Reproduce of nested NER
iofu728 opened this issue · comments

Hi Xiaoya,
Sorry to bother you again. I have some questions when reproduce the nested NER task using your model. (#10)
Env: Windows server 2016, 512G RAM, 8 P100
torch version: 1.1.0
other pip packages also the same as requirments.txt.
And using the BERT_base_uncased version.
We use the same data set file from you which almost the same as our data set.
We use the same hyperparameters with the log file in log fold and also train in 2 p100.
And run in two different machines.
To avoid inadequate training, we expand the epoch to 40.
ACE05
{
"bert_frozen": "false",
"hidden_size": 768,
"hidden_dropout_prob": 0.2,
"classifier_sign": "multi_nonlinear",
"clip_grad": 1,
"bert_config": {
"attention_probs_dropout_prob": 0.1,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"type_vocab_size": 2,
"vocab_size": 30522
},
"config_path": "./config/en_bert_base_uncased.json",
"data_dir": "./data_preprocess/en_ace05",
"bert_model": "./uncased_L-12_H-768_A-12",
"task_name": null,
"max_seq_length": 150,
"train_batch_size": 32,
"dev_batch_size": 32,
"test_batch_size": 32,
"checkpoint": 600,
"learning_rate": 4e-05,
"num_train_epochs": 40,
"warmup_proportion": -1.0,
"local_rank": -1,
"gradient_accumulation_steps": 1,
"seed": 2333,
"export_model": false,
"output_dir": "./result-05",
"data_sign": "ace2005",
"weight_start": 1.0,
"weight_end": 1.0,
"weight_span": 1.0,
"entity_sign": "nested",
"n_gpu": 2,
"dropout": 0.2,
"entity_threshold": 0.5,
"data_cache": false
}
we only get 81.60% in ACE04 and 79.53% in ACE05.
There are big gaps in your public performance.
- Do you use BERT_base instead of BERT_large?
- Do you have some other trick not in the above processing?
- Could you public the pre-trained model which accord with your result?
Thx!

您能把完整全部的 log 粘贴一下嘛 ?
The ace04 log is shown in that:
I forgot to save the log of ACE05, I'll update when I rerun the experiment.
Better speed can be achieved with apex installed from https://www.github.com/nvidia/apex.
Better speed can be achieved with apex installed from https://www.github.com/nvidia/apex.
Please notice that merge the args_dict and json_config ... ...
{
"bert_frozen": "false",
"hidden_size": 768,
"hidden_dropout_prob": 0.2,
"classifier_sign": "multi_nonlinear",
"clip_grad": 1,
"bert_config": {
"attention_probs_dropout_prob": 0.1,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"type_vocab_size": 2,
"vocab_size": 30522
},
"config_path": "./config/en_bert_base_uncased.json",
"data_dir": "./data_preprocess/en_ace04",
"bert_model": "./uncased_L-12_H-768_A-12",
"task_name": null,
"max_seq_length": 150,
"train_batch_size": 32,
"dev_batch_size": 32,
"test_batch_size": 32,
"checkpoint": 1200,
"learning_rate": 4e-05,
"num_train_epochs": 40,
"warmup_proportion": -1.0,
"local_rank": -1,
"gradient_accumulation_steps": 1,
"seed": 2333,
"export_model": false,
"output_dir": "./result-04",
"data_sign": "ace2004",
"weight_start": 1.0,
"weight_end": 1.0,
"weight_span": 1.0,
"entity_sign": "nested",
"n_gpu": 2,
"dropout": 0.1,
"entity_threshold": 0.5,
"data_cache": false
}
-*--*--*--*--*--*--*--*--*--*-
current data_sign: ace2004
=*==*==*==*==*==*==*==*==*==*=
loading train data ... ...
43386
43386 train data loaded
=*==*==*==*==*==*==*==*==*==*=
loading dev data ... ...
5194
5194 dev data loaded
=*==*==*==*==*==*==*==*==*==*=
loading test data ... ...
5663
5663 test data loaded
######################################################################
EPOCH: 0
C:\Users\v-huji\AppData\Local\conda\conda\envs\py36\lib\site-packages\torch\nn\parallel\_functions.py:61: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.
warnings.warn('Was asked to gather along dimension 0, but all '
C:\Users\v-huji\AppData\Local\conda\conda\envs\py36\lib\site-packages\torch\cuda\nccl.py:24: UserWarning: PyTorch is not compiled with NCCL support
warnings.warn('PyTorch is not compiled with NCCL support')
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
0.00652815867215395
............................................................
DEV: loss, acc, precision, recall, f1
0.0057 0.999 1.0 0.0008 0.0016
............................................................
TEST: loss, acc, precision, recall, f1
0.0063 0.9989 0.0 0.0 0.0
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 1
current learning rate 3.8e-05
current learning rate 3.8e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
0.004867232870310545
............................................................
DEV: loss, acc, precision, recall, f1
0.0051 0.9992 0.6487 0.354 0.4581
............................................................
TEST: loss, acc, precision, recall, f1
0.0055 0.9991 0.6499 0.3665 0.4687
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 2
current learning rate 3.61e-05
current learning rate 3.61e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
0.001277540810406208
............................................................
DEV: loss, acc, precision, recall, f1
0.0062 0.9991 0.6174 0.4789 0.5394
............................................................
TEST: loss, acc, precision, recall, f1
0.0066 0.999 0.6265 0.5059 0.5598
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 3
current learning rate 3.4295e-05
current learning rate 3.4295e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
0.0001508248969912529
............................................................
DEV: loss, acc, precision, recall, f1
0.0069 0.9992 0.6282 0.5788 0.6025
............................................................
TEST: loss, acc, precision, recall, f1
0.0074 0.9991 0.6411 0.6028 0.6214
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 4
current learning rate 3.258025e-05
current learning rate 3.258025e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
0.0001224315055878833
............................................................
DEV: loss, acc, precision, recall, f1
0.0064 0.9992 0.648 0.5756 0.6096
............................................................
TEST: loss, acc, precision, recall, f1
0.0075 0.9991 0.6475 0.5837 0.614
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 5
current learning rate 3.09512375e-05
current learning rate 3.09512375e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
0.00014074974751565605
............................................................
DEV: loss, acc, precision, recall, f1
0.0083 0.9992 0.7045 0.5338 0.6074
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 6
current learning rate 2.9403675625e-05
current learning rate 2.9403675625e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
7.892670691944659e-05
............................................................
DEV: loss, acc, precision, recall, f1
0.0073 0.9992 0.7261 0.5461 0.6234
............................................................
TEST: loss, acc, precision, recall, f1
0.0084 0.9991 0.7254 0.5432 0.6212
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 7
current learning rate 2.7933491843749998e-05
current learning rate 2.7933491843749998e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
9.254754695575684e-05
............................................................
DEV: loss, acc, precision, recall, f1
0.0077 0.9992 0.7161 0.5839 0.6433
............................................................
TEST: loss, acc, precision, recall, f1
0.0086 0.9991 0.7148 0.5775 0.6388
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 8
current learning rate 2.6536817251562497e-05
current learning rate 2.6536817251562497e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
2.4751951059442945e-05
............................................................
DEV: loss, acc, precision, recall, f1
0.0071 0.9992 0.7543 0.5446 0.6325
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 9
current learning rate 2.5209976388984372e-05
current learning rate 2.5209976388984372e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
7.874517905293033e-05
............................................................
DEV: loss, acc, precision, recall, f1
0.0073 0.9992 0.7498 0.6245 0.6814
............................................................
TEST: loss, acc, precision, recall, f1
0.0081 0.9991 0.7469 0.6236 0.6797
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 10
current learning rate 2.3949477569535154e-05
current learning rate 2.3949477569535154e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
3.129472315777093e-05
............................................................
DEV: loss, acc, precision, recall, f1
0.0086 0.9992 0.7308 0.6436 0.6844
............................................................
TEST: loss, acc, precision, recall, f1
0.0094 0.9992 0.7368 0.6513 0.6914
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 11
current learning rate 2.2752003691058396e-05
current learning rate 2.2752003691058396e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
8.153247108566575e-06
............................................................
DEV: loss, acc, precision, recall, f1
0.009 0.9992 0.7535 0.671 0.7099
............................................................
TEST: loss, acc, precision, recall, f1
0.0102 0.9991 0.7471 0.6602 0.701
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 12
current learning rate 2.1614403506505474e-05
current learning rate 2.1614403506505474e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
2.965316343761515e-05
............................................................
DEV: loss, acc, precision, recall, f1
0.0087 0.9992 0.7931 0.6344 0.705
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 13
current learning rate 2.05336833311802e-05
current learning rate 2.05336833311802e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
5.13375925947912e-06
............................................................
DEV: loss, acc, precision, recall, f1
0.0097 0.9992 0.8016 0.6412 0.7125
............................................................
TEST: loss, acc, precision, recall, f1
0.0111 0.9991 0.8039 0.6444 0.7153
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 14
current learning rate 1.9506999164621187e-05
current learning rate 1.9506999164621187e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
6.1994778661755845e-06
............................................................
DEV: loss, acc, precision, recall, f1
0.0084 0.9992 0.7668 0.714 0.7394
............................................................
TEST: loss, acc, precision, recall, f1
0.0094 0.9991 0.7698 0.703 0.7349
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 15
current learning rate 1.8531649206390126e-05
current learning rate 1.8531649206390126e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
0.00030320900259539485
............................................................
DEV: loss, acc, precision, recall, f1
0.009 0.9992 0.7832 0.7156 0.7479
............................................................
TEST: loss, acc, precision, recall, f1
0.0102 0.9992 0.8013 0.7044 0.7497
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 16
current learning rate 1.760506674607062e-05
current learning rate 1.760506674607062e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
1.1917554729734547e-05
............................................................
DEV: loss, acc, precision, recall, f1
0.0095 0.9992 0.8111 0.7053 0.7545
............................................................
TEST: loss, acc, precision, recall, f1
0.0108 0.9992 0.8265 0.6971 0.7563
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 17
current learning rate 1.6724813408767087e-05
current learning rate 1.6724813408767087e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
2.0397035314090317e-06
............................................................
DEV: loss, acc, precision, recall, f1
0.0104 0.9992 0.7756 0.7645 0.77
............................................................
TEST: loss, acc, precision, recall, f1
0.0115 0.9992 0.7858 0.7531 0.7691
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 18
current learning rate 1.5888572738328732e-05
current learning rate 1.5888572738328732e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
1.7638874396652682e-06
............................................................
DEV: loss, acc, precision, recall, f1
0.0105 0.9992 0.7877 0.7689 0.7782
............................................................
TEST: loss, acc, precision, recall, f1
0.0115 0.9992 0.7907 0.762 0.7761
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 19
current learning rate 1.5094144101412296e-05
current learning rate 1.5094144101412296e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
1.9983542642876273e-06
............................................................
DEV: loss, acc, precision, recall, f1
0.0106 0.9992 0.7844 0.7784 0.7814
............................................................
TEST: loss, acc, precision, recall, f1
0.0117 0.9992 0.7889 0.7713 0.78
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 20
current learning rate 1.433943689634168e-05
current learning rate 1.433943689634168e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
5.718513421015814e-06
............................................................
DEV: loss, acc, precision, recall, f1
0.01 0.9992 0.7813 0.7872 0.7842
............................................................
TEST: loss, acc, precision, recall, f1
0.011 0.9992 0.7949 0.7884 0.7917
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 21
current learning rate 1.3622465051524595e-05
current learning rate 1.3622465051524595e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
1.830667656577134e-06
............................................................
DEV: loss, acc, precision, recall, f1
0.01 0.9992 0.8072 0.7693 0.7878
............................................................
TEST: loss, acc, precision, recall, f1
0.0109 0.9992 0.809 0.7564 0.7818
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 22
current learning rate 1.2941341798948365e-05
current learning rate 1.2941341798948365e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
1.6623400370008312e-05
............................................................
DEV: loss, acc, precision, recall, f1
0.0107 0.9992 0.7946 0.7633 0.7787
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 23
current learning rate 1.2294274709000947e-05
current learning rate 1.2294274709000947e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
2.339475031476468e-06
............................................................
DEV: loss, acc, precision, recall, f1
0.0096 0.9992 0.7899 0.7808 0.7854
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 24
current learning rate 1.1679560973550899e-05
current learning rate 1.1679560973550899e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
5.6940825743367895e-06
............................................................
DEV: loss, acc, precision, recall, f1
0.0102 0.9992 0.7891 0.786 0.7876
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 25
current learning rate 1.1095582924873354e-05
current learning rate 1.1095582924873354e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
1.2384186447889078e-05
............................................................
DEV: loss, acc, precision, recall, f1
0.0098 0.9992 0.8188 0.7693 0.7933
............................................................
TEST: loss, acc, precision, recall, f1
0.0109 0.9992 0.8161 0.765 0.7897
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 26
current learning rate 1.0540803778629686e-05
current learning rate 1.0540803778629686e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
4.481231599129387e-07
............................................................
DEV: loss, acc, precision, recall, f1
0.0106 0.9992 0.7981 0.7908 0.7944
............................................................
TEST: loss, acc, precision, recall, f1
0.0117 0.9992 0.8064 0.7868 0.7965
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 27
current learning rate 1.0013763589698201e-05
current learning rate 1.0013763589698201e-05
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
3.444522747031442e-07
............................................................
DEV: loss, acc, precision, recall, f1
0.0115 0.9992 0.8048 0.7804 0.7924
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 28
current learning rate 9.513075410213291e-06
current learning rate 9.513075410213291e-06
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
3.432829203120491e-07
............................................................
DEV: loss, acc, precision, recall, f1
0.0112 0.9992 0.8024 0.7836 0.7929
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 29
current learning rate 9.037421639702626e-06
current learning rate 9.037421639702626e-06
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
2.3454384745491552e-07
............................................................
DEV: loss, acc, precision, recall, f1
0.0122 0.9992 0.8057 0.7951 0.8004
............................................................
TEST: loss, acc, precision, recall, f1
0.0133 0.9992 0.8217 0.8022 0.8119
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 30
current learning rate 8.585550557717495e-06
current learning rate 8.585550557717495e-06
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
1.9482548907490127e-07
............................................................
DEV: loss, acc, precision, recall, f1
0.0125 0.9992 0.8064 0.7987 0.8026
............................................................
TEST: loss, acc, precision, recall, f1
0.0136 0.9992 0.8214 0.8065 0.8139
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 31
current learning rate 8.156273029831619e-06
current learning rate 8.156273029831619e-06
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
1.7994915424424107e-07
............................................................
DEV: loss, acc, precision, recall, f1
0.0127 0.9992 0.8058 0.8039 0.8049
............................................................
TEST: loss, acc, precision, recall, f1
0.0138 0.9992 0.8212 0.8098 0.8155
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 32
current learning rate 7.748459378340037e-06
current learning rate 7.748459378340037e-06
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
1.4884719234942168e-07
............................................................
DEV: loss, acc, precision, recall, f1
0.0129 0.9992 0.8051 0.8051 0.8051
............................................................
TEST: loss, acc, precision, recall, f1
0.014 0.9992 0.8242 0.8111 0.8176
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 33
current learning rate 7.361036409423035e-06
current learning rate 7.361036409423035e-06
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
1.801704456738662e-07
............................................................
DEV: loss, acc, precision, recall, f1
0.0117 0.9992 0.808 0.8035 0.8057
............................................................
TEST: loss, acc, precision, recall, f1
0.013 0.9992 0.8179 0.8098 0.8138
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 34
current learning rate 6.992984588951883e-06
current learning rate 6.992984588951883e-06
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
2.21550379819746e-07
............................................................
DEV: loss, acc, precision, recall, f1
0.0116 0.9992 0.8148 0.8015 0.8081
............................................................
TEST: loss, acc, precision, recall, f1
0.0128 0.9992 0.8268 0.8055 0.816
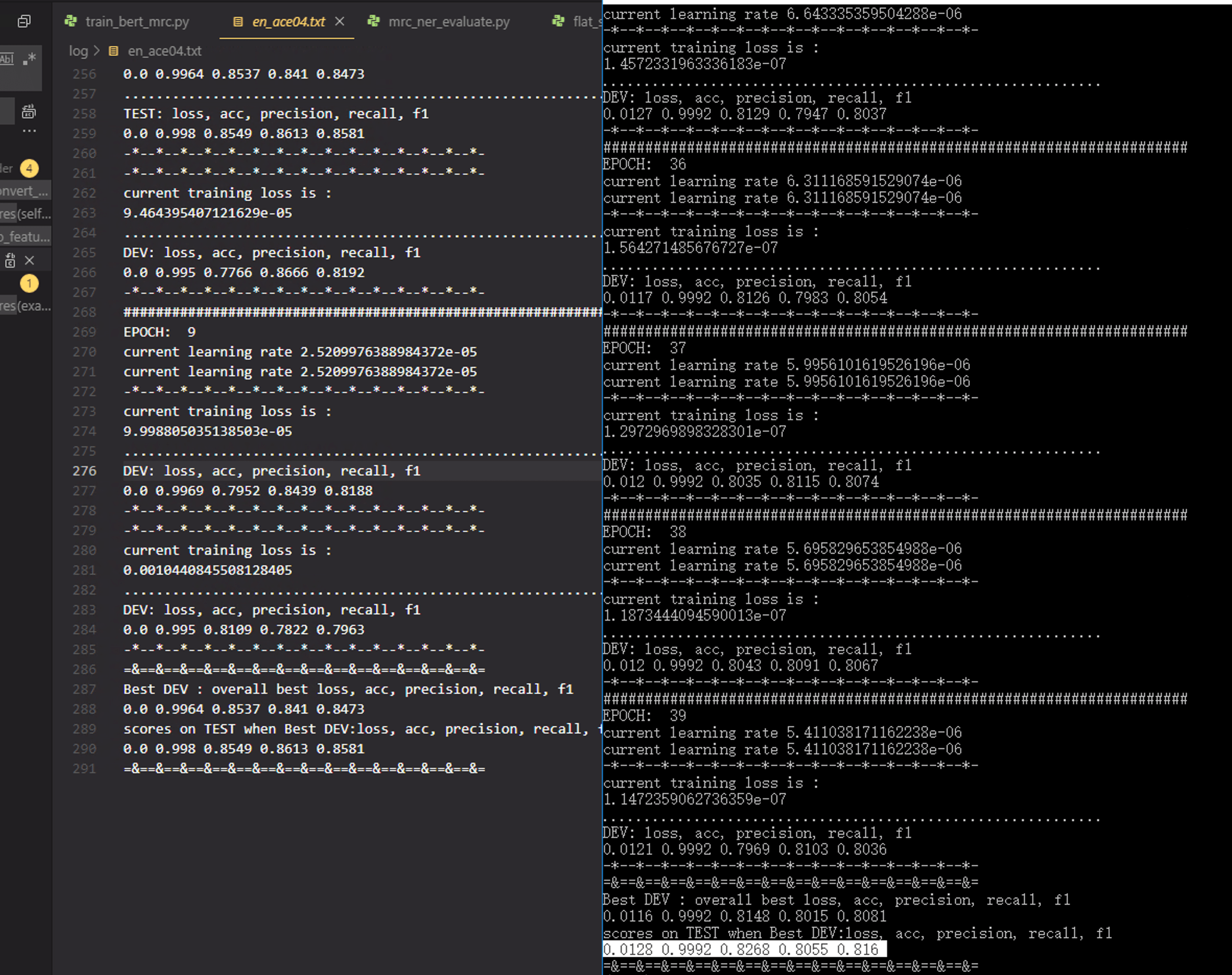
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 35
current learning rate 6.643335359504288e-06
current learning rate 6.643335359504288e-06
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
1.4572331963336183e-07
............................................................
DEV: loss, acc, precision, recall, f1
0.0127 0.9992 0.8129 0.7947 0.8037
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 36
current learning rate 6.311168591529074e-06
current learning rate 6.311168591529074e-06
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
1.564271485676727e-07
............................................................
DEV: loss, acc, precision, recall, f1
0.0117 0.9992 0.8126 0.7983 0.8054
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 37
current learning rate 5.9956101619526196e-06
current learning rate 5.9956101619526196e-06
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
1.2972969898328301e-07
............................................................
DEV: loss, acc, precision, recall, f1
0.012 0.9992 0.8035 0.8115 0.8074
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 38
current learning rate 5.695829653854988e-06
current learning rate 5.695829653854988e-06
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
1.1873444094590013e-07
............................................................
DEV: loss, acc, precision, recall, f1
0.012 0.9992 0.8043 0.8091 0.8067
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
######################################################################
EPOCH: 39
current learning rate 5.411038171162238e-06
current learning rate 5.411038171162238e-06
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
current training loss is :
1.1472359062736359e-07
............................................................
DEV: loss, acc, precision, recall, f1
0.0121 0.9992 0.7969 0.8103 0.8036
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
=&==&==&==&==&==&==&==&==&==&==&==&==&==&==&=
Best DEV : overall best loss, acc, precision, recall, f1
0.0116 0.9992 0.8148 0.8015 0.8081
scores on TEST when Best DEV:loss, acc, precision, recall, f1
0.0128 0.9992 0.8268 0.8055 0.816
=&==&==&==&==&==&==&==&==&==&==&==&==&==&==&=

1、Do you use BERT_base instead of BERT_large?
we used BERT_base
2、Do you have some other trick not in the above processing?
No. I think there might be something wrong. You should be able to reproduce the result if you exactly follow the instructions in the repo. Could you please exactly follow and not change the hyperparameters provided in the repo, e.g., train_epoch.
- Could you public the pre-trained model which accord with your result?
sure. https://drive.google.com/file/d/1RPYsS2dDxYyii7-3NkBNG7VtuA96NBLf/view?usp=sharing
1、Do you use BERT_base instead of BERT_large?
we used BERT_base2、Do you have some other trick not in the above processing?
No. I think there might be something wrong. You should be able to reproduce the result if you exactly follow the instructions in the repo. Could you please exactly follow and not change the hyperparameters provided in the repo, e.g., train_epoch.
- Could you public the pre-trained model which accord with your result?
sure. https://drive.google.com/file/d/1RPYsS2dDxYyii7-3NkBNG7VtuA96NBLf/view?usp=sharing
Thx. I'll check it. Does the pre-trained model for ACE04?
No hurry for replying due to the DDL and only to record this experiment's situation.
After evaluation, I also find some problems.
- It seems like your code has some change after that checkpoint.
I change thespan_embeddingfromMultiNonLinearClassifiertonn.Linearin https://github.com/ShannonAI/mrc-for-flat-nested-ner/blob/master/model/bert_mrc.py#L29 to fit this ckpt.
Traceback (most recent call last):
File "./run/evaluate_mrc_ner.py", line 205, in <module>
main()
File "./run/evaluate_mrc_ner.py", line 118, in main
test_loader, label_list = load_data(config)
File "./run/evaluate_mrc_ner.py", line 100, in load_data
test_dataloader = dataset_loaders.get_dataloader(data_sign="test")
File "E:\users\v-huji\mrc-for-flat-nested-ner\data_loader\mrc_data_loader.py", line 71, in get_dataloader
features = self.convert_examples_to_features(data_sign=data_sign)
File "E:\users\v-huji\mrc-for-flat-nested-ner\data_loader\mrc_data_loader.py", line 63, in convert_examples_to_features
features = convert_examples_to_features(examples, self.tokenizer, self.label_list, self.max_seq_length, allow_impossible=self.allow_impossible)
File "E:\users\v-huji\mrc-for-flat-nested-ner\data_loader\mrc_utils.py", line 144, in convert_examples_to_features
s_idx, e_idx = span_item.split(";")
ValueError: not enough values to unpack (expected 2, got 1)
- I don't know this ckpt is for ACE04 or ACE05, so I evaluate both but the performance are both low.
ACE04 0.9951786450055544 0.99999999995 0.0006591957811469789 0.001317523056521739
ACE05 0.9955207489422497 0.7777777777691358 0.0023109937273026637 0.004608294930284532
Thank you for your reply!

Hi Xiaoya,
Thank you for providing us an amazing idea for Nested NER. I've also reproduced the nested model on ace05 dataset and the F1 value is 0.796. I used the exact setting from the log file except that I extended the learning epoch to 20. So is there some bugs in this version? I am looking forward to your reply.

@iofu728
hello, I experimented on the ACE2004 data set provided by the author. The training effect is not as good as yours, only 50% F1. I suspect it is caused by the loss. Can you share how to calculate the MRC loss?
thanks!
@iofu728
hello, I experimented on the ACE2004 data set provided by the author. The training effect is not as good as yours, only 50% F1. I suspect it is caused by the loss. Can you share how to calculate the MRC loss?
thanks!
@ISGuXing
The code of the repository has changed a lot since the last time I read it.
But the three losses (start/end/mentioned) have not changed.
I read the code about your problem in issue #76.
In fact, this should be responded to by the owner of the repository.
The final loss depends on the parameter "span_loss_candidates".
"All" corresponds to the multitasking mode.
And the "gold" corresponding to the pipeline mode needs the start/end prediction results to guide the mentioned losses.
It is a model design issue.
It is difficult to directly predict the two-dimensional results through this model structure.
In this work, they use two sequence labeling results to decode the entity boundary information.
Some researchers use biaffine structures, while others use pyramid structures.
This is the key point of nested NER.
Hope this will help you.
@iofu728
hello, I experimented on the ACE2004 data set provided by the author. The training effect is not as good as yours, only 50% F1. I suspect it is caused by the loss. Can you share how to calculate the MRC loss?
thanks!@ISGuXing
The code of the repository has changed a lot since the last time I read it.
But the three losses (start/end/mentioned) have not changed.I read the code about your problem in issue #76.
In fact, this should be responded to by the owner of the repository.
The final loss depends on the parameter "span_loss_candidates".
"All" corresponds to the multitasking mode.
And the "gold" corresponding to the pipeline mode needs the start/end prediction results to guide the mentioned losses.
It is a model design issue.
It is difficult to directly predict the two-dimensional results through this model structure.
In this work, they use two sequence labeling results to decode the entity boundary information.
Some researchers use biaffine structures, while others use pyramid structures.
This is the key point of nested NER.Hope this will help you.
首先非常感谢您的回复,我很抱歉今天才给您回复。
您的意思是我使用gold label 计算损失没有问题。但是我最高只有50%左右的F1,其中还使用您贴出的log的一些超参数。难道需要把start/end loss 和 span loss 分开训练吗?我的意思是先训练好start/end linear层然后固定参数训练span的linear层吗?
至于您说的那两篇论文,我正在阅读。
此外在处理数据的时候有一个超参数possible_only我没有在您log中看到,于是我设置该超参数为possible_only=False,在训练集上,True、False我都尝试过,在test集和dev集上我均设置为False。但是依旧无法把模型的表现提升,F1也仅只有50%左右。
难道是还有什么需要值得注意的地方我没有考虑吗?
希望您不吝赐教,十分感谢!