- Surveys
- Unsorted
- Synthetic Data
- Domain Adaptation
- Domain Randomization
- Style Transfer
- Texture Synthesis
Notations
Read and worked
TODO
A Survey on Transfer Learning (2010)
Transfer learning for visual categorization: A survey (2015)
Domain Adaptation for Visual Applications: A Comprehensive Survey (2017)
Visual domain adaptation: A survey of recent advances (2015)
Deep Visual Domain Adaptation: A Survey (2018)
A survey on heterogeneous transfer learning (2017)
Transfer learning for cross-dataset recognition: A survey (2017)
[Visual Domain Adaptation Challenge (2018)] (http://ai.bu.edu/visda-2017/)
2018 - Do Better ImageNet Models Transfer Better?

2019 - Revisiting Self-Supervised Visual Representation Learning
2019 - A Large-scale Study of Representation Learning with the Visual Task Adaptation Benchmark

2013 - Simulation as an engine of physical scene understanding
2016 - Playing for Data: Ground Truth from Computer Games

2016 - RenderGAN: Generating Realistic Labeled Data

2017 - On Pre-Trained Image Features and Synthetic Images for Deep Learning)
In this paper, we show that a simple trick is sufficient to train very effectively modern object detectors with synthetic images only: We freeze the layers responsible for feature extraction to generic layers pre-trained on real images, and train only the remaining layers with plain OpenGL rendering. Our experiments with very recent deep architectures for object recognition (Faster-RCNN, R-FCN, Mask-RCNN) and image feature extractors (InceptionResnet and Resnet) show this simple approach performs surprisingly well.

2017 - Keep it Unreal: Bridging the Realism Gap for 2.5D Recognition with Geometry Priors Only
With the increasing availability of large databases of 3D CAD models, depth-based recognition methods can be trained on an uncountable number of synthetically rendered images. However, discrepancies with the real data acquired from various depth sensors still noticeably impede progress. Previous works adopted unsupervised approaches to generate more realistic depth data, but they all require real scans for training, even if unlabeled. This still represents a strong requirement, especially when considering real-life/industrial settings where real training images are hard or impossible to acquire, but texture-less 3D models are available. We thus propose a novel approach leveraging only CAD models to bridge the realism gap. Purely trained on synthetic data, playing against an extensive augmentation pipeline in an unsupervised manner, our generative adversarial network learns to effectively segment depth images and recover the clean synthetic-looking depth information even from partial occlusions. As our solution is not only fully decoupled from the real domains but also from the task-specific analytics, the pre-processed scans can be handed to any kind and number of recognition methods also trained on synthetic data.

While convolutional neural networks are dominating the field of computer vision, one usually does not have access to the large amount of domain-relevant data needed for their training. It thus became common to use available synthetic samples along domain adaptation schemes to prepare algorithms for the target domain. Tackling this problem from a different angle, we introduce a pipeline to map unseen target samples into the synthetic domain used to train task-specific methods. Denoising the data and retaining only the features these recognition algorithms are familiar with, our solution greatly improves their performance. As this mapping is easier to learn than the opposite one (ie to learn to generate realistic features to augment the source samples), we demonstrate how our whole solution can be trained purely on augmented synthetic data, and still perform better than methods trained with domain-relevant information (eg real images or realistic textures for the 3D models). Applying our approach to object recognition from texture-less CAD data, we present a custom generative network which fully utilizes the purely geometrical information to learn robust features and achieve a more refined mapping for unseen color images.

2019 - Implicit 3D Orientation Learning for 6D Object Detection from RGB Images
We propose a real-time RGB-based pipeline for object detection and 6D pose estimation. Our novel 3D orientation estimation is based on a variant of the Denoising Autoencoder that is trained on simulated views of a 3D model using Domain Randomization. This so-called Augmented Autoencoder has several advantages over existing methods: It does not require real, pose-annotated training data, generalizes to various test sensors and inherently handles object and view symmetries. Instead of learning an explicit mapping from input images to object poses, it provides an implicit representation of object orientations defined by samples in a latent space. Our pipeline achieves state-of-the-art performance on the T-LESS dataset both in the RGB and RGB-D domain. We also evaluate on the LineMOD dataset where we can compete with other synthetically trained approaches. We further increase performance by correcting 3D orientation estimates to account for perspective errors when the object deviates from the image center and show extended results.

2018 - Learning to Segment via Cut-and-Paste

2021 - Auto-Tuned Sim-to-Real Transfer [github]
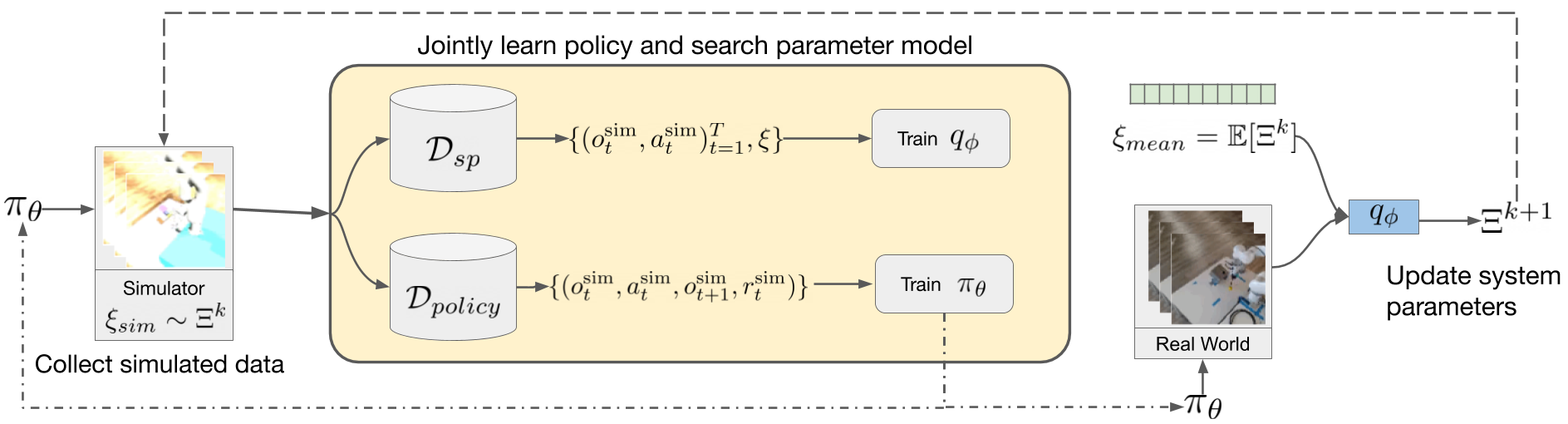
Policies trained in simulation often fail when transferred to the real world due to the `reality gap' where the simulator is unable to accurately capture the dynamics and visual properties of the real world. Current approaches to tackle this problem, such as domain randomization, require prior knowledge and engineering to determine how much to randomize system parameters in order to learn a policy that is robust to sim-to-real transfer while also not being too conservative. We propose a method for automatically tuning simulator system parameters to match the real world using only raw RGB images of the real world without the need to define rewards or estimate state. Our key insight is to reframe the auto-tuning of parameters as a search problem where we iteratively shift the simulation system parameters to approach the real-world system parameters. We propose a Search Param Model (SPM) that, given a sequence of observations and actions and a set of system parameters, predicts whether the given parameters are higher or lower than the true parameters used to generate the observations. We evaluate our method on multiple robotic control tasks in both sim-to-sim and sim-to-real transfer, demonstrating significant improvement over naive domain randomization.
*Description: fine-tuning the deephttps://media.arxiv-vanity.com/render-output/2249859/tsne_figure.png
-
Class Criterion: uses the class label information as a guide for transferring knowledge between different domains. When the labeled samples from the target domain are available in supervised DA, soft label and metric learning are always effective [118], [86], [53], [45], [79]. When such samples are unavailable, some other techniques can be adopted to substitute for class labeled data, such as pseudo labels [75], [139], [130],[98] and attribute representation [29], [118]. Usually a small number of labeled samples from the target dataset is assumed to be available.
-
Statistic Criterion: aligns the statistical distribution shift between the source and target domains using some mechanisms.
-
Architecture Criterion: aims at improving the ability of learning more transferable features by adjusting the architectures of deep networks.
-
Geometric Criterion: bridges the source and target domains according to their geometrical properties.
Using soft labels rather than hard labels can preserve the relationships between classes across domains.
Humans can identify unseen classes given only a high-level description. For instance, when provided the description ”tall brown animals with long necks”, we are able to recognize giraffes. To imitate the ability of humans, [64] introduced high-level semantic attributes per class.
Fine-grained recognition in the wild: A multi-task domain adaptation approach (2017) [soft labels, semantic attributes]
Deep transfer metric learning (2015)
Occasionally, when fine-tuning the network in unsupervised DA, a label of target data, which is called a pseudo label, can preliminarily be obtained based on the maximum posterior probability
In [98], two different networks assign pseudo-labels to unlabeled samples, another network is trained by the samples to obtain target discriminative representations.
Asymmetric tri-training for unsupervised domain adaptation (2017)
[DTN] Deep transfer network: Unsupervised domain adaptation (2015)
Although some discrepancy-based approaches search for pseudo labels, attribute labels or other substitutes to labeled target data, more work focuses on learning domain-invariant representations via minimizing the domain distribution discrepancy in unsupervised DA.
Maximum mean discrepancy (MMD) is an effective metric for comparing the distributions between two datasets by a kernel two-sample test [3].
[DDC] Deep domain confusion: Maximizing for domain invariance (2014)

Rather than using a single layer and linear MMD, Long et al. [73] proposed the deep adaptation network (DAN) that matches the shift in marginal distributions across domains by adding multiple adaptation layers and exploring multiple kernels, assuming that the conditional distributions remain unchanged.
[DAN] Learning transferable features with deep adaptation networks (2015)
[JAN] Deep transfer learning with joint adaptation networks (2016)
[RTN] Unsupervised domain adaptation with residual transfer networks (2016)

Associative Domain Adaptation (2017)
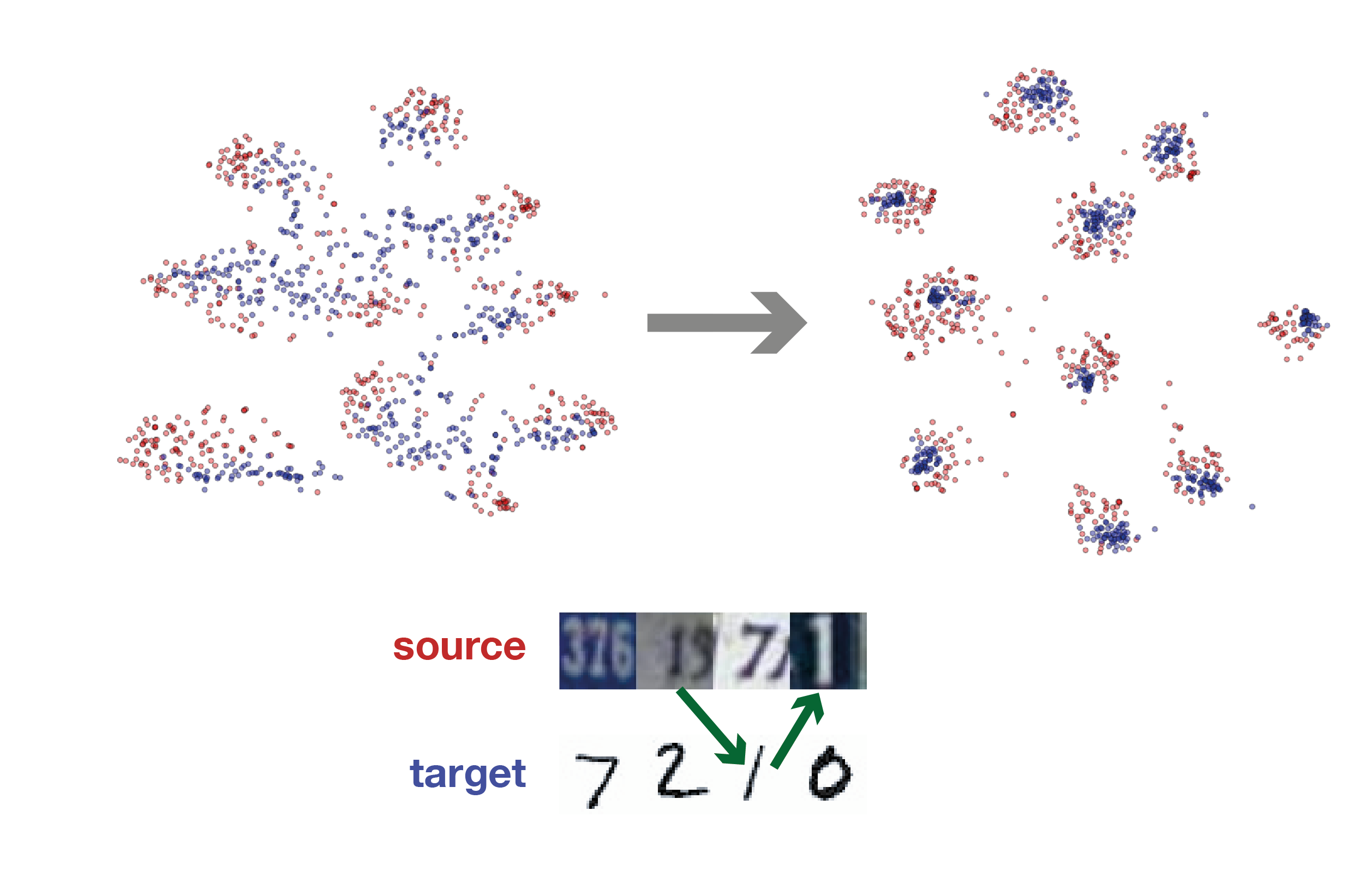
Return of frustratingly easy domain adaptation (2015)
Deeper, broader and artier domain generalization (2017)

[Dlid]: Deep learning for domain adaptation by interpolating between domains (2013) [geometric criterion]
Description: using domain discriminators to encourage domain confusion through an adversarial objective
2014 - Generative Adversarial Networks
2015 - [DANN] Domain-Adversarial Training of Neural Networks- [github]
2015 - [LapGAN] Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks
2016 - Improved techniques for training GANs github
2016 - Domain Separation Networks

2016 - [PixelDA] Unsupervised pixel-level domain adaptation with generative adversarial networks
Unfortunately, models trained purely on rendered images often fail to generalize to real images. To address this shortcoming, prior work introduced unsupervised domain adaptation algorithms that attempt to map representations between the two domains or learn to extract features that are domain-invariant. In this work, we present a new approach that learns, in an unsupervised manner, a transformation in the pixel space from one domain to the other. Our generative adversarial network (GAN)-based method adapts source-domain images to appear as if drawn from the target domain.
[Needs a lot of target images to successfully learn the generator]

2016 - [CoGAN] Coupled generative adversarial networks
2016 - Pixel-level domain transfer - [github]

Shrivastava et al. 104 developed a method for simulated+unsupervised (S+U) learning that uses a combined objective of minimizing an adversarial loss and a self-regularization loss, where the goal is to improve the realism of synthetic images using unlabeled real data
2016 - Learning from Simulated and Unsupervised Images through Adversarial Training

2017 - [MAD-GAN] Multi-Agent Diverse Generative Adversarial Networks
MAD-GAN is a multi-agent GAN architecture incorporating multiple generators and one discriminator. Second, to enforce that different generators capture diverse high probability modes, the discriminator of MADGAN is designed such that along with finding the real and fake samples, it is also required to identify the generator that generated the given fake sample.
2017 - [ADDA] Adversarial discriminative domain adaptation
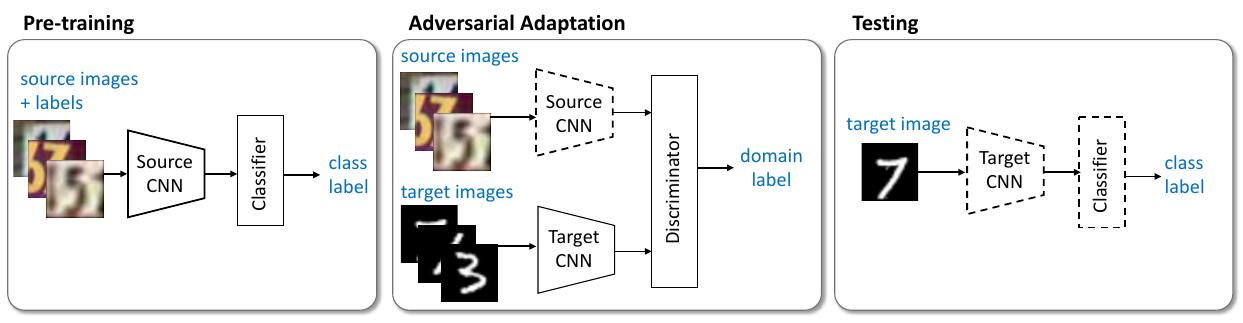
This weight-sharing constraint allows CoGAN to achieve a domain-invariant feature space without correspondence supervision. A trained CoGAN can adapt the input noise vector to paired images that are from the two distributions and share the labels. Therefore, the shared labels of synthetic target samples can be used to train the target model.
2017 - [PacGAN] PacGAN: The power of two samples in generative adversarial networks
We propose a principled approach to handling mode collapse, which we call packing. The main idea is to modify the discriminator to make decisions based on multiple samples from the same class, either real or artificially generated.
2017 - [PGAN]: Progressive Growing of GANs for Improved Quality, Stability, and Variation

The key idea is to grow both the generator and discriminator progressively: starting from a low resolution, we add new layers that model increasingly fine details as training progresses.
Typically, the generator is of main interest – the discriminator is an adaptive loss function that gets discarded once the generator has been trained. There are multiple potential problems with this formulation. When we measure the distance between the training distribution and the generated distribution, the gradients can point to more or less random directions if the distributions do not have substantial overlap, i.e., are too easy to tell apart
Large resolutions also necessitate using smaller minibatches due to memory constraints, further compromising training stability.
This incremental nature allows the training to first discover large-scale structure of the image distribution and then shift attention to increasingly finer scale detail, instead of having to learn all scales simultaneously.
When new layers are added to the networks, we fade them in smoothly, as illustrated in Figure 2. This avoids sudden shocks to the already well-trained, smaller-resolution layers.
The benefit of doing this dynamically instead of during initialization is somewhat subtle, and relates to the scale-invariance in commonly used adaptive stochastic gradient descent methods such as RMSProp and Adam. These methods normalize a gradient update by its estimated standard deviation, thus making the update independent of the scale of the parameter. As a result, if some parameters have a larger dynamic range than others, they will take longer to adjust. This is a scenario modern initializers cause, and thus it is possible that a learning rate is both too large and too small at the same time.
2017 - Improved Adversarial Systems for 3D Object Generation and Reconstruction
2018 - Toward Multimodal Image-to-Image Translation

2018 - From Source to Target and Back: Symmetric Bi-Directional Adaptive GAN
2018 - SRDA: Generating Instance Segmentation Annotation Via Scanning, Reasoning And Domain Adaptation [Geometry-guided GAN]

2018 - A Style-Based Generator Architecture for Generative Adversarial Networks

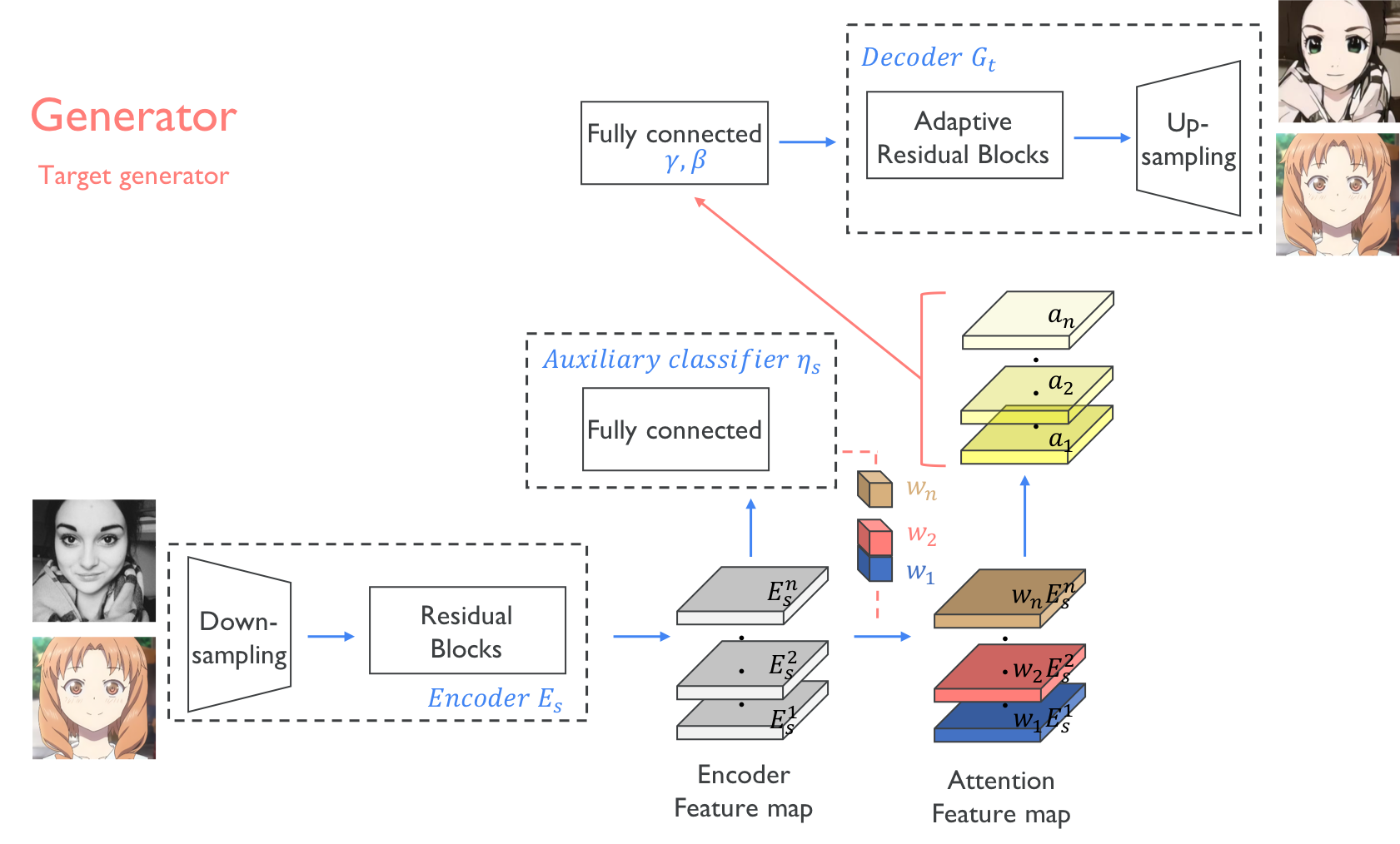
2020 - [BlockGAN]: Learning 3D Object-aware Scene Representations from Unlabelled Images

2021 - DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort
We introduce DatasetGAN: an automatic procedure to generate massive datasets of high-quality semantically segmented images requiring minimal human effort. Current deep networks are extremely data-hungry, benefiting from training on large-scale datasets, which are time consuming to annotate. Our method relies on the power of recent GANs to generate realistic images. We show how the GAN latent code can be decoded to produce a semantic segmentation of the image. Training the decoder only needs a few labeled examples to generalize to the rest of the latent space, resulting in an infinite annotated dataset generator! These generated datasets can then be used for training any computer vision architecture just as real datasets are. As only a few images need to be manually segmented, it becomes possible to annotate images in extreme detail and generate datasets with rich object and part segmentations. To showcase the power of our approach, we generated datasets for 7 image segmentation tasks which include pixel-level labels for 34 human face parts, and 32 car parts. Our approach outperforms all semi-supervised baselines significantly and is on par with fully supervised methods, which in some cases require as much as 100x more annotated data as our method.

2021 - DriveGAN: Towards a Controllable High-Quality Neural Simulation
Realistic simulators are critical for training and verifying robotics systems. While most of the contemporary simulators are hand-crafted, a scaleable way to build simulators is to use machine learning to learn how the environment behaves in response to an action, directly from data. In this work, we aim to learn to simulate a dynamic environment directly in pixel-space, by watching unannotated sequences of frames and their associated actions. We introduce a novel high-quality neural simulator referred to as DriveGAN that achieves controllability by disentangling different components without supervision. In addition to steering controls, it also includes controls for sampling features of a scene, such as the weather as well as the location of non-player objects. Since DriveGAN is a fully differentiable simulator, it further allows for re-simulation of a given video sequence, offering an agent to drive through a recorded scene again, possibly taking different actions. We train DriveGAN on multiple datasets, including 160 hours of real-world driving data. We showcase that our approach greatly surpasses the performance of previous data-driven simulators, and allows for new key features not explored before.

Description: using the data reconstruction as an auxiliary task to ensure feature invariance
GAN Zoo [link]

Self-ensembling for visual domain adaptation [link]
Context Encoders: Feature Learning by Inpainting (2016) [github]

Compositional GAN: Learning Conditional Image Composition (2018)

GAN Dissection: Visualizing and Understanding Generative Adversarial Networks [link] Interactive tool: https://gandissect.csail.mit.edu/
Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning [link]

Pros and Cons of GAN Evaluation Measures (2018)
Quotes and taxonomy of methods is from a great : Lil'Log blog post titled - Domain Randomization for Sim2Real Transfer
The environment that we have full access to (i.e. simulator) source domain and the environment that we would like to transfer the model to target domain (i.e. physical world). Training happens in the source domain. We can control a set of N randomization parameters in the source domain eξ with a configuration ξ, sampled from a randomization space. During training, episodes are collected from source domain with randomization applied. Thus the training is exposed to a variety of environments and learns to generalize. In a way, “discrepancies between the source and target domains are modeled as variability in the source domain.” (quote from Peng et al. 2018)
In the original form of DR (Tobin et al, 2017; Sadeghi et al. 2016), each randomization parameter is bounded by an interval, and each parameter is uniformly sampled within the range.
The randomization parameters can control appearances of the scene, objects geometry and propeties. A model trained on simulated and randomized images is able to transfer to real non-randomized images.
2017 - Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World

2017 - Training Deep Networks with Synthetic Data: Bridging the Reality Gap by Domain Randomization
2017 - Sim-to-Real Transfer of Robotic Control with Dynamics Randomization
In this paper, we demonstrate a simple method to bridge this "reality gap". By randomizing the dynamics of the simulator during training, we are able to develop policies that are capable of adapting to very different dynamics, including ones that differ significantly from the dynamics on which the policies were trained. This adaptivity enables the policies to generalize to the dynamics of the real world without any training on the physical system. Despite being trained exclusively in simulation, our policies are able to maintain a similar level of performance when deployed on a real robot, reliably moving an object to a desired location from random initial configurations. We explore the impact of various design decisions and show that the resulting policies are robust to significant calibration error.

In this work, we propose a reinforcement learning-based method for automatically adjusting the parameters of any (non-differentiable) simulator, thereby controlling the distribution of synthesized data in order to maximize the accuracy of a model trained on that data. In contrast to prior art that hand-crafts these simulation parameters or adjusts only parts of the available parameters, our approach fully controls the simulator with the actual underlying goal of maximizing accuracy, rather than mimicking the real data distribution or randomly generating a large volume of data. We find that our approach (i) quickly converges to the optimal simulation parameters in controlled experiments and (ii) can indeed discover good sets of parameters for an image rendering simulator in actual computer vision applications.

Some believe that sim2real gap is a combination of appearance gap and content gap; i.e. most GAN-inspired DA models focus on appearance gap. Meta-Sim (Kar, et al. 2019) aims to close the content gap by generating task-specific synthetic datasets.
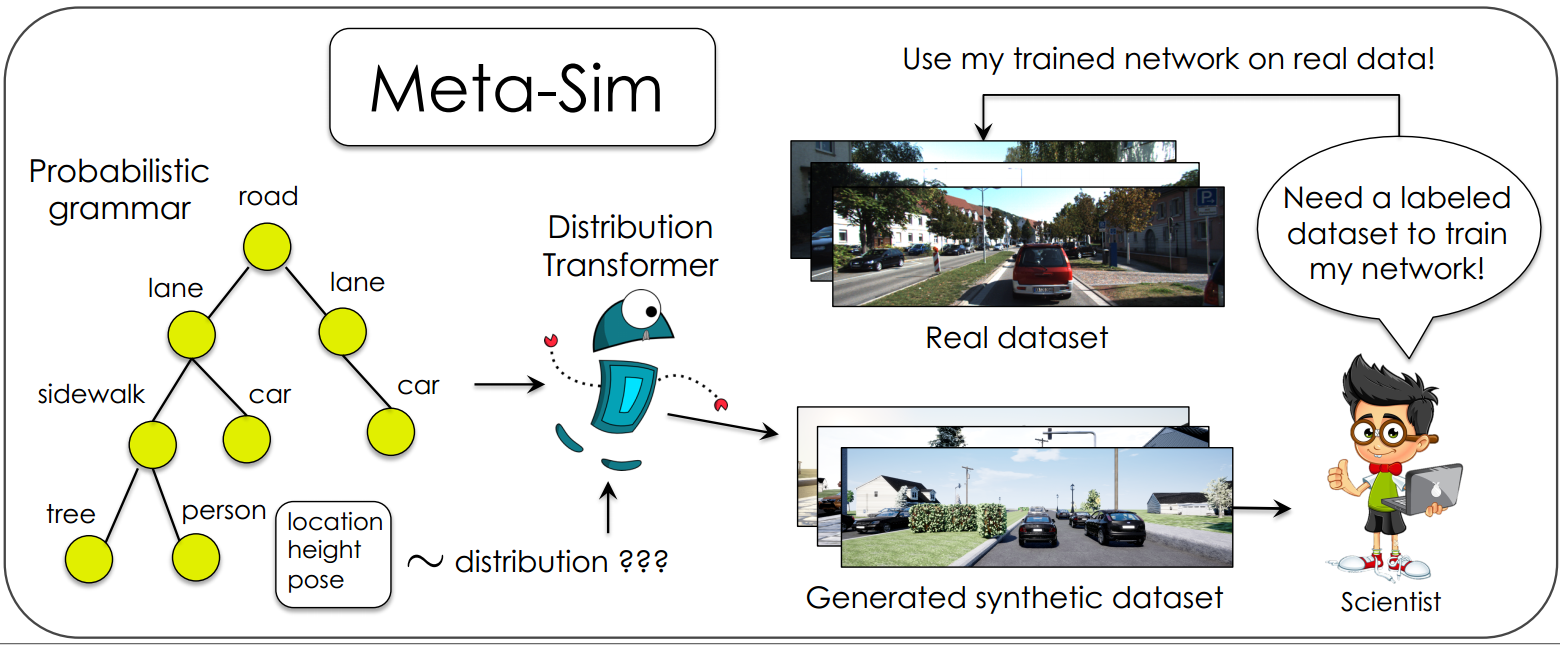
2019 - [Meta-Sim]: Learning to Generate Synthetic Datasets [website]
We propose Meta-Sim, which learns a generative model of synthetic scenes, and obtain images as well as its corresponding ground-truth via a graphics engine. We parametrize our dataset generator with a neural network, which learns to modify attributes of scene graphs obtained from probabilistic scene grammars, so as to minimize the distribution gap between its rendered outputs and target data. If the real dataset comes with a small labeled validation set, we additionally aim to optimize a meta-objective, i.e. downstream task performance. Experiments show that the proposed method can greatly improve content generation quality over a human-engineered probabilistic scene grammar, both qualitatively and quantitatively as measured by performance on a downstream task.
2019 - Closing the Sim-to-Real Loop: Adapting Simulation Randomization with Real World Experience
We consider the problem of transferring policies to the real world by training on a distribution of simulated scenarios. Rather than manually tuning the randomization of simulations, we adapt the simulation parameter distribution using a few real world roll-outs interleaved with policy training. In doing so, we are able to change the distribution of simulations to improve the policy transfer by matching the policy behavior in simulation and the real world. We show that policies trained with our method are able to reliably transfer to different robots in two real world tasks: swing-peg-in-hole and opening a cabinet drawer.

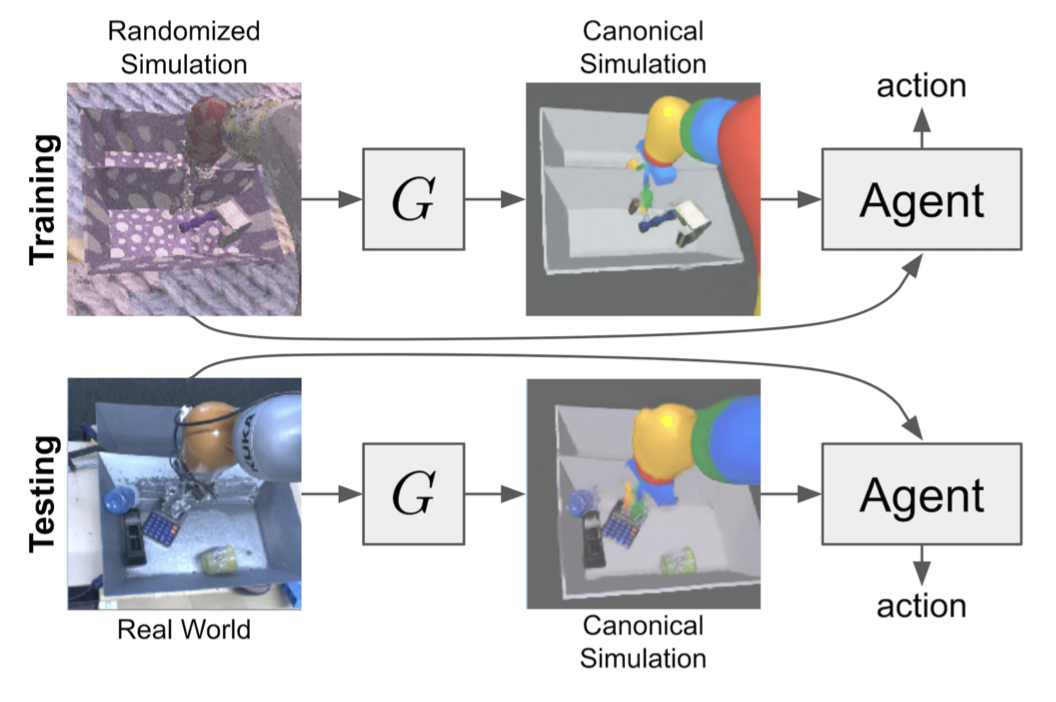
Using domain adaptation methods to cross this "reality gap" requires a large amount of unlabelled real-world data, whilst domain randomization alone can waste modeling power. In this paper, we present Randomized-to-Canonical Adaptation Networks (RCANs), a novel approach to crossing the visual reality gap that uses no real-world data. Our method learns to translate randomized rendered images into their equivalent non-randomized, canonical versions. This in turn allows for real images to also be translated into canonical sim images. Additionally, by joint finetuning in the real-world with only 5,000 real-world grasps, our method achieves 91%, attaining comparable performance to a state-of-the-art system trained with 580,000 real-world grasps, resulting in a reduction of real-world data by more than 99%.
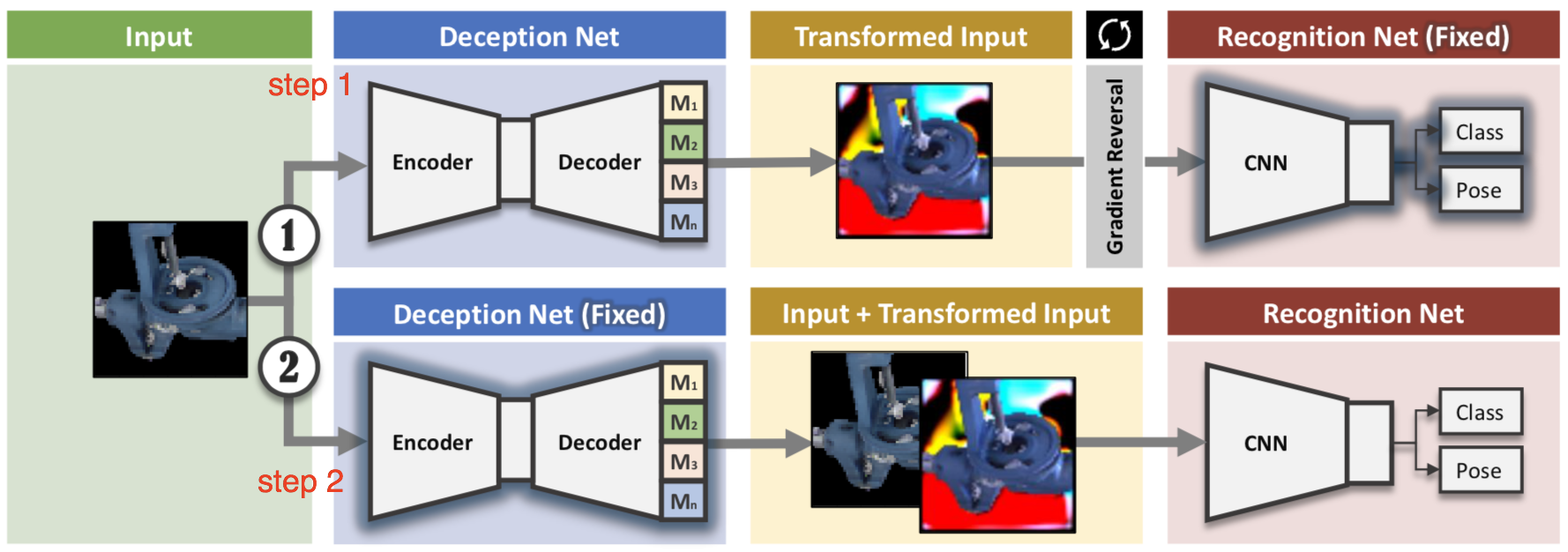
Network-driven domain randomization (Zakharov et al., 2019), also known as DeceptionNet, is motivated by learning which randomizations are actually useful to bridge the domain gap for image classification tasks.
Network-driven domain randomization (Zakharov et al., 2019), also known as DeceptionNet, is motivated by learning which randomizations are actually useful to bridge the domain gap for image classification tasks.
2019 - [DeceptionNet]: Network-Driven Domain Randomization
We present a novel approach to tackle domain adaptation between synthetic and real data. Instead, of employing "blind" domain randomization, i.e., augmenting synthetic renderings with random backgrounds or changing illumination and colorization, we leverage the task network as its own adversarial guide toward useful augmentations that maximize the uncertainty of the output. To this end, we design a min-max optimization scheme where a given task competes against a special deception network to minimize the task error subject to the specific constraints enforced by the deceiver. The deception network samples from a family of differentiable pixel-level perturbations and exploits the task architecture to find the most destructive augmentations. Unlike GAN-based approaches that require unlabeled data from the target domain, our method achieves robust mappings that scale well to multiple target distributions from source data alone.
Recent unsupervised approaches are mostly based on generalized adversarial networks (GANs) and although these methods perform proper target domain transfers, they can overfit to the chosen target domain and exhibit a decline in performance for unfamiliar out-of-distribution samples.
First, synthetic image formation produces clear edges with approximate physical shading and illumination, whereas real images undergo many types of noise, defects, etc. Second, the visual differences between synthetic CAD models and their actual physical counterparts can be quite significant.
In the first phase, the synthetic input is fed to our deception network responsible for producing augmented images that are then passed to a recognition network to compute the final task-specific loss with provided labels. Then, instead of minimizing the loss, we maximize it via gradient reversal and only back-propagate an update to the deception network parameters.
In this way, our method outputs images completely independent from the target domain and therefore generalizes much better to new unseen domains than related approaches.
Our approach can be placed between domain randomization and GAN methods, however, instead of forcing randomization without any clear guidance on its usefulness, we propose to delegate this to a neural network, which we call deception network, which tries to alter the images in an automated fashion, such that the task network is maximally confused
Despite of having a very high accuracy on the target data and the ability to generate additional samples that do not exist in the dataset, these methods present typical signs of overfit mappings that cannot generalize well to the extensions of the same data acquired in a similar manner. The simple reason for this might be the nature of these methods: they do not generalize to the features that matter the most for the recognition task, but to simply replicate the target distribution as close as possible.
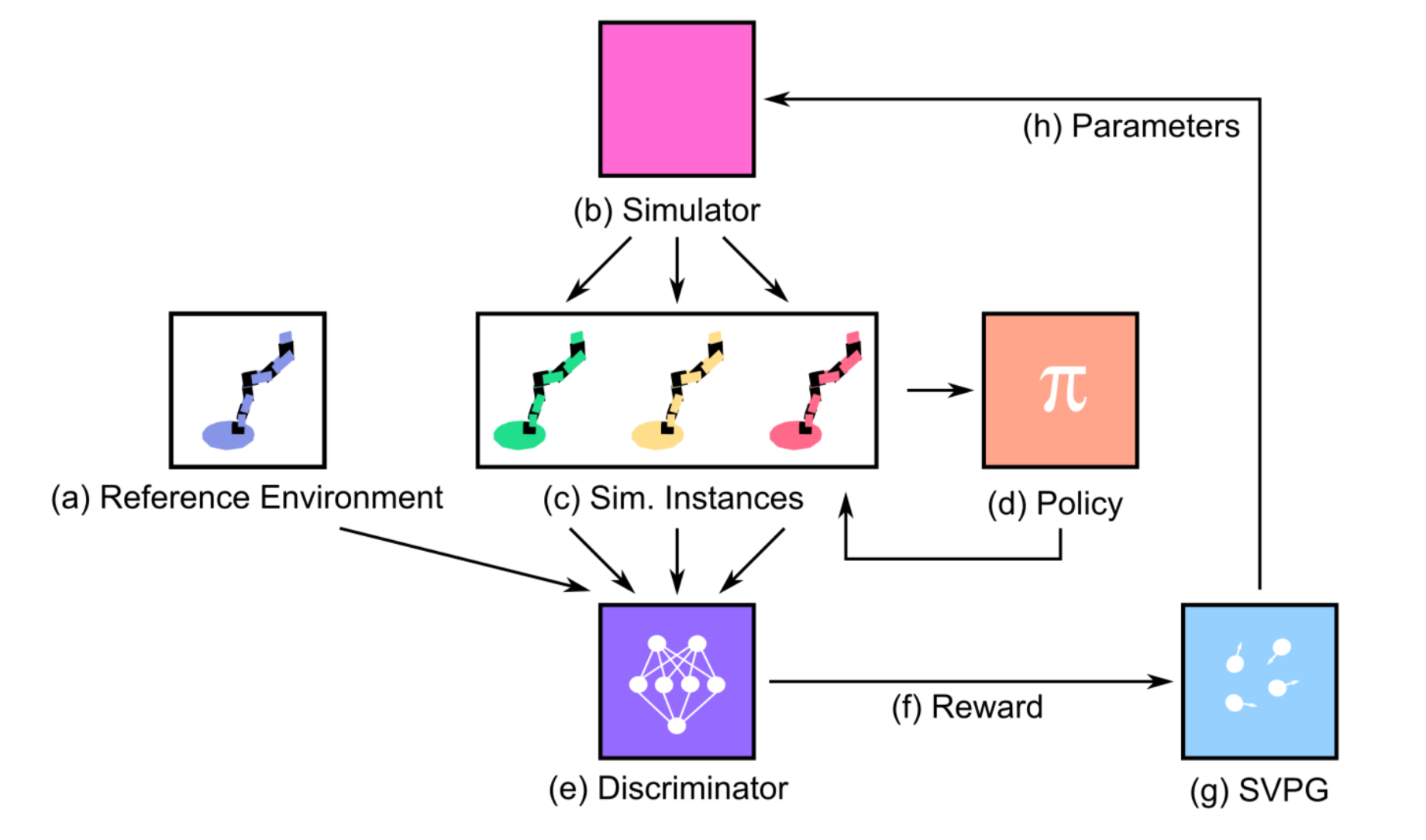
2019 - [ADR]: Active Domain Randomization
In this work, we empirically examine the effects of domain randomization on agent generalization. Our experiments show that domain randomization may lead to suboptimal, high-variance policies, which we attribute to the uniform sampling of environment parameters. We propose Active Domain Randomization, a novel algorithm that learns a parameter sampling strategy. Our method looks for the most informative environment variations within the given randomization ranges by leveraging the discrepancies of policy rollouts in randomized and reference environment instances. We find that training more frequently on these instances leads to better overall agent generalization. Our experiments across various physics-based simulated and real-robot tasks show that this enhancement leads to more robust, consistent policies.
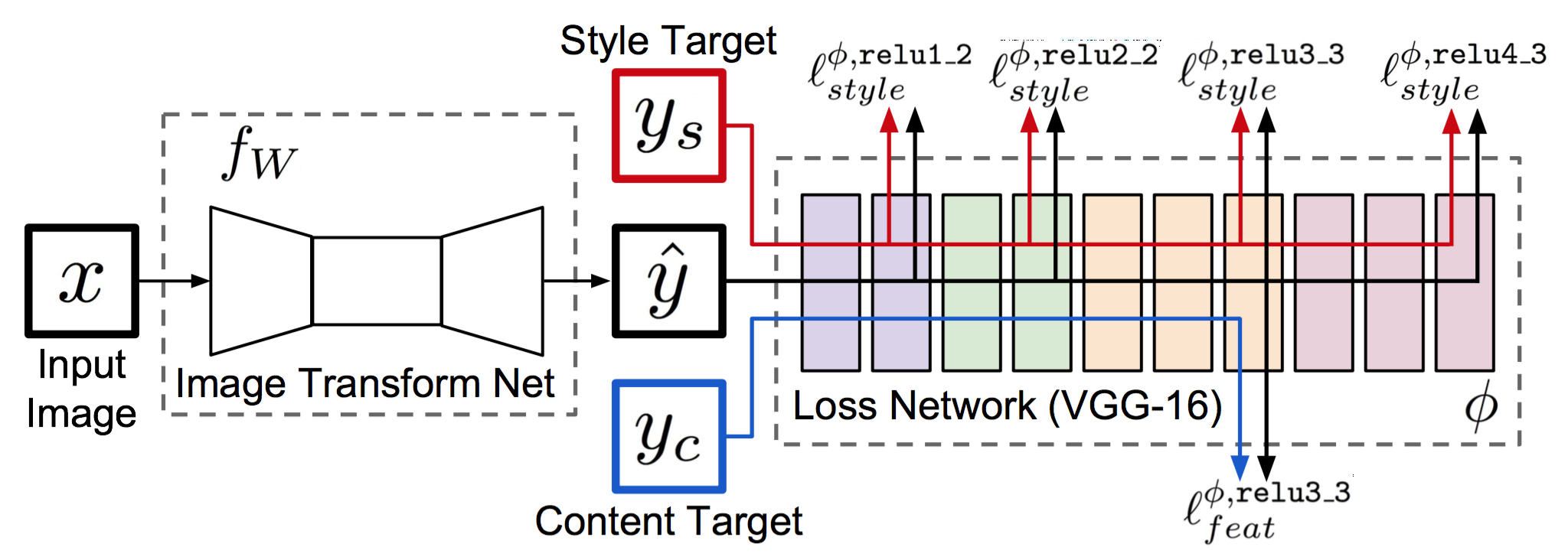
2016 - Image Style Transfer Using Convolutional Neural Networks
2016 Perceptual losses for real-time style transfer and super-resolution [github]
2017 - [CycleGAN] Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks

2016 - [pix2pix] Image-to-Image Translation with Conditional Adversarial Networks[github]
2018 - [DRIT] Diverse Image-to-Image Translation via Disentangled Representations[github]

2018 - A Style-Based Generator Architecture for Generative Adversarial Networks[github]

2018 - Deep Painterly Harmonization [github]

2021 - StyleLess layer: Improving robustness for real-world driving
Deep Neural Networks (DNNs) are a critical component for self-driving vehicles. They achieve impressive performance by reaping information from high amounts of labeled data. Yet, the full complexity of the real world cannot be encapsulated in the training data, no matter how big the dataset, and DNNs can hardly generalize to unseen conditions. Robustness to various image corruptions, caused by changing weather conditions or sensor degradation and aging, is crucial for safety when such vehicles are deployed in the real world. We address this problem through a novel type of layer, dubbed StyleLess, which enables DNNs to learn robust and informative features that can cope with varying external conditions. We propose multiple variations of this layer that can be integrated in most of the architectures and trained jointly with the main task. We validate our contribution on typical autonomousdriving tasks (detection, semantic segmentation), showing that in most cases, this approach improves predictive performance on unseen conditions (fog, rain), while preserving performance on seen conditions and objects.

2015 - Texture Synthesis Using Convolutional Neural Networks [github]

DeepTextures http://bethgelab.org/deeptextures/
Textures database https://www.textures.com/index.php