)<<5)1(bitnum<<2))
#define MEM_ADDR(addr) *((volatile unsigned long *) (addr))
.
MEM_ADDR(DEVICE_REG0) = 0xAB; // Accessing the hardware
// register by normal address
.
// Setting bit 1 without using bit-band feature
MEM_ADDR(DEVICE_REG0) = MEM_ADDR(DEVICE_REG0) j 0x2;
.
// Setting bit 1 with using bit-band feature
MEM_ADDR(BIT BAND(DEVICE_REG0,1)) = 0x1;从编译器层面, __attribute__((bit band)) 特性来支持bit band。
8. 内存访问权限及内存属性
8.1 访问权限
M3/M4内存映射之后,已经配置了默认的内存属性。这样就阻止用户(非特权模式)访问系统控制内存空间(System Control Memory)例如NVIC。注意,默认的访问权限,即便是MPU没有被使用,也是生效的。如果MPU进行了使能,更丰富的内存访问规则和权限将会被MPU定义。
默认状态的内存访问如图所示:
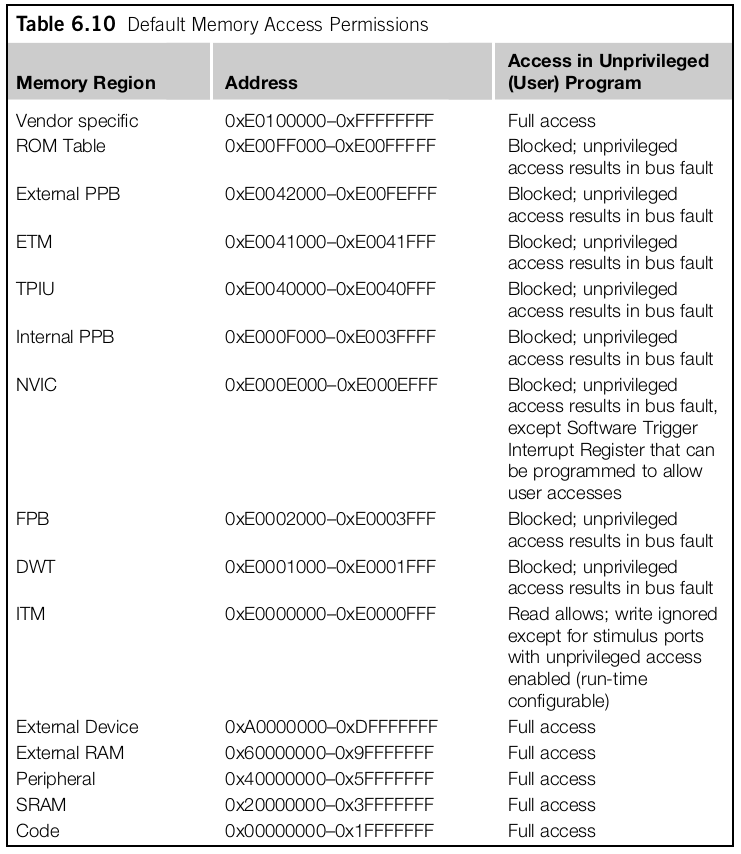
当一个非特权的访问被组织,一个默认的fault异常将会立刻发生。这个fault可能是HardFault或者BusFault异常取决于是否BusFault异常被使能或者优先级更高。
8.2 内存属性
从内存映射的图中可以看到内存区域。在memory map上除了能够寻址内存区域和访问设备,内存映射还定义了内存的访问属性。这些属性包含:
- Bufferable:当处理器继续执行下一个指令时,可以通过写缓冲区执行对内存的写入。
- Cacheable:从内存读取中获得的数据可以复制到CPU cache中,以便下次访问时可以从缓存中获得值,以加快程序执行。
- Executable:处理器可以从这个存储器区域获取并执行程序代码。
- Sharable:该存储器区域中的数据可以由多个总线主控器共享。存储器系统需要确保可共享存储器区域中不同总线主控器之间的数据的一致性。
处理器总线接口在指令访问数据的时候会对访问对象的属性信息进行检查。如果配置MPU和默认的属性不同的时候,以MPU配置为准。
一般的M3/M4的控制器,仅仅Executable和Bufferable属性影响着应用程序。Cacheable和Sharable属性仅仅被Cache Controller使用。

sharable的属性应该十分小心,通常sharable的内存区域会有多个观测者和访问者。当一个指令访问sharable内存的时候,cache控制器(如果有)首先会确保数据的一致性,是否被其他的访问者修改。
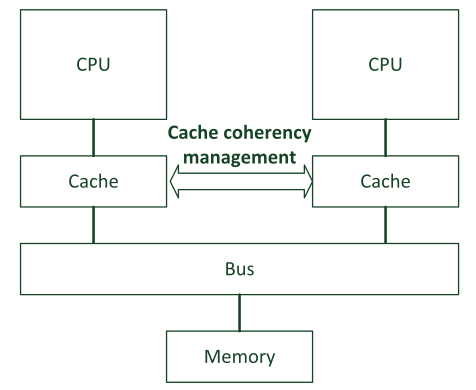
关于cache一致性,参考#57
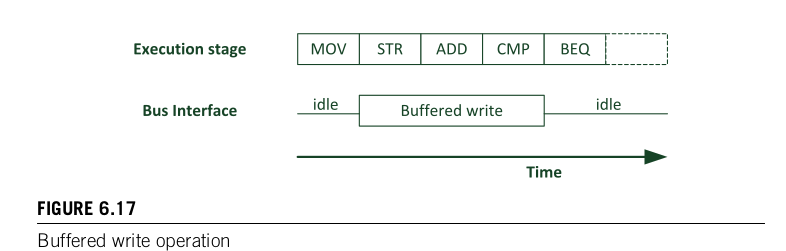
bufferable的属性主要是被处理器内部使用。为了提高更好的访问性能,M3/M4处理器在总线上支持单独的写buffer的入口。这意味着,当一个数据写入到一个bufferable的区域,只需单个clock cycle。
注意,MPU没有办法配置I-CODE和D-CODE的属性。
9. 独占访问(Exclusive Accesses)
在ARMv8中 内存独占加载和存储指令 ,这个概念在M核里面也有。传统的ARM处理器例如ARM7TDMI,有SWP指令,这个人指令的是用于信号量操作1,这个已经被独占访问操作代替。
信号量的操作通常都是给对于访问共有资源的应用程序。当一个共享的资源,只给两个使用者的时候,我们叫他互斥独占(MUTual EXclusion, MUTEX)。这样的情况下,其中一个角色锁住资源,另一个不能访问了,直到原有的资源持有者释放资源。为了实现MUTEX,在内存中必须定义一个标识符,来表示资源是否被持有。另一个资源想访问共享资源的时候,首先需要检测这个标志位,看看是处于空闲状态。在传统的ARM,访问内存中的标志位资源,就需要使用SWP指令。为什么需要特殊的指令处理,而不能直接写内存?因为写内存需要数个指令,资源肯可能在数个指令中被修改。因此需要一个原子性的操作,SWP指令就是原子性的操作,可以原子地对标志位进行修改。
在新的ARM处理器中,写和读操作有专门的总线。在这种情况下,SWP的实现是读写共有的总线才能对标志位进行原子的操作。因此,独占访问出现了。
在M核中,STREX/LDREX指令,都是独占访问指令。这个原理和内存独占加载和存储指令 一致。
需要注意的是,当独占访问被使用的时候,处理器内部写buffer可能会被绕过,即使MPU定义了这个区域是bufferable的。这个也是为了保证操作的原子性。SoC的设计者使用M3和M4的在多核的系统中,当发生独占访问传输的时候,应该确认内存系统不要使用数据并发。
10. 内存屏障 (Memory Barriers)
内存屏障已经不是什么新鲜的话题了,21_ARMv8_barrier(二)内存屏障案例 。 与ARMv8一样,ISB/DSB/DMB指令应用于内存屏障。在M3/M4中在大多数的应用中其实不需要关心内存屏障问题,这是因为:
- 在高性能的处理器中,例如A核的芯片,需要处理器的乱序执行。而在M核处理器没有使用乱序执行,都是顺序执行的。
- AHB Lite和APB协议,天生不允许在上一条还没执行完毕的时候下一条就开始执行。
即便是这样,还是有一些操作需要去注意内存屏障的使用。在一些情况下,比如写数据,需要好多的时钟周期, 而这时候有另外的人并行的执行访问操作。这时候,可能我们需要确保上一个写的操作一定要完成,才可以执行下一个操作。例如,一些处理器在系统控制器中有一些memory remapping的操作,remap完之后对这些remap的地址进行访问,在写入控制器需要remapping的时候,这时候DSB指令需要确保控制器确实被写入了,才能允许对remap的地址进行访问。也可以使用ISB指令在DSB指令之后,这样重新对所有的子序列取指,以确保remap的指令的地址是正确的。
11. 微控制器的内存系统
在很多控制器中,在设计中需要集成额外的内存系统:
- Bootloader
- Memory remapping
- Memory alias
这些特性本质上不是M处理器所讨论的访问,这些实现也都是二级厂商去实现,他们实现的都太一样,设计也十分灵活。在很多的设计中,除了存储程序的内存(flash),还有一些可能是可更改的Flash或者不可更改的ROM区域。这些独立的程序经常包含一个在你真正的程序之前的引导程序。为啥二级厂商喜欢这么设计:
- 提供一个flash编程工具的服务端,和上位机打配合,可能是串口或者USB烧写也未可知;
- 提供一个额外的固件例如通信协议栈,实现API使用Romote Call;
- 自检程序。
对于一个带着引导ROM的芯片,通常启动的时候都执行0地址的程序。然而,下次启动的时候,可能就不需要执行bootloader了,可以直接跳转到真正的应用程序。实现这种,最好的方式就是改变内存映射。在ARM中,会有一个地址解析器需要被编写。一个hardware寄存器会被使用到。

这个操作会切换内存的映射,叫做内存重映射remap。这个过程需要bootloader来完成。然而,你不能同时切换内存的映射时切换到新的bootloader程序。那怎么办? 这时候就需要memory address alias。
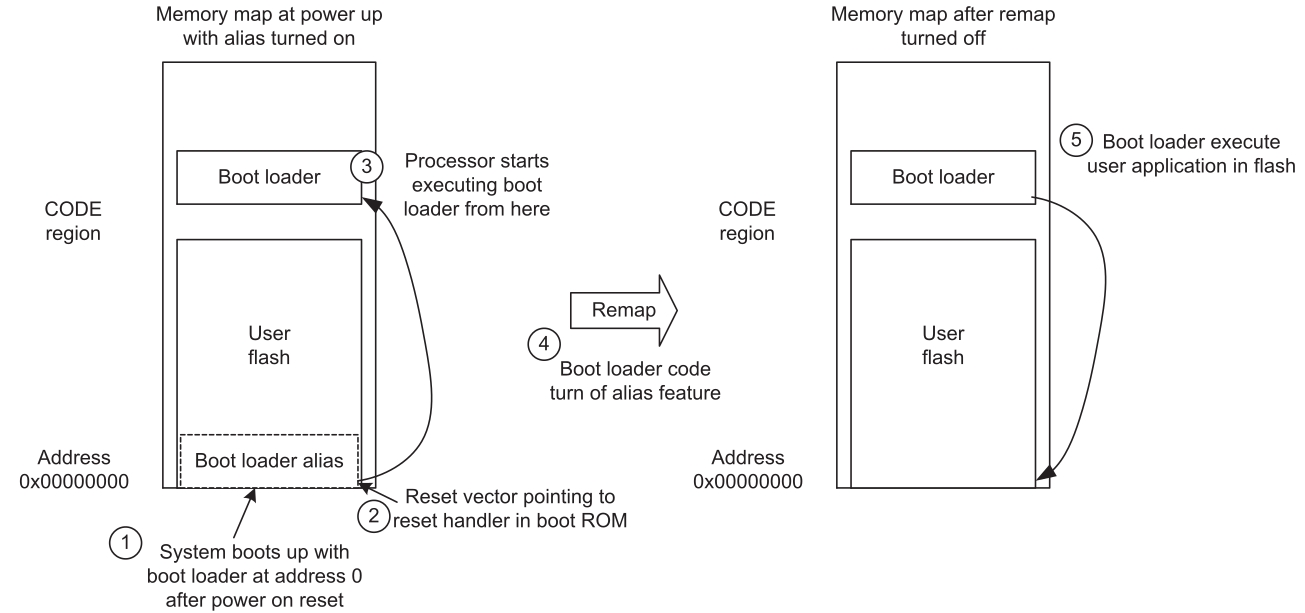
随着地址被重命名,bootloader的ROM可以从两个不同的内存区域被访问到。通常bootloader是从0地址可以访问到的。
这个还是要看二级厂商怎么设计,通常在boot章节会有讲。