
Send generator G(z) input vector z (100 dimension) as OSC message.
On Max for Live, use maxpat file as max audio effect (open .amxd).
then run run.py
can be used with videos
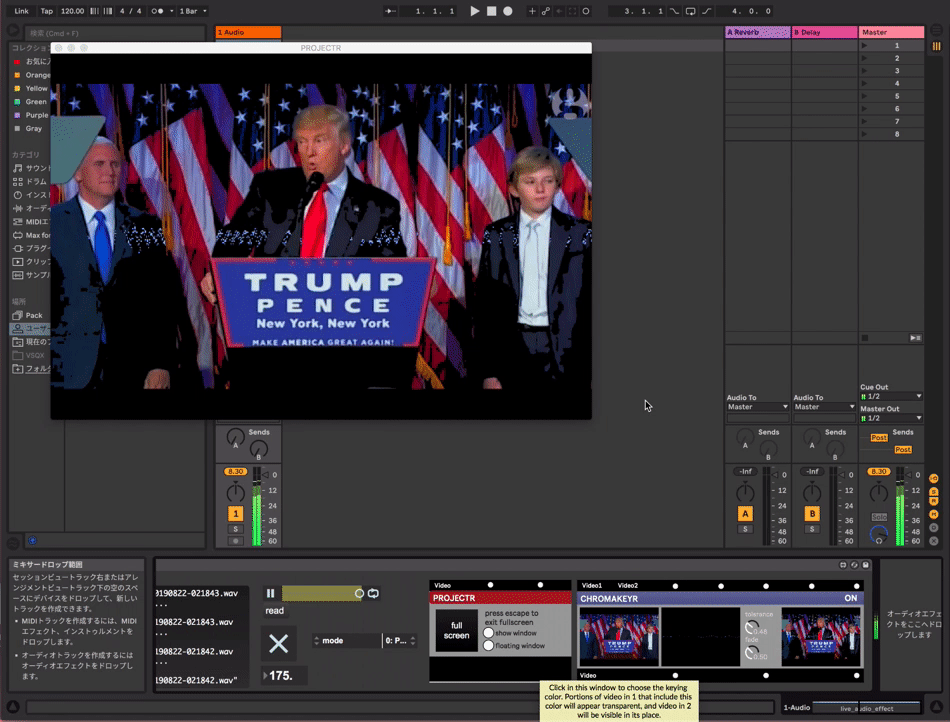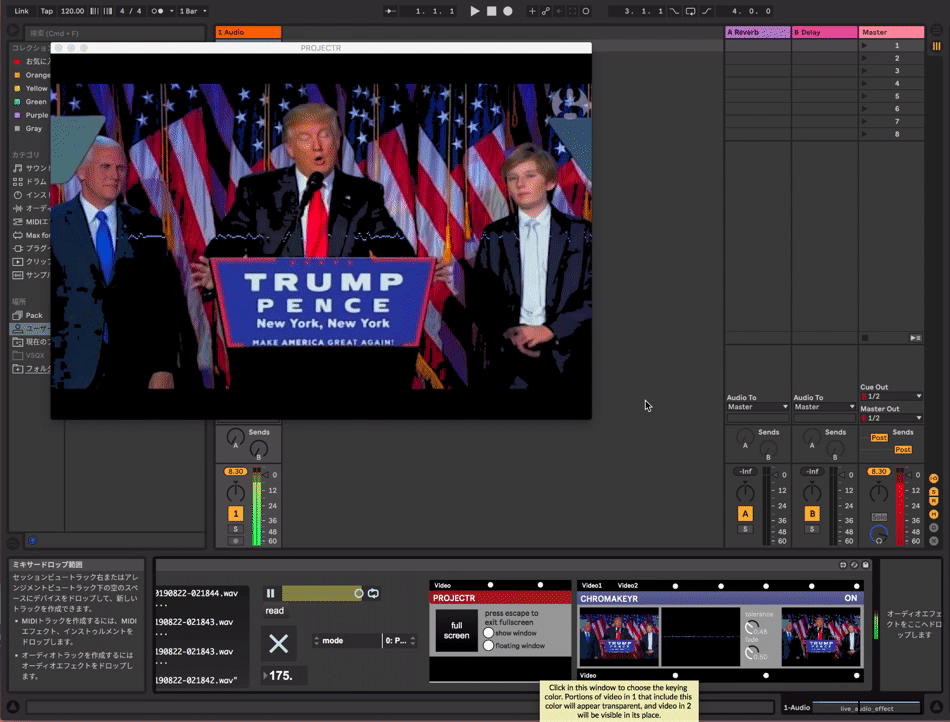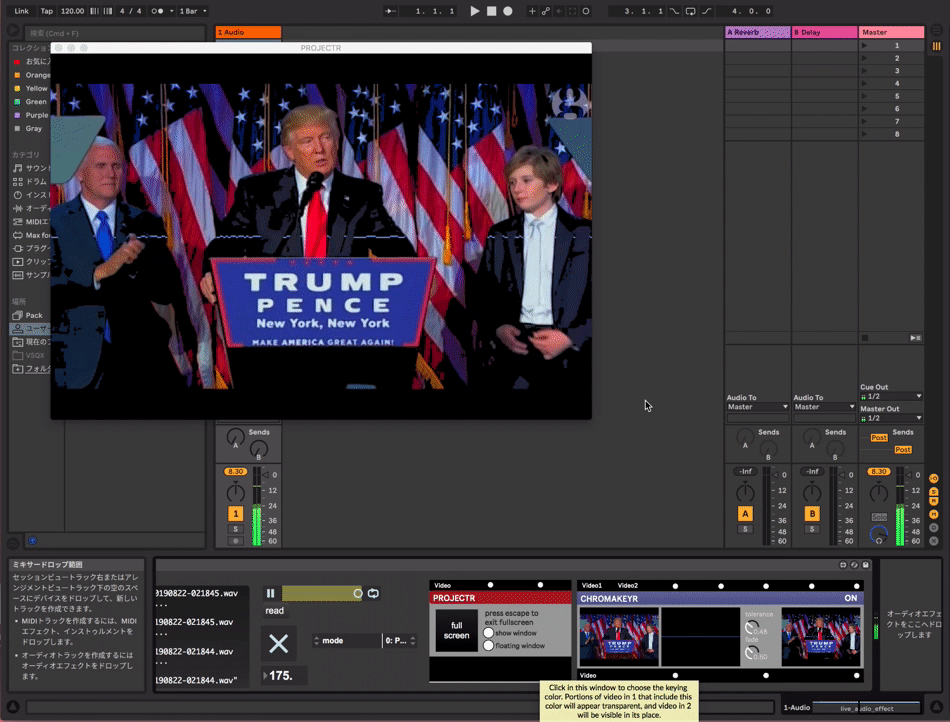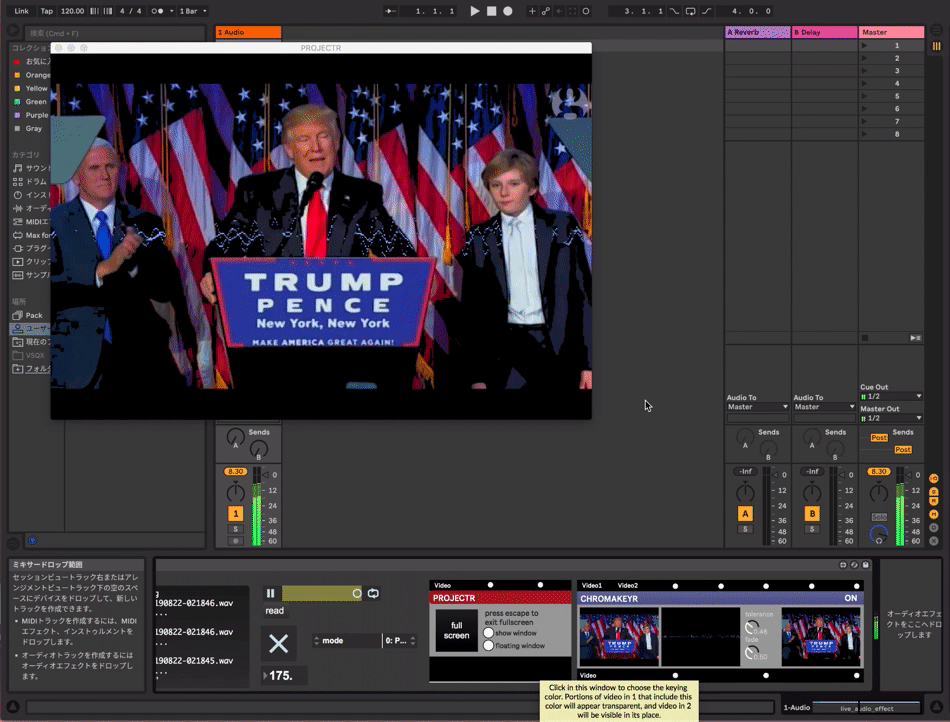
get trained model file.
# on x-sampling/
sh download_models.shinstall dependencies
pip install -r requirements.txtand start receiving OSC message.
python run.pyUse official implementation /chrisdonahue/wavegan
clone on GPGPU server and exec training
export CUDA_VISIBLE_DEVICES="0"
python train_wavegan.py train ./train --data_dir ./data/get the Dataset Speech Commands Zero through Nine (SC09) from Adversarial Audio Synthesis (ICLR 2019)
sh get_data.shor other datasets
pip install tensorflow-gpu==1.12.0
pip install scipy==1.0.0
pip install matplotlib==3.0.2
pip install librosa==0.6.2
pip install tensorboard==1.12.1or
pip install -r requirements.txton IPython (Jupyter)
import numpy as np
import tensorflow as tf
from IPython.display import display, Audio
# Load the graph
tf.reset_default_graph()
saver = tf.train.import_meta_graph('model/infer/infer.meta')
graph = tf.get_default_graph()
sess = tf.InteractiveSession()
ckpt = tf.train.get_checkpoint_state('model/')
saver.restore(sess, ckpt.model_checkpoint_path)
# Create 50 random latent vectors z
_z = (np.random.rand(1, 100) * 2.) - 1
# Synthesize G(z)
z = graph.get_tensor_by_name('z:0')
G_z = graph.get_tensor_by_name('G_z:0')
_G_z = sess.run(G_z, {z: _z})
# Play audio in notebook
display(Audio(_G_z[0, :, 0], rate=16000))import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(_G_z[0, :, 0])
# sample processor
def process(*value) -> None:
send_msg(*value)
return
from pythonosc import osc_message_builder
from pythonosc import udp_client
client = udp_client.UDPClient("127.0.0.1", 5555)
def send_msg(address: str, msg_value) -> None:
print(f"address: {address}")
print(f"msg: {msg_value}")
msg = osc_message_builder.OscMessageBuilder(address=address)
msg.add_arg(str(msg_value))
client.send(msg.build())
from pythonosc import dispatcher
from pythonosc import osc_server
dispatcher = dispatcher.Dispatcher()
dispatcher.map("/sample", process)
server = osc_server.ThreadingOSCUDPServer(("127.0.0.1", 4444), dispatcher)
server.serve_forever()