缓存(一)——缓存总览:从性能优化的角度看缓存
amandakelake opened this issue · comments

网上关于缓存的文章非常多,但大都比较片面,或者只对某块进行了深入,没有把它们联系起来,本着系统学习的态度,笔者进行了整理,写成一个小系列,方便自己也方便他人共同学习。
本篇文章不会讲细讲各种缓存的详细用法,笔者试图站在宏观的角度去分析各类缓存技术的优缺点、应用场景,力图寻找比较好的实践搭配。
本篇文章是总览,最好是先对下面的缓存技术有基础理解再来看
详细缓存介绍可参考下面链接
缓存(二)——浏览器缓存机制:强缓存、协商缓存
缓存(三)——数据存储:cookie、Storage、indexedDB
缓存(四)——离线应用缓存:App Cache => Manifest
缓存(五)——离线应用缓存:Service Worker(还没写,先占坑)
一、缓存的作用
重用已获取的资源,减少延迟与网络阻塞,进而减少显示某个资源所用的时间,借助 HTTP 缓存,Web 站点变得更具有响应性。
其实我们对于页面静态资源的要求就两点
1、静态资源加载速度
2、页面渲染速度
页面渲染速度建立在资源加载速度之上,但不同资源类型的加载顺序和时机也会对其产生影响,所以缓存的可操作空间非常大
二、缓存分类
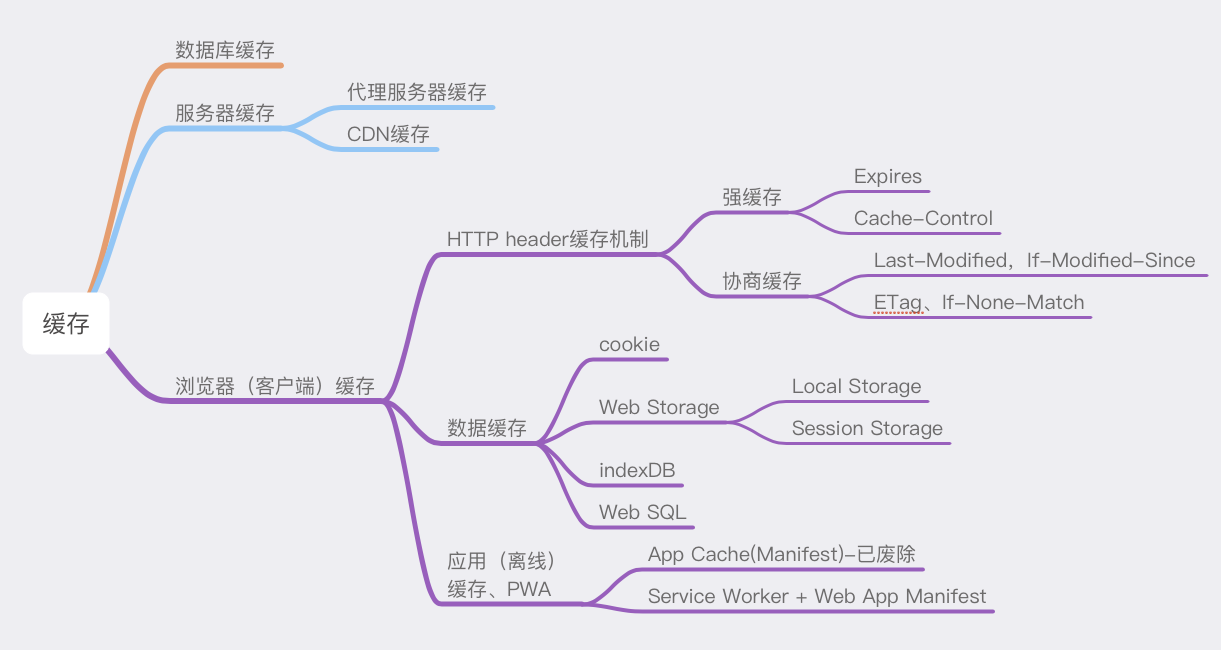
整个系列只讨论浏览器(客户端)方面的缓存
三、缓存应该放在哪里?
在 Web 应用中使用缓存是一种改善响应时间和减少 CPU 使用的绝佳方式,但是,缓存应该放置在架构的哪个环节中呢?
这里不直接给答案(我不会告诉你是我给不出答案😂),通过分析的方式来引导大家,分析自己的项目的性能问题,性能瓶颈在哪?
是文件太大,还是请求数量太多?
重复的无效请求是否太多?
数据或者结果可以缓存吗?
这些数据、结果、文件的刷新率如何,容易失效吗?
这些问题,一千个项目有一千个答案,只有弄明白了缓存的核心原理,才能以不变应万变,信手沾来。
四、缓存的一些应用场景
1、每次都加载某个同样的静态文件 => 浪费带宽,重复请求 => 让浏览器使用本地缓存(协商缓存,返回304)
2、协商缓存还是要和服务器通信啊 => 有网络请求,不太舒服,感觉很low => 强制浏览器使用本地强缓存(返回200)
3、缓存要更新啊,兄弟,网络请求都没了,我咋知道啥时候要更新?=> 让请求(header加上ETag)或者url的修改与文件内容关联(文件名加哈希值)=> 开心,感觉自己很牛逼
4、CTO大佬说,我们买了阿里还是腾讯的CDN,几百G呢,用起来啊 => 把静态资源和动态网页分集群部署,静态资源部署到CDN节点上,网页中引用的资源变成对应的部署路径 => html中的资源引用和CDN上的静态资源对应的url地址联系起来了 => 问题来了,更新的时候先上线页面,还是先上线静态资源?(蠢,等到半天三四点啊,用户都睡了,随便你先上哪个)
5、老板说:我们的产品将来是国际化的,不存在所谓的半夜三点 => GG,咋办?=> 用非覆盖式发布啊,用文件的摘要信息来对资源文件进行重命名,把摘要信息放到资源文件发布路径中,这样,内容有修改的资源就变成了一个新的文件发布到线上,不会覆盖已有的资源文件。上线过程中,先全量部署静态资源,再灰度部署页面
五、各类缓存技术优缺点
1、cookie
优点:对于传输部分少量不敏感数据,非常简明有效
缺点:容量小(4K),不安全(cookie被拦截,很可能暴露session);原生接口不够友好,需要自己封装;需要指定作用域,不可以跨域调用
2、Web Storage
容量稍大一点(5M),localStorage可做持久化数据存储
支持事件通知机制,可以将数据更新的通知发送给监听者
缺点:本地储存数据都容易被篡改,容易受到XSS攻击
缓存读取需要依靠js的执行,所以前提条件就是能够读取到html及js代码段,其次文件的版本更新控制会带来更多的代码层面的维护成本,所以LocalStorage更适合关键的业务数据而非静态资源
Cookie的作用是与服务器进行交互,作为HTTP规范的一部分而存在 ,而Web Storage仅仅是为了在本地“存储”数据而生
3、indexDB
IndexedDb提供了一个结构化的、事务型的、高性能的NoSQL类型的数据库,包含了一组同步/异步API,这部分不好判断优缺点,主要看使用者。
4、Manifest(已经被web标准废除)
优点
- 可以离线运行
- 可以减少资源请求
- 可以更新资源
缺点
- 更新的资源,需要二次刷新才会被页面采用
- 不支持增量更新,只有manifest发生变化,所有资源全部重新下载一次
- 缺乏足够容错机制,当清单中任意资源文件出现加载异常,都会导致整个manifest策略运行异常
Manifest被移除是技术发展的必然,请拥抱Service Worker吧
5、PWA(Service Worker)
这位目前是最炙手可热的缓存明星,是官方建议替代Application Cache(Manifest)的方案
作为一个独立的线程,是一段在后台运行的脚本,可使web app也具有类似原生App的离线使用、消息推送、后台自动更新等能力
目前有三个限制(不能明说是缺点)
- 不能访问 DOM
- 不能使用同步 API
- 需要HTTPS协议
六、缓存实践(视项目而定,不要死板)
1、大公司静态资源优化方案
- 配置超长时间的本地缓存 —— 节省带宽,提高性能
- 采用内容摘要作为缓存更新依据 —— 精确的缓存控制
- 静态资源CDN部署 —— 优化网络请求
- 更资源发布路径实现非覆盖式发布 —— 平滑升级
2、利用浏览器缓存机制
- 对于某些不需要缓存的资源,可以使用 Cache-control: no-store ,表示该资源不需要缓存
- 对于频繁变动的资源(比如经常需要刷新的首页,资讯论坛新闻类),可以使用 Cache-Control: no-cache 并配合 ETag 使用,表示该资源已被缓存,但是每次都会发送请求询问资源是否更新。
- 对于代码文件来说,通常使用 Cache-Control: max-age=31536000 并配合策略缓存使用,然后对文件进行指纹处理,一旦文件名变动就会立刻下载新的文件。
3、静态资源文件通过Service Worker进行缓存控制和离线化加载
后记
感谢您耐心看到这里,希望有所收获!
如果不是很忙的话,麻烦点个star⭐【Github博客传送门】,举手之劳,却是对作者莫大的鼓励。
我在学习过程中喜欢做记录,分享的是自己在前端之路上的一些积累和思考,希望能跟大家一起交流与进步,更多文章请看【amandakelake的Github博客】
参考
浏览器缓存、CacheStorage、Web Worker 与 Service Worker · Issue #113 · youngwind/blog · GitHub
关于前端缓存优化,为什么没人用manifest? - 知乎
变态的静态资源缓存与更新 - Div.IO
大话WEB前端性能优化基本套路

nice topic