c++ sample code for trt inference
kaishijeng opened this issue · comments

I am looking for C++ sample code for TRT inference. Does anyone know where I can find it?
Thanks,

@kaishijeng ok, later


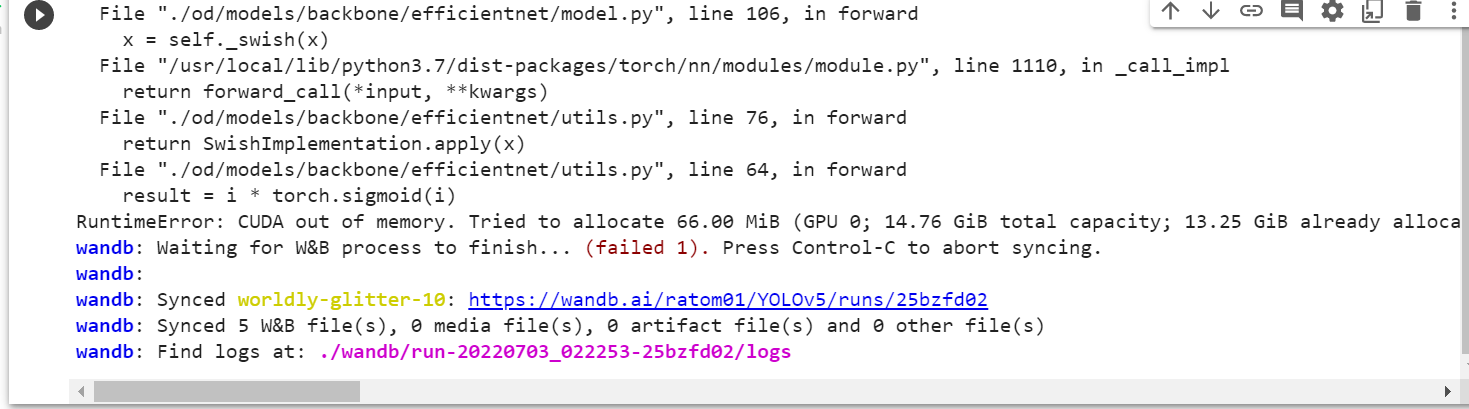
Error since yesterday's update.
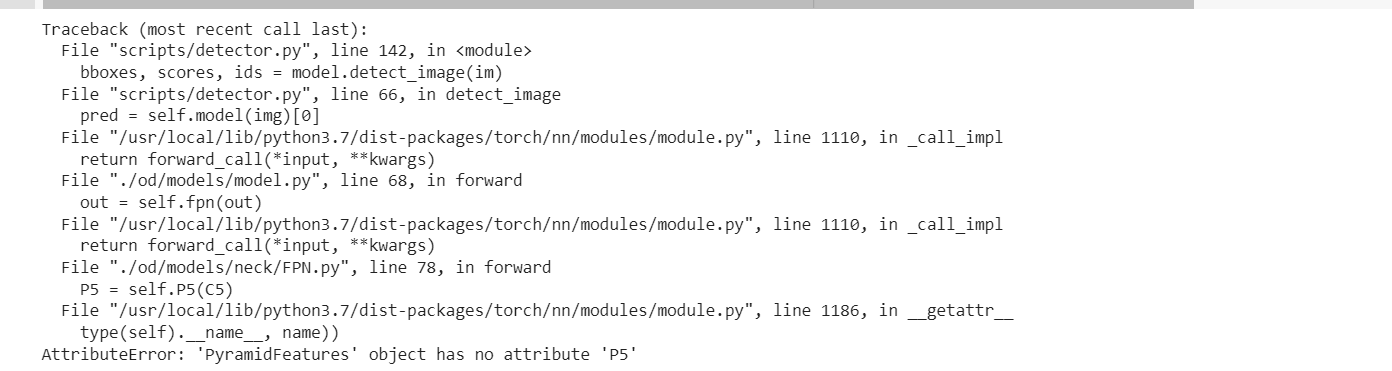
this may be your batchsize too big or network version too big,
Do not use new code to load the previous version model weights, their FPN and PAN nodes are different.
this may be your batchsize too big or network version too big,
I used batch size of 4 and epochs 5, but still getting the cuda out of memory issue. But it was running smoothly on yesterday.
Can I get previous version. If yes can you mail me at dulalatom@gmail.com.
Thanks
Can I get previous version. If yes can you mail me at dulalatom@gmail.com. Thanks
in branch main or release v1.0.0. Due to a large number of updates, I only verified the original yolov5 backbone, and I am in the process of verifying the others.
this may be your batchsize too big or network version too big,
I used batch size of 4 and epochs 5, but still getting the cuda out of memory issue. But it was running smoothly on yesterday.
I train efficientnet B1, No problems found
Ok thanks
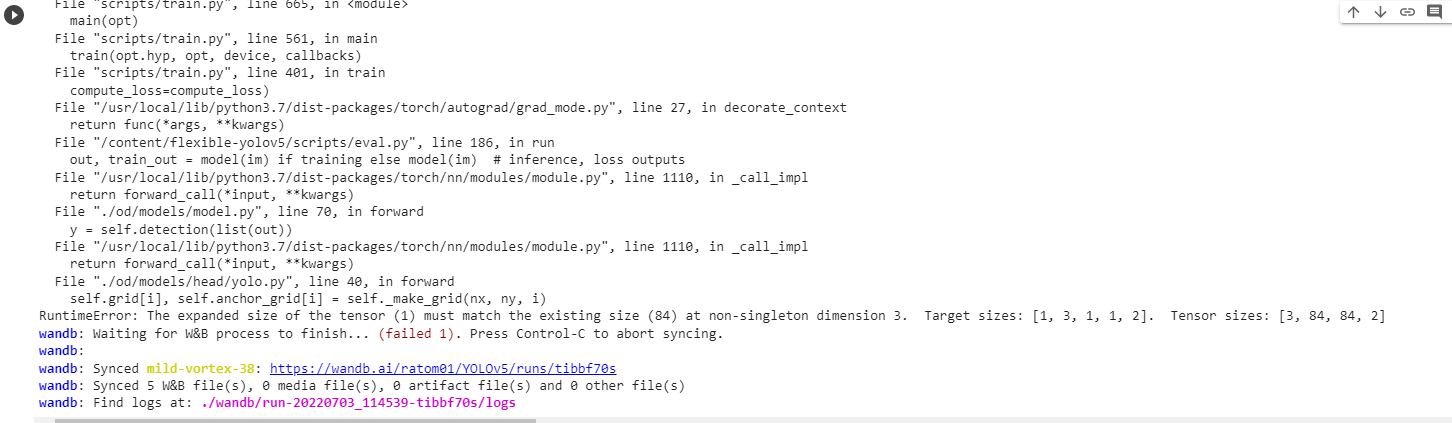
I don't know why, I am using 4 batch size and for 5 epochs. In this case also I got the error like this. Any suggestions to fix the error please
please give me your model config

I have 22 classes
and this is for efficientnet b7. I experienced cuda out of memory. But when I trained yesterday this time, it was working properly

Starting training for 5 epochs...
Epoch gpu_mem box obj cls labels img_size
0% 0/28 [00:00<?, ?it/s]
Traceback (most recent call last):
File "scripts/train.py", line 665, in
main(opt)
File "scripts/train.py", line 561, in main
train(opt.hyp, opt, device, callbacks)
File "scripts/train.py", line 352, in train
pred = model(imgs) # forward
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "./od/models/model.py", line 67, in forward
out = self.backbone(x)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "./od/models/backbone/efficientnet/model.py", line 314, in forward
x = self.extract_endpoints(inputs)
File "./od/models/backbone/efficientnet/model.py", line 263, in extract_endpoints
x = block(x, drop_connect_rate=drop_connect_rate)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "./od/models/backbone/efficientnet/model.py", line 105, in forward
x = self._bn0(x)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/batchnorm.py", line 179, in forward
self.eps,
File "/usr/local/lib/python3.7/dist-packages/torch/nn/functional.py", line 2422, in batch_norm
input, weight, bias, running_mean, running_var, training, momentum, eps, torch.backends.cudnn.enabled
RuntimeError: CUDA out of memory. Tried to allocate 450.00 MiB (GPU 0; 14.76 GiB total capacity; 12.60 GiB already allocated; 399.75 MiB free; 12.98 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
wandb: Waiting for W&B process to finish... (failed 1). Press Control-C to abort syncing.
wandb:
wandb: Synced golden-hill-40: https://wandb.ai/ratom01/YOLOv5/runs/1c1fw4pt
wandb: Synced 5 W&B file(s), 0 media file(s), 0 artifact file(s) and 0 other file(s)
wandb: Find logs at: ./wandb/run-20220703_121904-1c1fw4pt/logs
there are some problems with hrnet in branch v2, so don't use hrnet for now, let me fix it. and for efficientnet b7, I use coco2017 80 classes, batchsize 4, on A100, use 20.7G gpu_mem, so your gpu can't support it
thank you for the help
thank you for the help
indeed, the b7 in branch main take 10G gpu_mem, but the old FPN and PAN have some architectural Issues(It is not exactly the same as the original yolov5, but it does not affect the use.), I think the code
in v2 should be correct, and I will further verify it recently.
Thanks. I am using colab GPU as it has limited memory. But day before yesterday, I used the main branch and trained b1 and forget to save the weights. I would like to run all backbones and learning to code. Not an expert level. Anyway thanks for your help.
for this error, i know why, yhe latest eval script has some bug, the eval script in main run succ
for this error, i know why, yhe latest eval script has some bug, the eval script in main run succ
There is no problem when using ‘’‘ python scripts.eval.py ’‘’directly, and there will be problems when calling it through scripts/train.py.
I also found error in mdoel.py and Shufflenetv2.py with from
torchvision.models.utils import load_state_dict_from_url
this is solved by when replacing with from torch.hub import load_state_dict_from_url
for this error, i know why, yhe latest eval script has some bug, the eval script in main run succ
There is no problem when using ‘’‘ python scripts.eval.py ’‘’directly, and there will be problems when calling it through scripts/train.py. for temporary, so you can add. --noval in train command, after training, use python scripts/eval.py
for this error, i know why, yhe latest eval script has some bug, the eval script in main run succ
There is no problem when using ‘’‘ python scripts.eval.py ’‘’directly, and there will be problems when calling it through scripts/train.py. for temporary, so you can add. --noval in train command, after training, use python scripts/eval.py
Fix, Done!
for this error, i know why, yhe latest eval script has some bug, the eval script in main run succ
There is no problem when using ‘’‘ python scripts.eval.py ’‘’directly, and there will be problems when calling it through scripts/train.py. for temporary, so you can add. --noval in train command, after training, use python scripts/eval.py
Fix, Done!
I tried swin and got this error. Can you fix it please.
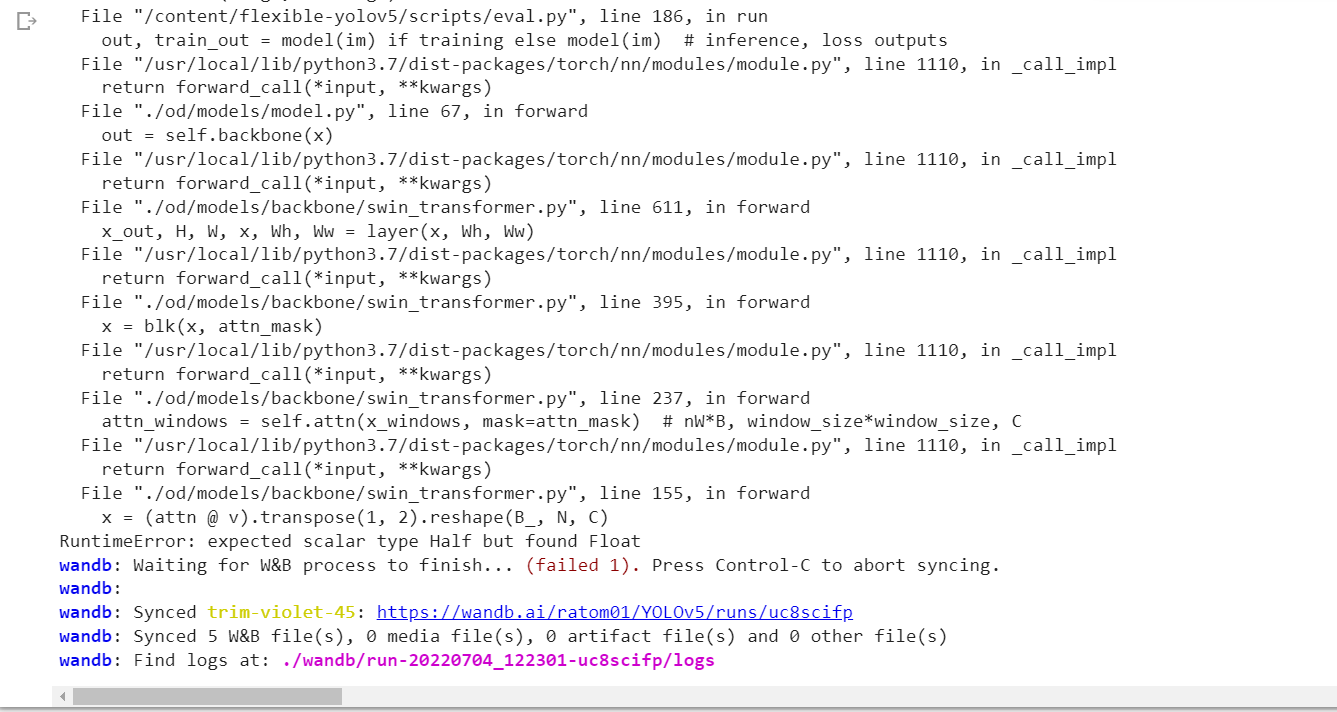
for this error, i know why, yhe latest eval script has some bug, the eval script in main run succ
There is no problem when using ‘’‘ python scripts.eval.py ’‘’directly, and there will be problems when calling it through scripts/train.py. for temporary, so you can add. --noval in train command, after training, use python scripts/eval.py
Fix, Done!
I tried swin and got this error. Can you fix it please.
set half=False in eval.py
for this error, i know why, yhe latest eval script has some bug, the eval script in main run succ
There is no problem when using ‘’‘ python scripts.eval.py ’‘’directly, and there will be problems when calling it through scripts/train.py. for temporary, so you can add. --noval in train command, after training, use python scripts/eval.py
Fix, Done!
I tried swin and got this error. Can you fix it please.
set half=False in eval.py
I will try to run all backbones, and will comment if found some errors. Thanks
for this error, i know why, yhe latest eval script has some bug, the eval script in main run succ
There is no problem when using ‘’‘ python scripts.eval.py ’‘’directly, and there will be problems when calling it through scripts/train.py. for temporary, so you can add. --noval in train command, after training, use python scripts/eval.py
Fix, Done!
I tried swin and got this error. Can you fix it please.
set half=False in eval.py
last time, open a new issue, please, 100 issue is coming! hahaha
for this error, i know why, yhe latest eval script has some bug, the eval script in main run succ
There is no problem when using ‘’‘ python scripts.eval.py ’‘’directly, and there will be problems when calling it through scripts/train.py. for temporary, so you can add. --noval in train command, after training, use python scripts/eval.py
Fix, Done!
I tried swin and got this error. Can you fix it please.
set half=False in eval.py
last time, open a new issue, please, 100 issue is coming! hahaha
I tried setting half =False. Still not fixed. Can you fix it please
for this error, i know why, yhe latest eval script has some bug, the eval script in main run succ
There is no problem when using ‘’‘ python scripts.eval.py ’‘’directly, and there will be problems when calling it through scripts/train.py. for temporary, so you can add. --noval in train command, after training, use python scripts/eval.py
Fix, Done!
I tried swin and got this error. Can you fix it please.
set half=False in eval.py
last time, open a new issue, please, 100 issue is coming! hahahaI tried setting half =False. Still not fixed. Can you fix it please
That's strange. I tested swin tiny and small, both of which are normal
and this is for efficientnet b7. I experienced cuda out of memory. But when I trained yesterday this time, it was working properly
Epoch gpu_mem box obj cls labels img_size0% 0/28 [00:00<?, ?it/s] Traceback (most recent call last): File "scripts/train.py", line 665, in main(opt) File "scripts/train.py", line 561, in main train(opt.hyp, opt, device, callbacks) File "scripts/train.py", line 352, in train pred = model(imgs) # forward File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1110, in _call_impl return forward_call(*input, **kwargs) File "./od/models/model.py", line 67, in forward out = self.backbone(x) File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1110, in _call_impl return forward_call(*input, **kwargs) File "./od/models/backbone/efficientnet/model.py", line 314, in forward x = self.extract_endpoints(inputs) File "./od/models/backbone/efficientnet/model.py", line 263, in extract_endpoints x = block(x, drop_connect_rate=drop_connect_rate) File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1110, in _call_impl return forward_call(*input, **kwargs) File "./od/models/backbone/efficientnet/model.py", line 105, in forward x = self._bn0(x) File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1110, in _call_impl return forward_call(*input, **kwargs) File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/batchnorm.py", line 179, in forward self.eps, File "/usr/local/lib/python3.7/dist-packages/torch/nn/functional.py", line 2422, in batch_norm input, weight, bias, running_mean, running_var, training, momentum, eps, torch.backends.cudnn.enabled RuntimeError: CUDA out of memory. Tried to allocate 450.00 MiB (GPU 0; 14.76 GiB total capacity; 12.60 GiB already allocated; 399.75 MiB free; 12.98 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF wandb: Waiting for W&B process to finish... (failed 1). Press Control-C to abort syncing. wandb: wandb: Synced golden-hill-40: https://wandb.ai/ratom01/YOLOv5/runs/1c1fw4pt wandb: Synced 5 W&B file(s), 0 media file(s), 0 artifact file(s) and 0 other file(s) wandb: Find logs at: ./wandb/run-20220703_121904-1c1fw4pt/logs
now, you can train the b7 model,please pull new code, I fixed the PAN outputs channel, now it's same as U-yolov5
I am looking for C++ sample code for TRT inference. Does anyone know where I can find it?
Thanks,
Done, see scripts/trt_infer/cpp