![]()


Datadrift is an agnostic and lightweight storage and version-control technology to track changes to mutable data sources
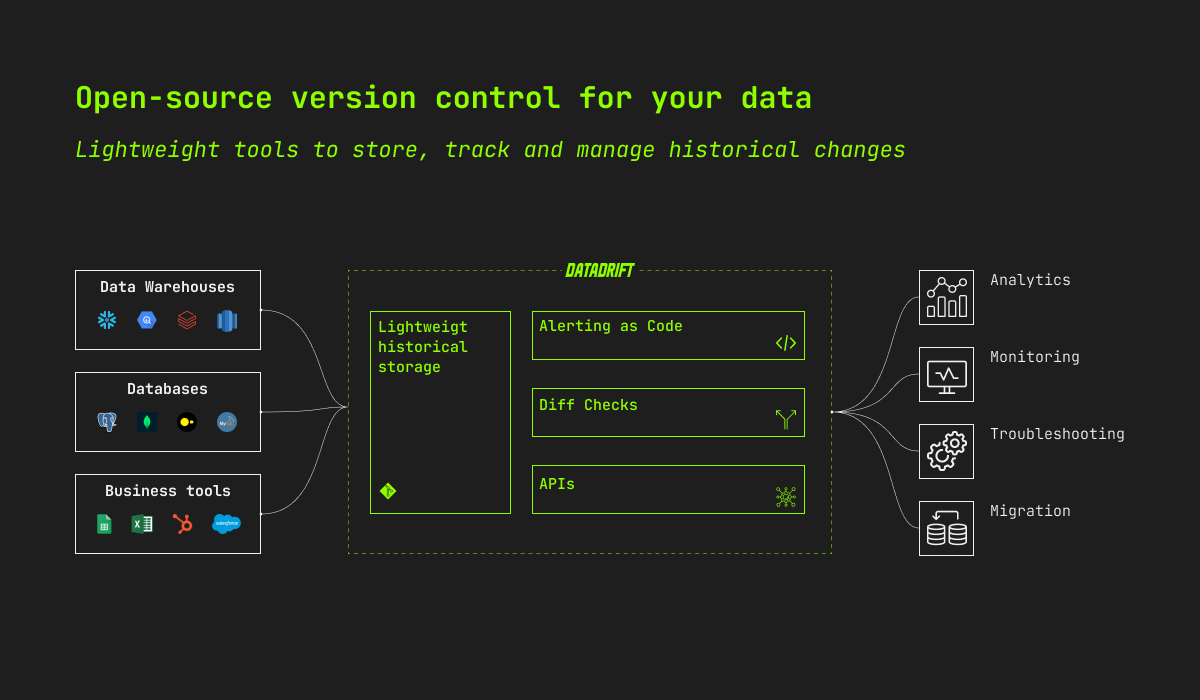
Tools, databases and warehouses have a hard time tracking and displaying historical changes.
-
For a very large majority of companies, there no access to historical state of their own data (ie. how data changes over time)
-
For a selected few, keeping track of historical changes is made at a great cost of data engineering and outdated modeling trade-offs
DataDrift makes handling data history easy with modern and open-source version control tools for data.
-
Easy to implement (<15min): Add 1 line of code in your pipeline to historize data. Use the one-click install on your CRM, spreadsheet or any data source (coming soon, open an issue to request a specific connector, or contribute to the community building it directly 😇)
-
Free: Reduce your storage and optimize your warehouse bill with our ligthweight storage for data history. Storage is done in a dedicated git repository, no additional cost if you use Github.
-
Secure: Deploy on your own infra to keep 100% control over your data and access
-
Flexible: compose your own Datadrift based on our building blocks
-
Integrated: not another tool to manage in your stack, DataDrift is API-first and stays within your current tools
Unlock targeted use-cases with specific tools on top of our versioning and diffing technology.
Here are some examples of how users leverage Datadrift.
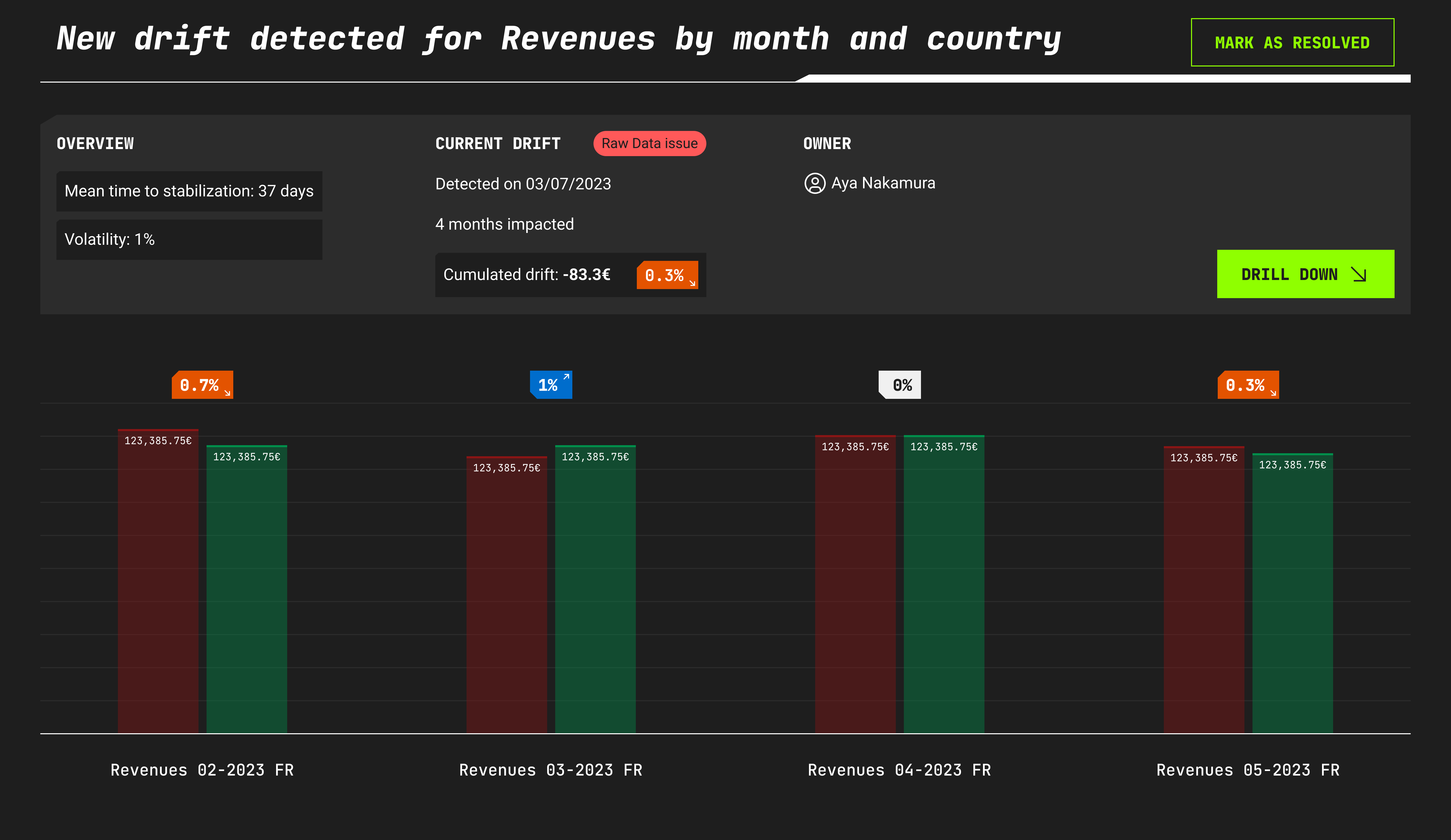
How can you expect a data analyst to detect a data quality issue when all they see is a number that is slightly higher or lower on each report?
Become aware of unknown unknowns in your data quality with data or metric drift alerting. Monitor the quality and consistency of your reporting and metrics over time.
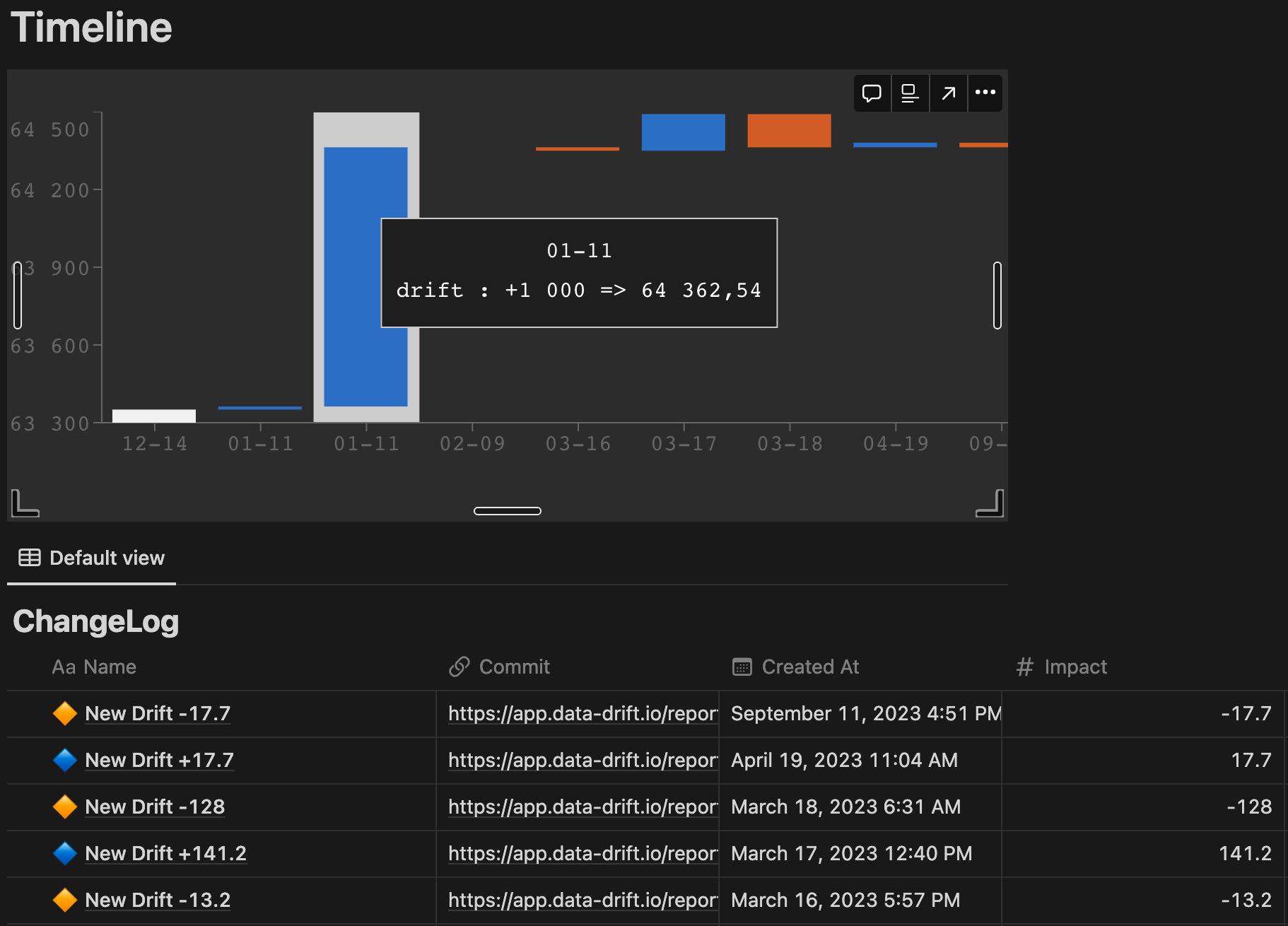
Operationalize your monitoring and solve your underlying data quality issue with drill-down across historical data to understand the root cause of the problem.
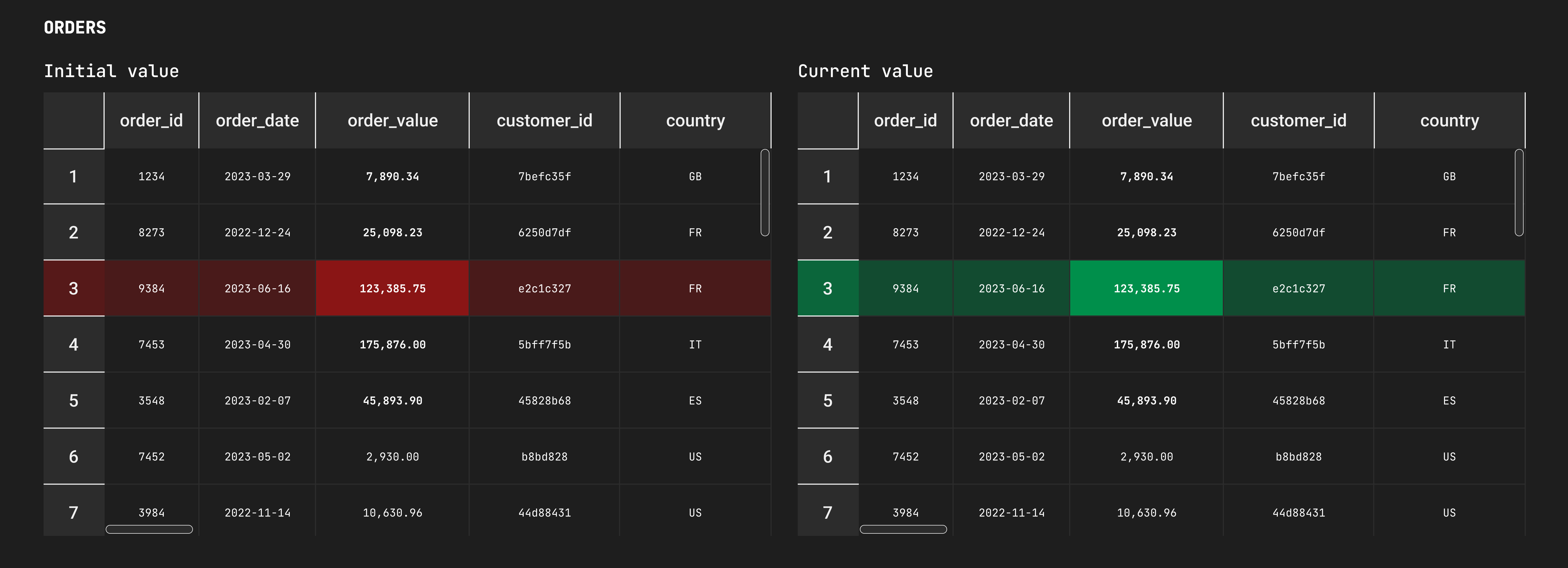
Migrate without hassle and safely between tools with comparison and diff-checks before/after and within/across databases.
We'd love to hear from you if you have any other use case. Just open a new issue to tell us more about it and see how we could help!
Install Datagit to historise and diff-checks the data you want.
This is a mandatory step to unlock any use cases on top i. You can learn more about Datagit in this article.
Follow our step-by-step installation guide to use Datadrift.
Contact our team by filling the form on our website to get started with Datadrift Cloud.
We 💚 contributions big and small. In priority order (although everything is appreciated) with the most helpful first:
- Star this repo to help us get visibility
- Become a Design Partner to co-built a product you & users love
- Open an issue to share your idea or a bug you might have spotted
🌀 Automatic lineage drill-down and diff checks. Learn more about this feature
🗓 Warehouse (BigQuery, Snowflake) & databases (Postgres, MongoDB) native integrations
🗓 BI tools integration
🗓 Gsheet integration
Track planning on Github Projects and help us prioritising by upvoting or creating issues.