Combining arrayfire-python with cython
florian98765 opened this issue · comments

hello, we are currently working on a finite difference code using arrayfire. First benchmarks showed that for small systems the C/C++ versions seems to be significantly faster than the Python version. Therefor at least the core routines should be implemented in C/C++. On the other hand the final interface should be available in Python. We typically use Cython for that purpose and we already archive to pass arrays from C to Python and call some low-level routines using cython wrappers.
Unfortunately we are not yet able to combine the cython interface with the ctypes wrappers. Finally we would like to be able to create an array from arrayfire-python. Somehow determine the address of the C/C++ array and pass this to our cython wrappers. We tried several methods to determine the address of the underlying array, and we are quite sure that one of these versions should give the correct address, but we still get the following error:
terminate called after throwing an instance of 'af::exception'
what(): ArrayFire Exception (Unknown error:208):
In function const ArrayInfo& getInfo(af_array, bool, bool)
In file src/api/c/array.cpp:30
Input Array not created on current device
In function void af::print(const char*, const af::array&)
In file src/api/cpp/util.cpp:21
Aborted
It looks like that there are two "instances" of arrayfire which do not work together!? Does anybody have experience with arrayfire and cython? any ideas how to debug such a problem?
thanks for any suggestion
Florian

@florian98765 Can you make sure the backend being used in Python and cython are the same ?
Besides, the python wrapper shouldnt be significantly slower (unless you are performing a lot of indexing operations). Would it be possible to share some reproducible code ?
@florian98765 anything you can share?

As Florian is currently out of office, I can share our example:
setup.py
from distutils.core import setup
from distutils.extension import Extension
from Cython.Distutils import build_ext
setup(
name = 'Demos',
ext_modules=[
Extension("test",
libraries = ["afcuda"],
sources=["test.pyx", "cpp_test.cpp"],
language="c++"),
],
cmdclass = {'build_ext': build_ext},
)
test.pyx
import ctypes
import arrayfire
from libc.stdint cimport uintptr_t
cdef extern from "<arrayfire.h>":
ctypedef void* af_array
cdef extern from "<arrayfire.h>" namespace "af":
cdef cppclass array:
array()
cdef extern from "cpp_test.h":
cdef cppclass Test:
void usearray(long int a)
Test()
cdef class pyTest:
cdef Test* thisptr # hold a C++ instance
def __cinit__(self):
self.thisptr = new Test()
def __dealloc__(self):
del self.thisptr
def usearray(self, a):
adr = ctypes.addressof(a.arr)
print hex(adr), "hex(adr) in usearray";
arrayfire.info()
self.thisptr.usearray(adr)
cpp_test.h
#ifndef TEST_H
#define TEST_H
#include<arrayfire.h>
class Test {
public:
Test();
~Test();
void usearray(long int a);
};
#endif
cpp_test.cpp
#include "cpp_test.h"
#include <stdio.h>
Test::Test() { }
Test::~Test() { }
void Test::usearray(long int aptr) {
printf("%p a CPP array address \n", (void*)aptr);
af::info();
af_array a = (void *)aptr;
af::array b(a);
b.lock();
printf("%p b.get() CPP array address \n", b.get());
af::print("ARRAY:", b);
}
Thank you for your efforts.
And for completeness:
run.py
import test
import ctypes
import arrayfire
arrayfire.info()
x=test.pyTest()
a = arrayfire.constant(2.,1)
arrayfire.lock_array(a)
print hex(ctypes.addressof(a.arr)),"hex(ctypes.addressof(a.arr))"
x.usearray(a)
@pthon call b.lock() after creating it. You need to do that for any array you share from python to C++.
If you don't do that both python and C++ will try to free the array.
@pthon I am unable to build this. I am getting a error saying there are multiple definitions of the Test costructor.
BTW can you also include the output you are seeing?
Some files were named improperly, I corrected it in the comments above, sorry about that.
I also included the lines
cpp_test.cpp
b.lock();
run.py
arrayfire.lock_array(a)
The output I am still seeing is
ArrayFire v3.5.0 (CUDA, 64-bit Linux, build 3e81874)
Platform: CUDA Toolkit 8, Driver: 375.26
[0] Tesla K20m, 4743 MB, CUDA Compute 3.5
-1- Tesla K20m, 4743 MB, CUDA Compute 3.5
-2- Tesla K20m, 4743 MB, CUDA Compute 3.5
-3- Tesla K20m, 4743 MB, CUDA Compute 3.5
0x7f252a162880 hex(ctypes.addressof(a.arr))
0x7f252a162880 hex(adr) in usearray
ArrayFire v3.5.0 (CUDA, 64-bit Linux, build 3e81874)
Platform: CUDA Toolkit 8, Driver: 375.26
[0] Tesla K20m, 4743 MB, CUDA Compute 3.5
-1- Tesla K20m, 4743 MB, CUDA Compute 3.5
-2- Tesla K20m, 4743 MB, CUDA Compute 3.5
-3- Tesla K20m, 4743 MB, CUDA Compute 3.5
0x7f252a162880 a CPP array address
ArrayFire v3.5.0 (CUDA, 64-bit Linux, build 3e81874)
Platform: CUDA Toolkit 8, Driver: 375.26
[0] Tesla K20m, 4743 MB, CUDA Compute 3.5
-1- Tesla K20m, 4743 MB, CUDA Compute 3.5
-2- Tesla K20m, 4743 MB, CUDA Compute 3.5
-3- Tesla K20m, 4743 MB, CUDA Compute 3.5
terminate called after throwing an instance of 'af::exception'
what(): ArrayFire Exception (Unknown error:208):
In function const ArrayInfo& getInfo(af_array, bool, bool)
In file src/api/c/array.cpp:30
Input Array not created on current deviceIn function void af::array::lock() const
In file src/api/cpp/array.cpp:1062
Aborted
@pthon @florian98765 I am able to reproduce thhe error, but I am not really sure why this is happening. Unfortunately I will not be able to test this for a couple of days..
@pthon @florian98765 I figured out what was the issue. You were sending the address of the ctypes object to C++ which is void **.
In Python the af_array is technically a.arr.value not a.arr.
To get your code work, you can simply change
af_array a = (void *)aptr;
to
af_array a = *(void **)aptr;
Other things to not: For some reason the C++ code is getting destroyed after the python code. This is causing issues at exit. So I suggest removing lock array from both locations and use the C++ array this way:
af::array *A = new af::array(a);
Just do not delete A. The memory pointed by A will be deleted by python.
For reference here is my run.py:
import ctypes
import arrayfire
import test
arrayfire.info()
x=test.pyTest()
a = arrayfire.randu(5)
print(hex(a.arr.value))
x.usearray(a)cpp_test.cpp
#include "cpp_test.h"
#include <stdio.h>
Test::Test() { }
Test::~Test() {}
void Test::usearray(long int aptr) {
void **a = (void **)aptr;
af::array *A = new af::array(*a);
af_print(*A);
}The cython file doesnt need any changing.
Btw can you also share some code that is slow in python but fast in C++ ? It may help fix any performance issues in the wrapper.
Many thanks for your help, it helped a lot!
As of performance differences between C++ and Python, we excessively need three operations:
- Indexing operations such as our current cross product implementation which I mentioned in #1113
- Convolutions with small kernels (3x3x3) (could be improved when #1320 is implemented)
- FFTs
As you mentioned above, indexing operations are expected to perform worse in Python and should be avoided generally, but I did not find a workaround for my cross product implementation.
For the convolution and FFTs, C++ seems to be a lot faster for small ararys. At a first glance, we timed 100 operations for increasing array sizes and encountered a significant difference up to an array size of about 30x30x30 (see code below).
One thing which seems odd is that the convolution with a very small kernel (3x3x3) does not seem to perform better as the FFT, do you have any suggestions?
Again, thanks for your help!
Convolution:
#include "arrayfire.h"
#include <iostream>
#include <fstream>
using namespace af;
int main(int argc, char** argv)
{
array in=constant(0.0,f64);
timer t;
int solveloops = 100;
array filtr=constant(0.0,3,3,3,f64);
filtr(0,1,1)= 1;
filtr(2,1,1)= 1;
filtr(1,0,1)= 1;
filtr(1,2,1)= 1;
filtr(1,1,0)= 1;
filtr(1,1,2)= 1;
std::ofstream myfile;
myfile.open ("../../Data/conv_cpp_time_nns.txt");
myfile << "#cpp: l \t mean \t single \n";
for(int l = 2; l <= 100; l=l+2){
printf("Loop l=%d\n",l);
in=randu(l,l,l,3,f64);
t = timer::start();
array exch = convolve(in,filtr,AF_CONV_DEFAULT,AF_CONV_SPATIAL);
sync();
double time_single=timer::stop(t);
printf("single conv [s]: %f\n",time_single);
t = timer::start();
for (int sl = 0; sl < solveloops; sl++){
array exch = convolve(in,filtr,AF_CONV_DEFAULT,AF_CONV_SPATIAL);
in=randu(l,l,l,3,f64);
}
sync();
double time_solve=timer::stop(t);
printf("mean %d solve_opt [s]: %f\n\n",solveloops,time_solve/solveloops);
myfile << l << "\t"<< time_solve/solveloops << "\t" << time_single << "\n";
}
myfile.close();
return 0;
}
vs
import arrayfire as af
f=open('../../Data/conv_py_time_nns.txt','w')
inp=af.constant(0.0,1,1,1,1,dtype=af.Dtype.f64)
filtr=af.constant(0.0,3,3,3,dtype=af.Dtype.f64)
filtr[0,1,1] = 1
filtr[2,1,1] = 1
filtr[1,0,1] = 1
filtr[1,2,1] = 1
filtr[1,1,0] = 1
filtr[1,1,2] = 1
f.write("#py:l \t mean \t single \n")
for l in range (2,100,2):
print l
inp=af.randu(l,l,l,3,dtype=af.Dtype.f64)
t=af.timer.time()
conv=af.convolve(inp,filtr, conv_mode=af.CONV_MODE.DEFAULT, conv_domain=af.CONV_DOMAIN.SPATIAL)
af.sync()
time_single=af.timer.time() - t
print "single conv [s] :", time_single
loops=100
t2=af.timer.time()
for i in range(loops):
conv=af.convolve(inp,filtr, conv_mode=af.CONV_MODE.DEFAULT, conv_domain=af.CONV_DOMAIN.SPATIAL)
inp=af.randu(l,l,l,3,dtype=af.Dtype.f64)
af.sync()
time_loops=af.timer.time() -t2
print loops, "loops mean [s]:",(time_loops/loops)
f.write(str(l)+"\t"+str(time_loops/loops)+"\t"+str(time_single)+"\n")
f.close()
FFT:
#include "arrayfire.h"
#include <iostream>
#include <fstream>
int main(int argc, char** argv)
{
af::array in=af::constant(0.0,f64);
af::array fft=af::constant(0.0,f64);
af::timer t;
double time_single;
double time_solve;
int solveloops = 100;
std::ofstream myfile;
myfile.open ("../../Data/fft_cpp_time_nns.txt");
myfile << "#cpp: l \t mean \t single \n";
for(int l = 2; l <= 100; l=l+2){
printf("Loop l=%d\n",l);
in=af::randu(l,l,l,3,f64);
t = af::timer::start();
fft=af::fftR2C<3>(in);
af::sync();
time_single=af::timer::stop(t);
printf("single fftR2C<3> [s]: %f\n",time_single);
t = af::timer::start();
for (int sl = 0; sl < solveloops; sl++){
fft = af::fftR2C<3>(in);
in=af::randu(l,l,l,3,f64);
}
af::sync();
time_solve=af::timer::stop(t);
printf("mean %d solve_opt [s]: %f\n\n",solveloops,time_solve/solveloops);
myfile << l << "\t"<< time_solve/solveloops << "\t" << time_single << "\n";
}
myfile.close();
return 0;
}
vs
import arrayfire as af
f=open('../../Data/fft_py_time_nns.txt','w')
inp=af.constant(0.0,1,1,1,1,dtype=af.Dtype.f64)
fft=af.constant(0.0,1,1,1,1,dtype=af.Dtype.f64)
f.write("#py:l \t mean \t single \n")
for l in range (2,100,2):
print l
inp=af.randu(l,l,l,3,dtype=af.Dtype.f64)
t=af.timer.time()
fft=af.fft3_r2c(inp)
af.sync()
te=af.timer.time()
time_solve_single=te-t
print "single:", time_solve_single
loops=100
time_s=af.timer.time()
for i in range(loops):
fft=af.fft3_r2c(inp)
inp=af.randu(l,l,l,3,dtype=af.Dtype.f64)
af.sync()
time_e=af.timer.time()
time_solve_loop=time_e-time_s
print loops,"af.time solves [s]:",(time_e-time_s)/loops
print loops,"solves total time [s]:",(time_e-time_s)
f.write(str(l)+"\t"+str(time_solve_loop/loops)+"\t"+str(time_solve_single)+"\n")
f.close()
@pthon Thanks for the reproducible scripts! I put in the benchmarks from my desktop over here:
https://gist.github.com/pavanky/836b8ea30fe2cd60736572613edd4bb5
At smaller sizes the bottleneck seems to be the ffi. I'll need to investigate cffi vs ctypes to see if this can be improved.
One thing which seems odd is that the convolution with a very small kernel (3x3x3) does not seem to perform better as the FFT, do you have any suggestions?
This is not what I am seeing in the benchmarks. Can you show me what numbers you are seeing?
That would be great!
I formulated my comment comparing the convolution and the FFT deceptively. The convolution with its (3x3x3) kernel is actually faster than the FFT, but I expected it to be way faster as it is (especially for the huge arrays).
For visualization I add a graphic showing the quotient of the conv and fft timings for C++ (the raw data I added to your file-link )
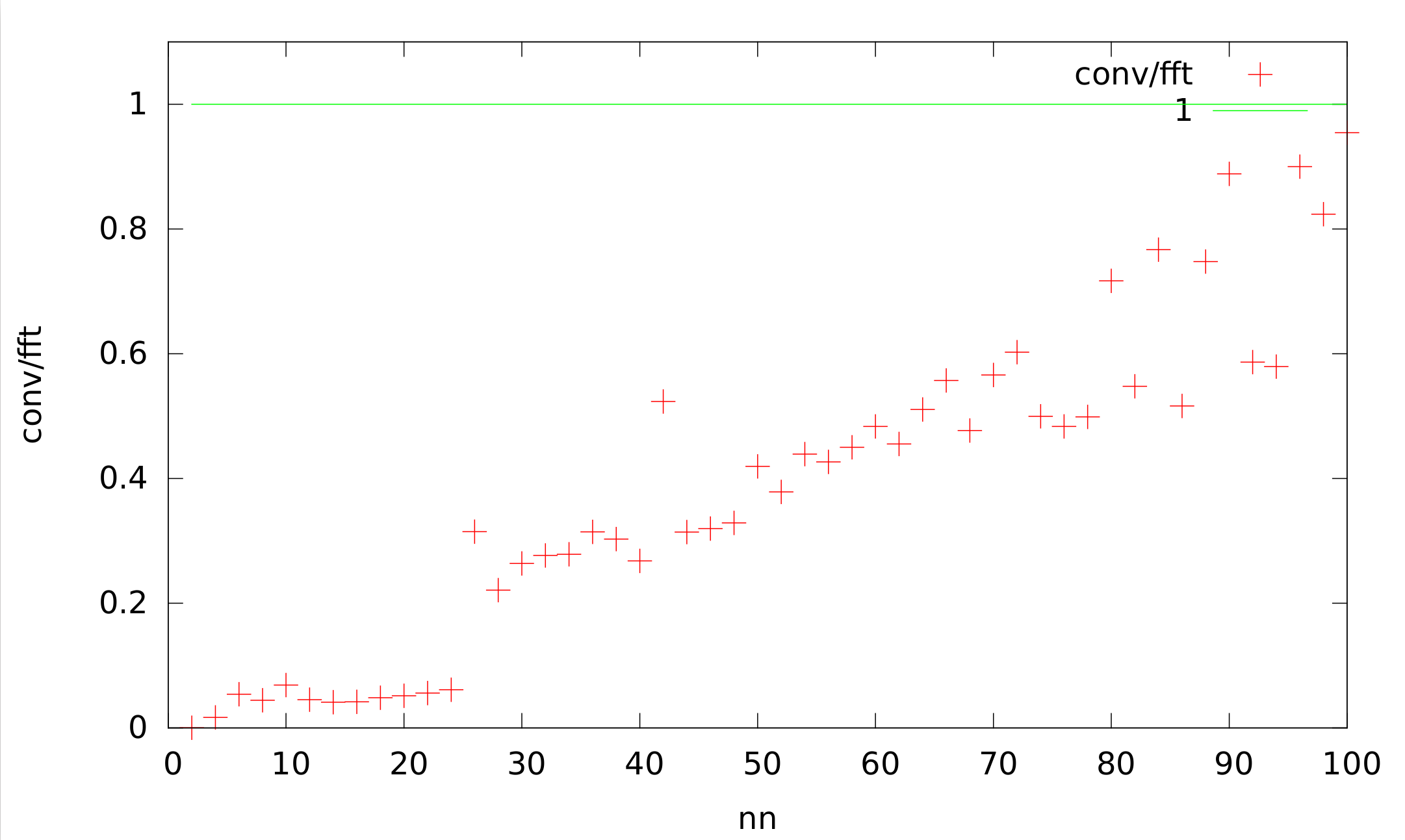
Would you expect such a behaviour?
@pthon for larger sizes convolution falls back to using fft + ifft for performing convolutions. But it uses closest powers of 2 so it is going to be a bit faster than a single fft.
I understand that the fall back to fft+ifft, scaling with N log(N), is usefull if both signal and kernel are huge. But for a very small kernel, this fall back seems inefficient as the convolution would still scale with N.
Is there a way to avoid the fft+ifft fall back?
@pthon can you open the issue upstream so I can look into it.
Is there a way to again create a python af.Array from a pointer passed by the cpp code (i.e. the reverse action of what is achieved in the discussion above)?
EDIT: I updated the example with your suggestions and the array is passed from python to cpp and back to python. However, I am getting an error "Error in `python': double free or corruption (!prev): 0x0000000001cd9350" at exit both for v3.5.0 and v3.5.1 at all backends.
run.py
import ctypes
import wrap
import arrayfire as af
wrapper=wrap.pyWrap()
A=af.constant(1.0,2,3,2,3, af.Dtype.f64)
wrapper.py_to_cpp(A)
wrapper.calc_B()
B_addr = wrapper.cpp_to_py()
B = af.Array()
B.arr = ctypes.c_void_p(B_addr)
print "py: B = ", B
interface.pyx
import ctypes
import arrayfire
cdef extern from "source.hpp":
cdef cppclass Wrap:
void c_py_to_cpp(long int a_addr)
void c_calc_B()
long int c_cpp_to_py()
cdef class pyWrap:
cdef Wrap* thisptr
def __cinit__(self):
self.thisptr = new Wrap()
def __dealloc__(self):
del self.thisptr
def py_to_cpp(self, a):
self.thisptr.c_py_to_cpp(ctypes.addressof(a.arr))
def cpp_to_py(self):
return self.thisptr.c_cpp_to_py()
def calc_B(self):
self.thisptr.c_calc_B()
source.cpp
#include "source.hpp"
#include "source.hpp"
Wrap:: Wrap() {}
Wrap::~Wrap() {}
void Wrap::c_py_to_cpp(long int addr){
A = *( new af::array( *(void**) addr ));
}
void Wrap::c_calc_B(){
af::print("cpp: A= ", A);
B=2*A;
af::print("cpp: B= ", B);
}
long int Wrap::c_cpp_to_py(){
B.lock();
return (long int) B.get();
}
source.hpp
#ifndef SOURCE_H
#define SOURCE_H
#include<arrayfire.h>
class Wrap {
public:
Wrap();
~Wrap();
void c_py_to_cpp(long int a_addr);
long int c_cpp_to_py();
void c_calc_B();
af::array A;
af::array B;
};
#endif
setup.py
from distutils.core import setup
from distutils.extension import Extension
from Cython.Distutils import build_ext
setup(
name = 'Wrap',
ext_modules=[
Extension("wrap",
libraries = ["afcuda"],
#libraries = ["afopencl"],
#libraries = ["afcpu"],
sources=["interface.pyx","source.cpp"],
extra_compile_args=['-std=gnu++14','-O3'],
language="c++"),
],
cmdclass = {'build_ext': build_ext},
)
Compiled with
python setup.py build_ext -i
@pthon can you ping me on the slack channel linked in the README ?