PureTextTokenizer: inconsistent results when tokenizing same sentences
nnnyt opened this issue · comments

🐛 Description
(A clear and concise description of what the bug is.)
I try to tokenize an item twice using PureTextTokenzier, but get inconsistent results.
Error Message
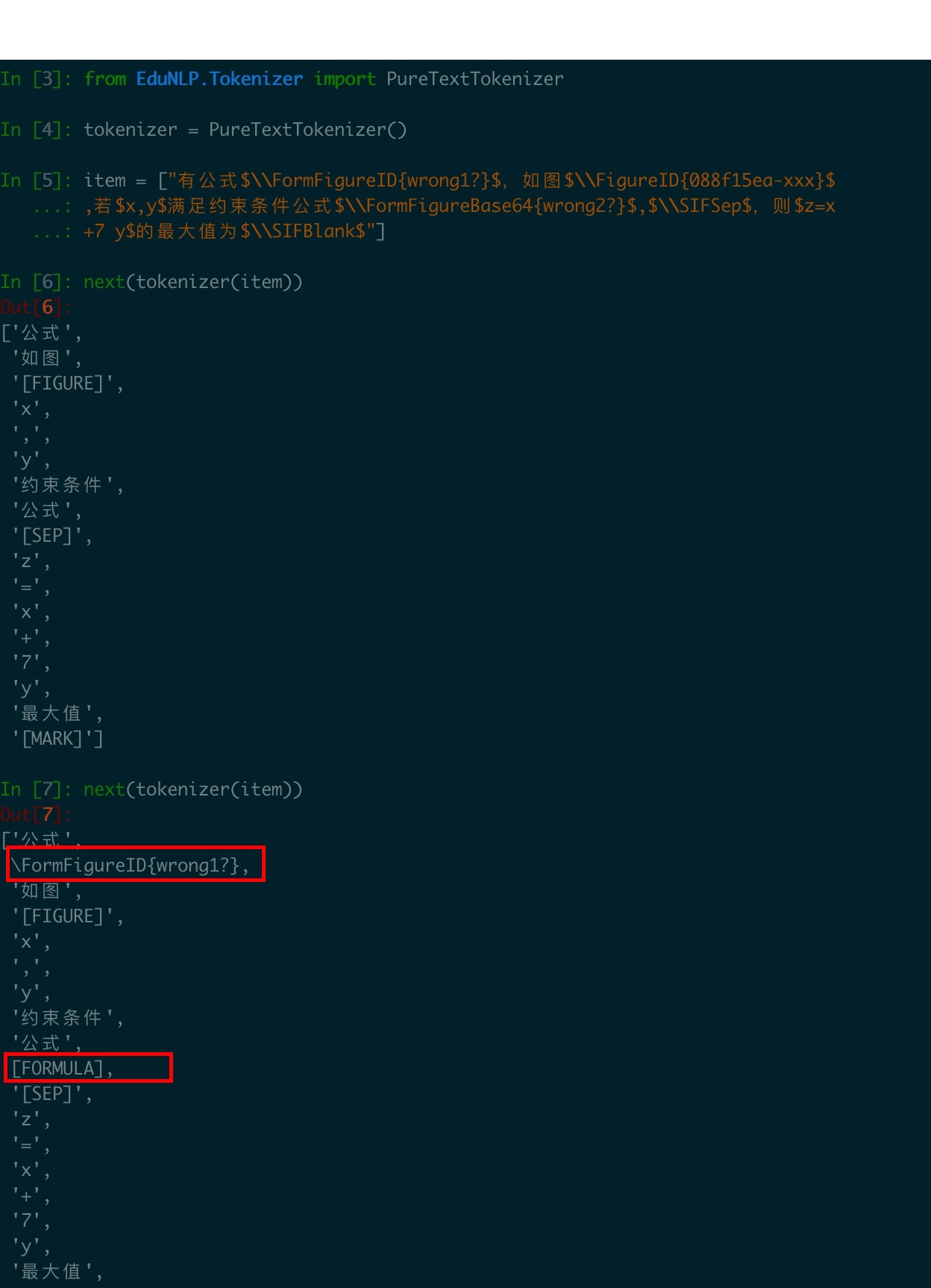
To Reproduce
The code I use:
from EduNLP.Tokenizer import PureTextTokenizer
tokenizer = PureTextTokenizer()
item = ["有公式$\\FormFigureID{wrong1?}$,如图$\\FigureID{088f15ea-xxx}$,若$x,y$满足约束条件公式$\\FormFigureBase64{wrong2?}$,$\\SIFSep$,则$z=x+7 y$的最大值为$\\SIFBlank$"]
next(tokenizer(item))
next(tokenizer(item))What have you tried to solve it?
Environment
Environment Information
Operating System: MacOS
Python Version: (e.g., python3.6, anaconda/python3.7, venv/python3.8) anaconda/python3.7
