pretrain model?
lxy5513 opened this issue · comments

Hello, First thank you code very much , It help a lot.
Could you tell me that is it some pre-trained model available.
In Original Paper, Author use 1000-class imagenet model as resnet18's pre-trained model.
In chainer , are there some similarity pre-train model ?

Hi, thank your comment.
are there some similarity pre-train model ?
I know what you think, but Chainer does not provide pre-trained ResNet18 with ImageNet.
You can only get pre-trained model of ResNet'N' where N is larger than or equals to 50.
Oops, I've forgotten to say, We have a plan to release pre-trained model trained with COCO or MPII in terms of the license. We can enjoy our software without training.
@terasakisatoshi Thanks for your reply.
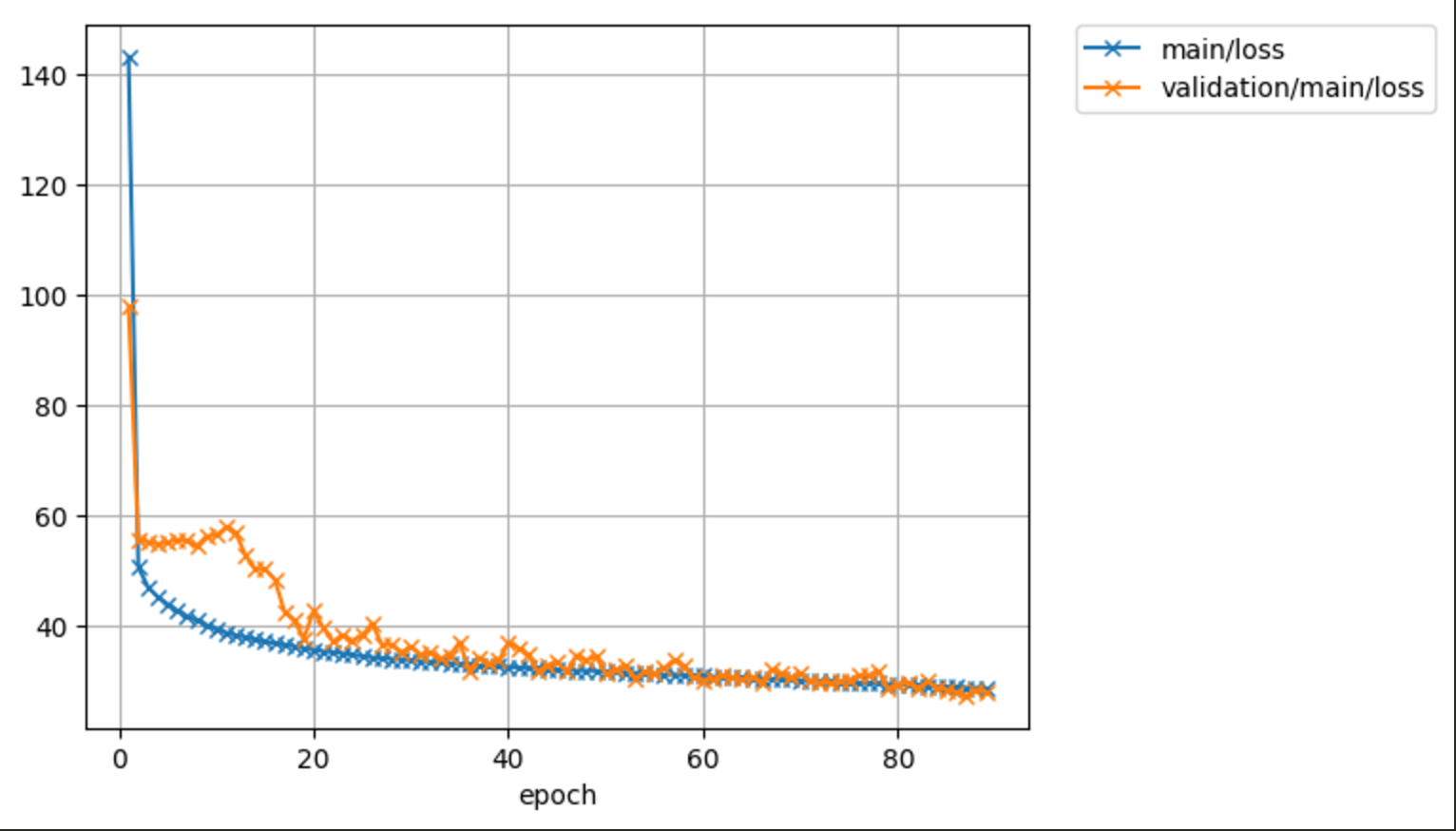
Can I ask another question? How much of your training model loss(main:loss and validation loss). ?
I trained the model by mobilenet v2 on coco dataset about 520000 iteration. The main loss and validation loss is 32 38respectively . However I think the prediction isn't not enough well .
by the way, I trained another model by mpii dataset and resnet18 after 160000 iteration, the main loss and validation loss get to better result , as below picture show,

Could you can give some advice and tell what's the loss value can get at best state ? Thank you very very much.
@lxy5513 I’m so sorry . I made a mistake Closing issue
Could you provide your config.ini used on training.
@terasakisatoshi sure , this is my config.ini
batchsize / num of gpus equals the batchsize per gpu
batchsize = 22
gpus = main=1
num_process = 8
seed = 0
train_iter = 260000
learning_rate = 0.007
mpii dataset
[mpii]
images = /data/images
annotations = /data/mpii.json
parts_scale = 0.5x0.5
instance_scale = 2.0x2.0
train_size = 0.9
min_num_keypoints = 1
Cache data on training may increase speed of training
If you have rich machine which has more than 64 GB RAM, you may set True.
use_cache = False
coco dataset
[coco]
train_images = /dataset/train2017
train_annotations = /dataset/annotations/person_keypoints_train2017.json
val_images = /dataset/val2017
val_annotations = /dataset/annotations/person_keypoints_val2017.json
parts_scale = 0.2x0.2
instance_scale = 1.0x1.0
min_num_keypoints = 5
[dataset]
must be mpii or coco
type = coco
[result]
dir = /home/ferryliu/MYRCNN/chainer/trained
[model_param]
must be mv2, resnet18, resnet34 or resnet50
model_name = mv2
input image size
insize = 224x224
set W'xH' value. it must be odd values
local_grid_size = 5x5
parameter of mobilenetv2
width_multiplier = 1.0
set weight loss. see original paper for more detail
lambda_resp = 0.25
lambda_iou = 1.0
lambda_coor = 5.0
lambda_size = 5.0
lambda_limb = 0.5
By the way, Do you have some evaluation metric code? some like mAP or PCKh , I have writed a simple method to evaluate that model , but I think it is not enough good.
Thank you for your quick reply.
Uhm... It seems you are using default value.
Did you use docker image we provided?
Otherwise could you tell me which version of Chainer CuPy and your operating system?
We are using Ubuntu 16.04
Chainer 5.0.0
CuPy 5.0.0
or
Chainer 4.5.0
CuPy 4.5.0
on training.
Do you have some evaluation metric code?
Sorry I couldn't get time to make evaluation code.
You may send PR to help us.
@terasakisatoshi
Yes, the model I use default config. another model, I only changed model_param and dataset type.
I am using Ubuntu 16.04
Chainer 5.1.0
CuPy 5.1.0
in my python virtualenv rather than docker
as PR, I am still try to improve that, if OK, maybe I have a chance to commit that to help you。I am just a programmer beginner...
We have a plan bump up version of Chainer. from 5.0.0 to 5.1.0.
I'm going study that training script works fine for the latest version.
as PR, I am still try to improve that, if OK, maybe I have a chance to commit that to help you。
Thank you!
Here is a result of PPN its base is MobileNetV2 trained with COCO.
I used the latest docker image idein/chainer:5.1.0 which contains Chainer 5.1.0 and CuPy 5.1.0.
I believe using docker image solve your problem.
I will share several results generated by predict.py










@terasakisatoshi
Thanks for your advice and examples.
I confused something about prediction speed, When the model handle video, In my single GTX1080Ti, its runtime can reach up to 115 FPS, however, when i use cpu, the runtime can only reach up 2 FPS, do you the reason? is it normal?
Did you succeed to train?
In my single GTX1080Ti, its runtime can reach up to 115 FPS
Really ? Awesome.
however, when i use cpu, the runtime can only reach up 2 FPS
Uhm...This is strange, Did you install ideep4py ? If you use CPU of Intel, It will increase prediction speed. For Ubuntu user just type
$ pip install ideep4py
is O.K.
- for my personal Macbook, 12-inch, Early 2015 1.2 GHz Intel Core M. It runs 3 or 4 FPS (This machine does not install ideep4py).
- for my DELL XPS 9350 Core i7 model with ideep4py, it runs 9 FPS at least.
Hope it helps.
@terasakisatoshi
Thanks for you instruction. I am sorry for that It’s been a long time to reply to you. I have been finish that metric code.
Yes, I succeed to train, The result is pretty good, as follow:





afetr install ideep4py
for my Intel(R) Core(TM) i7-6850K CPU @ 3.60GHz , it runs 6 FPS.
thank you very much for your advice again
just a moment ago, I finished the metric code, which only support mpii for now. but the mAP only can reach about 30, too low.
This is my code, are there some problem in my metric code?
this is my code:
metric.txt
@terasakisatoshi
I use the ideep4py vresion is 2.0.0.post3, could you tell me which version do you use? thank you ~
Nice work! I'm very glad to see your result.
And Thank you for sharing your metric.txt.
I will see your code.
I use the ideep4py vresion is 2.0.0.post3, could you tell me which version do you use?
I'm using same ideep4py of yours.
for my Intel(R) Core(TM) i7-6850K CPU @ 3.60GHz , it runs 6 FPS.
I think running high_speed.py will increase inference speed rather than video.py.
@terasakisatoshi
Thanks for your advice
this my iddep4py version:
ideep4py==2.0.0
Because taht I run code by ssh on remote gpu server, so I cannot use video.py or high_speed.py, This is my simple code that handle video :
mp4_handle.txt
@terasakisatoshi
Maybe the reason that my inference speed slow is that cpu used for train. when I stop train, the inference speed can reach 8 FPS
by the way, In my mac (3.2 GHz Inter Core i5) without ideep4py
the inference speed also can reach 7 FPS
however, In my Intel(R) Core(TM) i7-6850K CPU @ 3.60GHz
sometime the speed sudden get show suddenly,
say in other words,that intel64.is_ideep_available() == False
I really don't know why.
I have to change another virtualenv, and install relative packages again.
We will close this issue because out discussion is out of title.
We are going to provide pre-trained model (see Issue #7)
If someone has question, please submit another issue. Thank you.