ddpg-aigym
Deep Deterministic Policy Gradient
Implementation of Deep Deterministic Policy Gradiet Algorithm (Lillicrap et al.arXiv:1509.02971.) in Tensorflow
How to use
git clone https://github.com/stevenpjg/ddpg-aigym.git
cd ddpg-aigym
python main.py
During training
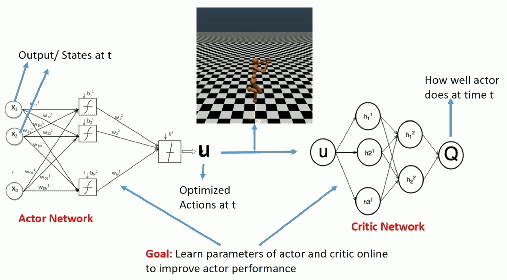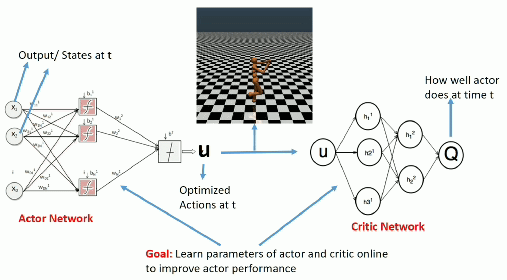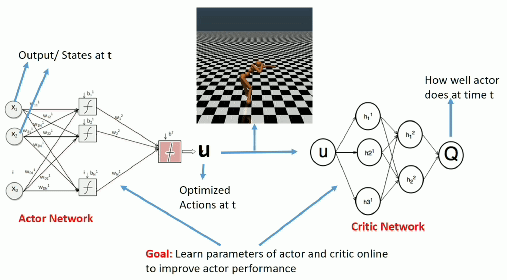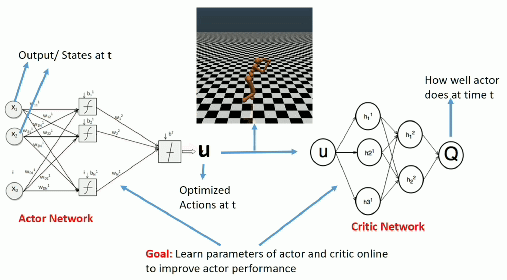
Once trained
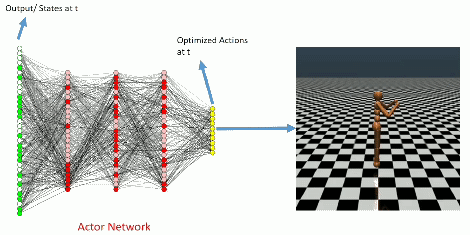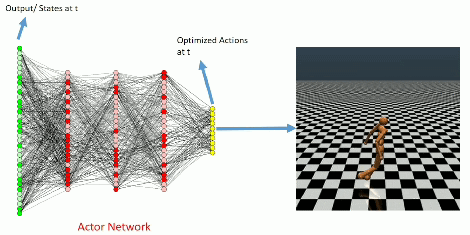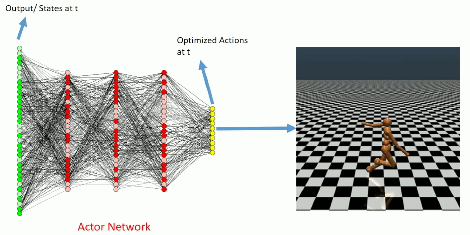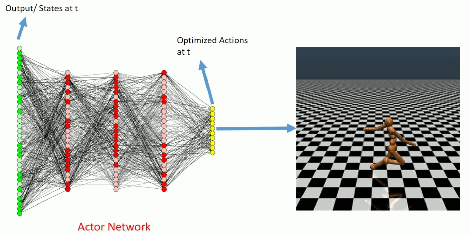
Learning Curve
The learning curve for InvertedPendulum-v1 environment.

Dependencies
- Tensorflow (Developed in tensorflow version 0.11.0rc0 [CPU version] [GPU version])
- OpenAi gym
- Mujoco
Features
- Batch Normalization (improvement in learning speed)
- Grad-inverter (given in arXiv: arXiv:1511.04143)
Note
To use different environment
experiment= 'InvertedPendulum-v1' #specify environments here
To use batch normalization
is_batch_norm = True #batch normalization switch
Let me know if there are any issues and clarifications regarding hyperparameter tuning.