customization dataset在fine-tune和inference的输入不同。
jiangix-paper opened this issue · comments

Hello,我们目前使用CustomizationDataset类来处理自定义的input和output。
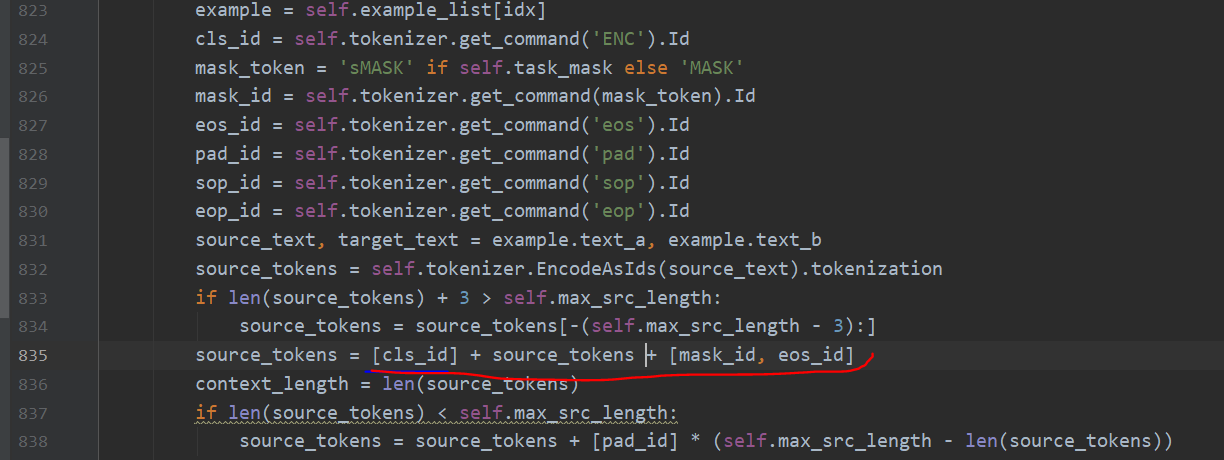
fine-tune的时候,source_tokens的处理方式是在前面加一个cls_id,在后面加一个mask_id和eos_id。(见下图,图中代码来自tasks/seq2seq/dataset.py):
但是在inference的时候,context_tokens的处理方式是在前面加一个cls_id,在后面加一个eos_id或者[gMASK]。(见下图,图中代码来自generate_samples.py)

请问这是否会导致inference和finetune的数据格式有一些不同,会有影响吗?是否应该统一格式为:[cls_id] + tokens + [gMASK]呢?
非常感谢。

因为generate_samples.py不是用于seq2seq任务的inference的。seq2seq的inference也应该使用训练的脚本。目前的代码里在training结束之后会自动进行inference,如果只想进行inference的话可以设置--epochs 0。
如果一定要用generate_samples.py的话可以在输入的文本后面加上[MASK],这样的话格式就和seq2seq任务一样了。