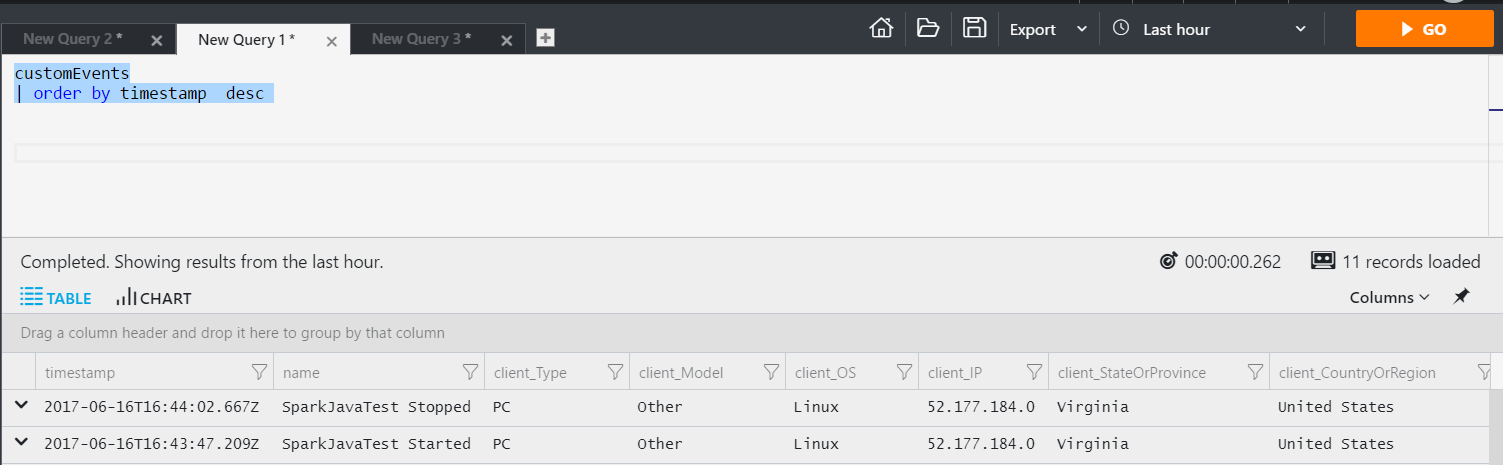
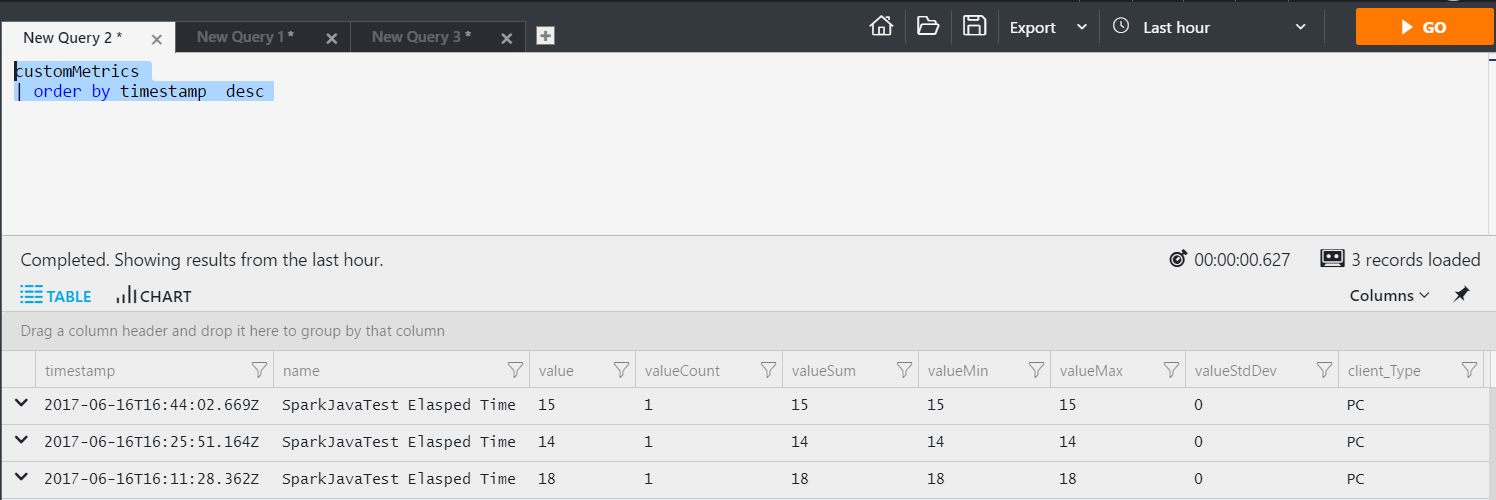
Use Spark with Livy along with Application Insights. Learn to host your external dependencies in data lake. This means you can use HDInsight as a transient (or stateless) cluster. Keep your code on Azure Data Lake Store, keep your dependencies on Azure Data Lake Store and then invoke via a REST call from any computer. There is no need to deploy any code to the actual cluster.
1 - Create a Azure Data Lake Storage account
- Create a root folder called "livy"
- Create a folder under livy called "code" and upload the SparkJava.jar inside of the folder
- Upload the applicationinsights-core-1.0.8.jar to the code folder as well
- Create a folder under livy called "input" and upload the HVAC.csv inside of the folder
- Create a folder under livy called "output"
2 - Create a Spark cluster (Spark 2.x) that uses Data Lake as its main storage and when you create the Service Principle grant acess to the /clusters directory and the /livy directory
3 - Run a job via Livy (open a Windows Bash or Linux prompt)
Simple Java code to read from data lake, download dependent JARS from data lake and write to data lake. You can instrument your code with Application Insights to see how your code is performing.
1 - Type "nano SparkJava1.txt" (or use VI or whatever) and place the below in the file. Change the << >> items.
{ "args":
[
"<<APPLICATION INSIGHTS Instrumentation Key GUID from Azure Portal>>"
"adl://<<YOUR-DATA-LAKE>>.azuredatalakestore.net/livy/input/HVAC.csv",
"adl://<<YOUR-DATA-LAKE>>.azuredatalakestore.net/livy/output/AppInsight"
],
"jars":[
"adl://<<YOUR-DATA-LAKE>>.azuredatalakestore.net/livy/code/applicationinsights-core-1.0.8.jar"
],
"file":"adl://<<YOUR-DATA-LAKE>>.azuredatalakestore.net/livy/code/SparkJava.jar",
"className":"sample.SparkJavaTest" }
2 - Run the job via Livy. You need to delete your output folder if it exists (e.g. /livy/output/ADLSIOTest)
curl -k --user "admin:<<YOUR-HDI-PASSWORD>>" -v -H "Content-Type: application/json" -X POST --data @SparkJava1.txt "<<YOUR-HDI-CLUSTERNAME>>.azurehdinsight.net/livy/batches"
3 - Get the status. The prior command will return a "id": ? (replace the 0 below with the ?) You can run this over and over to see the jobs status.
curl -k --user "admin:<<YOUR-HDI-PASSWORD>>" -v -X GET "<<YOUR-HDI-CLUSTERNAME>>.azurehdinsight.net/livy/batches/0"
4 - Delete the batch
curl -k --user "admin:<<YOUR-HDI-PASSWORD>>" -v -X DELETE "<<YOUR-HDI-CLUSTERNAME>>.azurehdinsight.net/livy/batches/0"
If you want to run your code on your cluster you can run like this
spark-submit --master yarn --deploy-mode cluster --jars adl://<<YOUR-DATA-LAKE>>.azuredatalakestore.net/livy/code/applicationinsights-core-1.0.8.jar --class sample.SparkJavaTest SparkJava.jar "<<APPLICATION INSIGHTS Instrumentation Key>>" adl://<<YOUR-DATA-LAKE>>.azuredatalakestore.net/livy/input/HVAC.csv adl://<<YOUR-DATA-LAKE>>.azuredatalakestore.net/livy/output/app20
You can now see the data inside of Application Insights. This data can then be surfaced in OMS and shown on a dashboard. By instrumenting your Spark jobs with good metrics will allow you to see whats happening inside your code while being processed by Spark.