torchinfo.summary() does not show internal layers of torch.nn.TransformerEncoderLayer (in version 1.7.1)
AlessandroMiola opened this issue · comments

Describe the bug
I'm observing a potential regression happening in torchinfo==1.7.1 (compared to torchinfo==1.7.0) as I try to get the summary of a torch.nn.TransformerEncoderLayer model (torch version 1.13.1).
What I get:
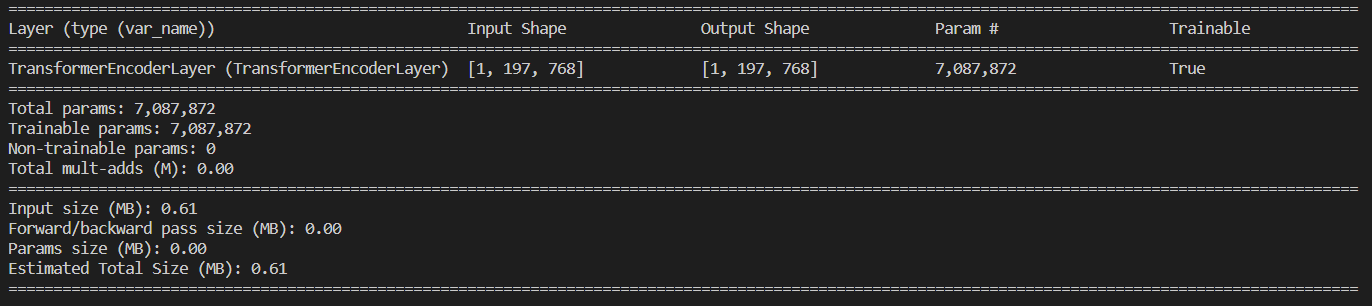
What I'd expect (obtained with torchinfo==1.7.0); actually, even with version 1.7.0 input and output shapes are missing.
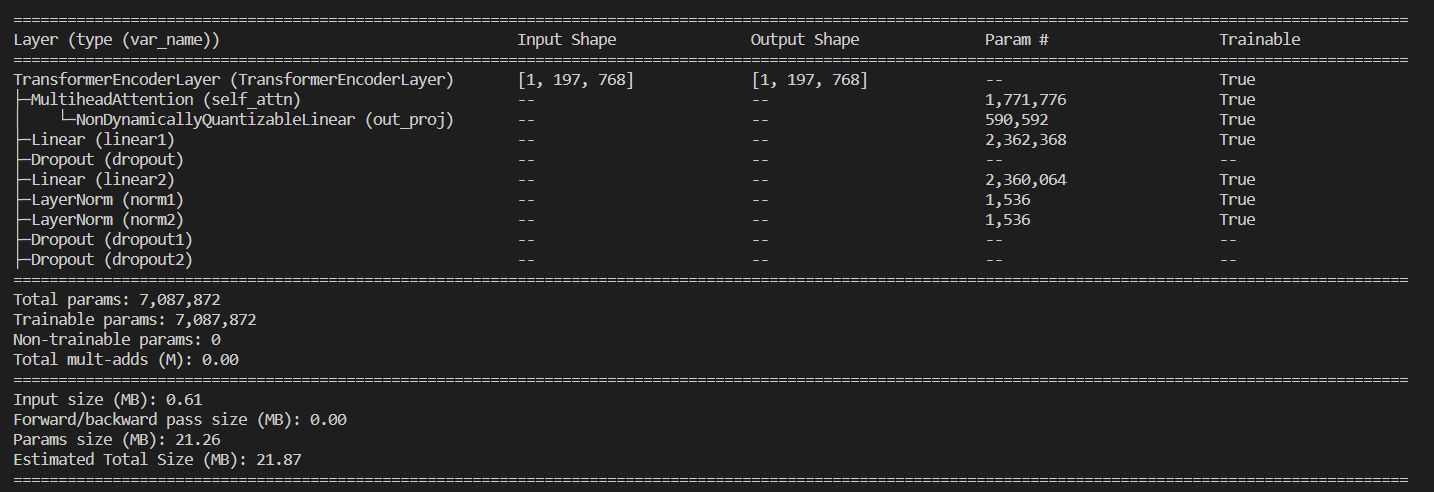
To Reproduce
from torchinfo import summary
from torch import nn
torch_transformer_encoder = nn.TransformerEncoderLayer(d_model=768, nhead=12, dim_feedforward=3072, dropout=0.1,
activation='gelu', batch_first=True, norm_first=True)
summary(model=torch_transformer_encoder, input_size=(1, 197, 768),
col_names=['input_size', 'output_size', 'num_params', 'trainable'], row_settings=['var_names'])

The problem here is that torch.nn.TransformerEncoderLayer only executes its modules under some circumstances (more on that below).
The solution:
Run your summary with mode="train" as an argument.
Input:
from torchinfo import summary
from torch import nn
torch_transformer_encoder = nn.TransformerEncoderLayer(d_model=768, nhead=12, dim_feedforward=3072, dropout=0.1,
activation='gelu', batch_first=True, norm_first=True)
summary(model=torch_transformer_encoder, input_size=(1, 197, 768), mode="train",
col_names=['input_size', 'output_size', 'num_params', 'trainable'], row_settings=['var_names'])Output:
======================================================================================================================================================
Layer (type (var_name)) Input Shape Output Shape Param # Trainable
======================================================================================================================================================
TransformerEncoderLayer (TransformerEncoderLayer) [1, 197, 768] [1, 197, 768] -- True
├─LayerNorm (norm1) [1, 197, 768] [1, 197, 768] 1,536 True
├─MultiheadAttention (self_attn) [1, 197, 768] [1, 197, 768] 2,362,368 True
├─Dropout (dropout1) [1, 197, 768] [1, 197, 768] -- --
├─LayerNorm (norm2) [1, 197, 768] [1, 197, 768] 1,536 True
├─Linear (linear1) [1, 197, 768] [1, 197, 3072] 2,362,368 True
├─Dropout (dropout) [1, 197, 3072] [1, 197, 3072] -- --
├─Linear (linear2) [1, 197, 3072] [1, 197, 768] 2,360,064 True
├─Dropout (dropout2) [1, 197, 768] [1, 197, 768] -- --
======================================================================================================================================================
Total params: 7,087,872
Trainable params: 7,087,872
Non-trainable params: 0
Total mult-adds (M): 4.73
======================================================================================================================================================
Input size (MB): 0.61
Forward/backward pass size (MB): 8.47
Params size (MB): 18.90
Estimated Total Size (MB): 27.98
======================================================================================================================================================
The cause:
Under certain circumstances, torch.nn.TransformerEncoderLayer takes a fast execution path that doesn't actually execute the layers of the module. Since summary works by adding a hook to each torch.nn.Module, these hooks will not be executed either under those circumstances, and the module will not be counted individually. There is little that can be done about this on the side of torchinfo, at least as far as I know.
However, setting mode="train" triggers a circumstance where the fast path isn't taken and, therefore, all modules are actually executed. If you want to find out all of the circumstances under which the fast path is or isn't, take a look at the source-code of torch.nn.TransformerEncoderLayer (fair warning: it's a lot).
As you can see, though, the total memory consumption & parameter number is the same in "train"-mode as in "eval"-mode (the default for summary), so this should tell you what you need to know.
Thank you! :)
Closing