Tesseract working out only the first five pages of documents
santangelo opened this issue · comments

Hi,
first of all thank you for this great work you did.
I have set up Ambar to crawl a number of pdfs in an Archive folder with subfolders containing pdfs.
It seemed to me that it was doing great, but I have just noticed in the crawler log that Tesseract is processing only the first five pages of the documents (attached screenshot).
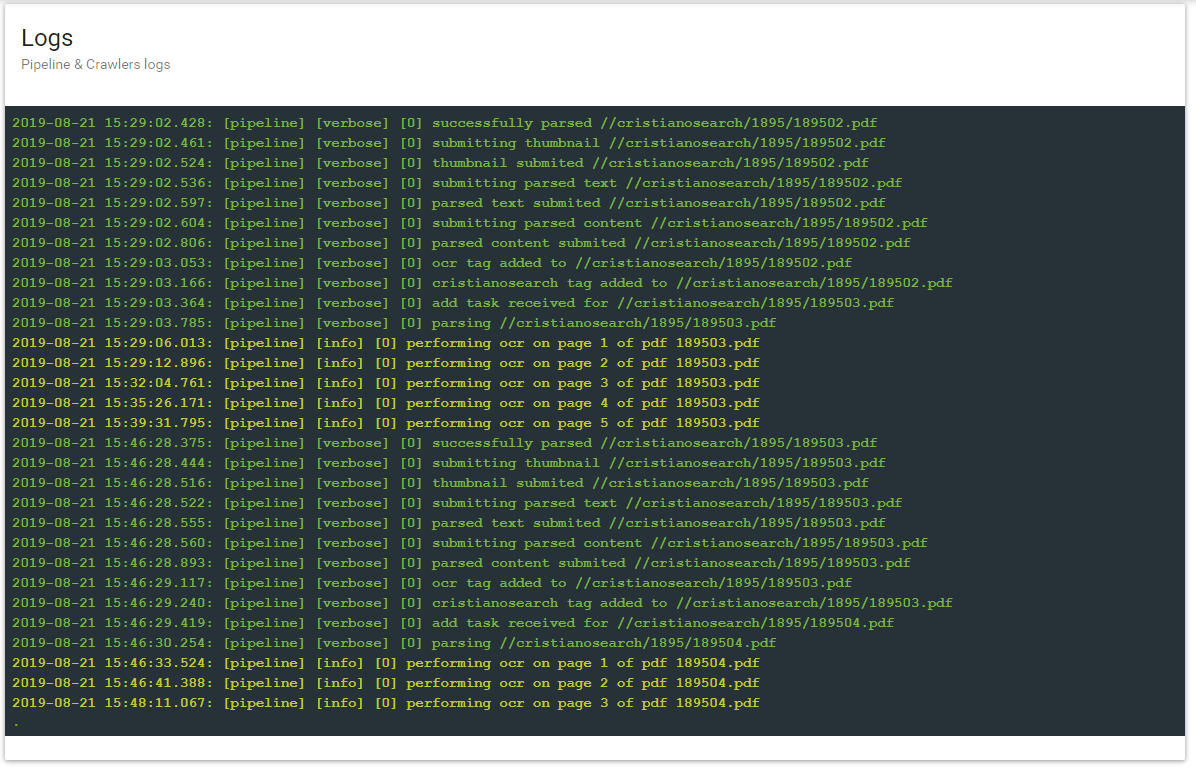
Of course the words from the 6th page on are not in the index.
Is there an option I did not know of?
Thanks a lot.
Michele
In case it helps other, it was enough to set the env var "ocrPdfMaxPageCount" to desired number of pages on pipeline container. Thanks to the Ambar help.
Michele