"tuple index out of range" when using self attention layer in imdb dataset
Larry955 opened this issue · comments

Hi, I followed the steps to use self-attention layer just as README.md did but I got an error when I created my own model.
Here is my code:
from keras.datasets import imdb # the dataset I used
# ....
review_input = Input(shape=(MAX_WORDS_PER_REVIEW,), dtype='int32')
embedding_layer = Embedding(MAX_WORDS, EMBEDDING_DIM, input_length=MAX_WORDS_PER_REVIEW)
embedding_review = embedding_layer(review_input)
lstm = LSTM(100)(embedding_review)
att_lstm = SelfAttention(units=100, attention_activation="sigmoid")(lstm) # I used Attention Layer after LSTM layer
preds = Dense(1, activation='sigmoid')(att_lstm)
model = Model(review_input, preds)
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
Here is the error:
"self_attention.py", line 106, in **_build_additive_attention**
feature_dim = int(input_shape[2])
IndexError: tuple index out of range
It seems that the dimension is not suitable, but I don't know why this happened, since the code worked without the attention layer.


This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.


You need to add return_sequences=True to the LSTM layer
Already tried it, yet not working

I'm also having errors on model building using Keras-self-attention.
error:
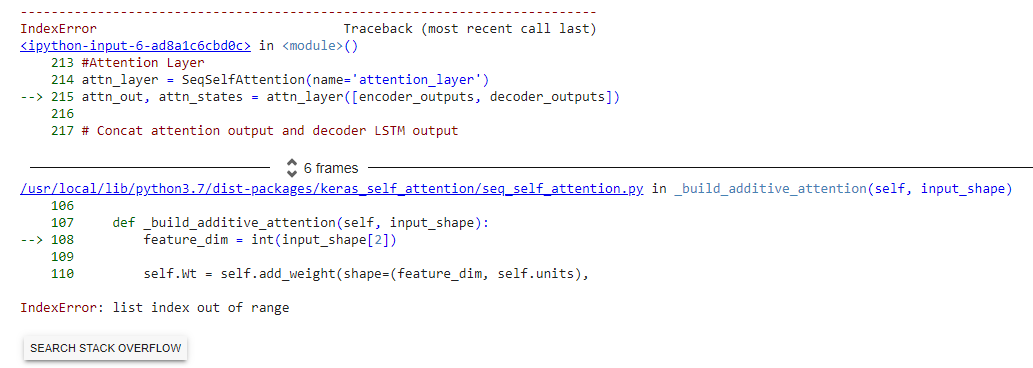
Note: This error only occurs when I run code on goggle colab. and it runs fine with accurate output on my Local machine using anaconda spyder.

I am having the exact same problem. And I think there is another problem in communications regarding this issue. I tried two solutions provided: "SeqWeightedAttention" or "return_sequence=True in the previous LSTM layer", and both didn't work. SeqWeightedAttention gave the exact same error and I don't have LSTM layer so the second solution doesn't even make any sense.