imagenet1k pretrain model
cissoidx opened this issue · comments

Why do we need to load pretrained ImageNet-1K model if we are going to pretrain based on the imagenet21k dataset?

to shorten the training.
if you start from scratch, you need significant longer training
Could you please provide typical training time if I start from scratch?
And in the paper, table 3, your pretraining started from scratch or actually pre-pretrained on imagenet1k?
thanks
Moreover, in table 3, if you are doing downstream task, which is imagenet1k classification, a pre-pretraining using imagenet1k (which will be the downstream task itself) sounds not very appropriate, right?
use a code from https://github.com/rwightman/pytorch-image-models, which specializes in imagenet-1K training.
i am not gonna provide direct code for every downstream dataset.
regarding imagenet1k as both pretraining and downstream, you can avoid that if you want, just do 300 epochs on imagenet21K from scratch, instead of 80 epochs.
in any case, this does not bias the scores, since I have not used imagenet1k validation set in any stage. also, the training pictures of imagenet1k are in any case contained in imagenet21K dataset
Thanks for you reply.
I was talking about training time, rather than code repo. But the info you provided is very useful. thanks.
I was just thinking if the official checkpoint has used imagenet1k before pretraining to make things comparable. Anyway, it seems that official site did not mention about this.
thanks again.
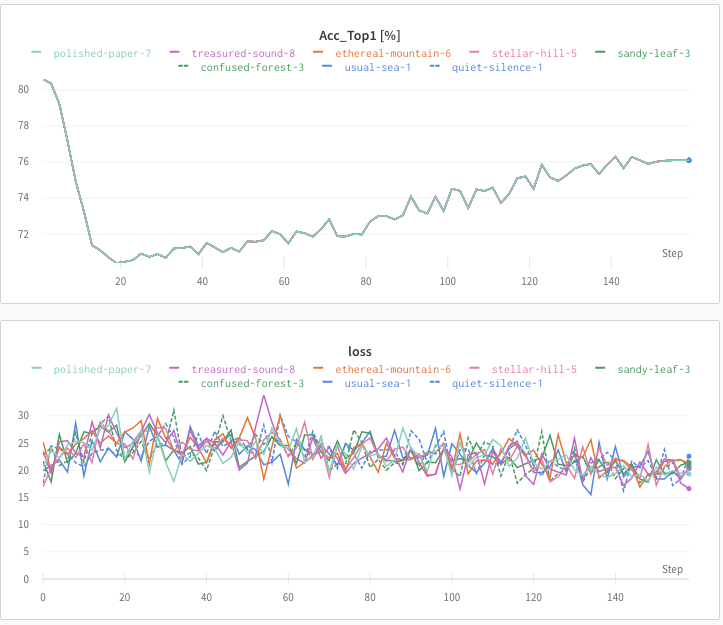
@mrT23 Hi man, you mentioned the pretrained models in the README file, I used the vit_base_patch16_224_miil model for pretraining the processed winter version of imagenet and I got very weird loss curve. The acc_top1 is more than 80% and then it decreases, it finally started to increase again after LR warmup. So I doubt that this model is actually pretrained on 21k rather than 1k. Have you tried to train based on the timm vit_base_patch16_224_miil model?
21K:
model = timm.create_model('mobilenetv3_large_100_miil_in21k', pretrained=True)
model = timm.create_model('tresnet_m_miil_in21k', pretrained=True)
model = timm.create_model('vit_base_patch16_224_miil_in21k', pretrained=True)
model = timm.create_model('mixer_b16_224_miil_in21k', pretrained=True)
1K:
model = timm.create_model('mobilenetv3_large_100_miil', pretrained=True)
model = timm.create_model('tresnet_m', pretrained=True)
model = timm.create_model('vit_base_patch16_224_miil', pretrained=True)
model = timm.create_model('mixer_b16_224_miil', pretrained=True)
@cissoidx
i am not sure i understood the scenario, or the motivation.
'vit_base_patch16_224_miil' is after finetuning on imagenet1K, so the 21K pretrain is somewhat "lost" (fine-tuning on smaller dataset always ruins the pretrain quality)
'vit_base_patch16_224_miil_in21k' is the pretrain directly on 21K, 11-fall version. why aren't you using it ?
I want to reproduce the pretraining on imagent21k-p. So I used vit_base_patch16_224_miil to initialize the model.
'vit_base_patch16_224_miil' is after finetuning on imagenet1K, so the 21K pretrain is somewhat "lost" (fine-tuning on smaller dataset always ruins the pretrain quality)
this is exactly what I expected and what i intended to do(train on in21k with 1k initialized weights), but what I got is the above result in figure. So I am guessing that the vit_base_patch16_224_miil is actually pretrained on in21k and placed on that url by mistake.
" So I am guessing that the vit_base_patch16_224_miil is actually pretrained on in21k and placed on that url by mistake. "
i don't think so. look at the results in:
https://github.com/rwightman/pytorch-image-models/blob/master/results/results-imagenet.csv (line 55)
it was finetuned on 1k, to a top score

Hi @mrT23, I wonder when pretraining the vit_base_patch16_224 with semantic_softmax on in21k dataset, which in1k weights do you use to initialize the model? Is it the 'vit_base_patch16_224' weights provided by timm (https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py#L84)?
@Dyfine
i did use weights from timm, although I think they have might updated the weights from the time I did the training (couple of months ago)
anyway, I believe the pretraining of transformers might be even further improved by exploiting tricks from DeiT (mixup+cutmix+big wd +adamw+large lr + ...). you are welcome to explore this issue and share your findings.
@mrT23 do you have training stats (eg acc, loss, lr, etc...), like saved using log file , screen output, wandb, tensorboard stuff, when you pretrain in21k from in1k weights? The model head of vit_base_patch16_224_miil is 1k classes, so I guess timm is not making a mistake, which makes my training curve really weird.

@Dyfine
i did use weights from timm, although I think they have might updated the weights from the time I did the training (couple of months ago)anyway, I believe the pretraining of transformers might be even further improved by exploiting tricks from DeiT (mixup+cutmix+big wd +adamw+large lr + ...). you are welcome to explore this issue and share your findings.
I'm confused with the script. As you use the pretrained model of timm, why do you load model weights from external files instead of setting pretrained as True (like the following script)? Is there any essential difference?
model = timm.models.vision_transformer._create_vision_transformer('vit_base_patch16_224', pretrained=True, num_classes=args.num_classes, **model_kwargs)
@mrT23 thanks, I agree with you that the weights from timm are updated from ViT paper [1] weights to their new AugReg paper [2] weights (thus the top-1 acc on i1k seems improved).
[1] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
[2] How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers
@chwan-rice I guess that the 'qkv_bias' is set to False and it may lead to error when loading 'vit_base_patch16_224' weights by setting 'pretrained=True' ?
(https://github.com/Alibaba-MIIL/ImageNet21K/blob/main/src_files/models/utils/factory.py#L44)
use a code from https://github.com/rwightman/pytorch-image-models, which specializes in imagenet-1K training.
i am not gonna provide direct code for every downstream dataset.regarding imagenet1k as both pretraining and downstream, you can avoid that if you want, just do 300 epochs on imagenet21K from scratch, instead of 80 epochs.
in any case, this does not bias the scores, since I have not used imagenet1k validation set in any stage. also, the training pictures of imagenet1k are in any case contained in imagenet21K dataset
@mrT23 have you read this paper?
While performing the above analysis,
we observed a subtle, but severe issue with models pre-trained on ImageNet-21k and transferred
to ImageNet-1k dataset. The validation score for these models (especially for large models) is not
well correlated with observed test performance, see Figure 5 (left). This is due to the fact that
ImageNet-21k data contains ImageNet-1k training data and we use a “minival“ split from the training
data for evaluation (see Section 3.1). As a result, large models on long training schedules memorize
the data from the training set, which biases the evaluation metric computed in the “minival“ evaluation
set. To address this issue and enable fair hyper-parameter selection, we instead use the independently
collected ImageNetV2 data [25] as the validation split for transferring to ImageNet-1k.
@cissoidx
the validation set of ImageNet-1K is not contained in ImageNet-21k. i checked (and you are welcome to validate me).
i don't really like the paper you mentioned. while they mention timm (PyTorch) lots of times, they don't provide even a minimal training code on it for ImageNet-21K. This is a sign that they don't really want to share their knowledge, and make it accessible and practical.
as i wrote, yes
I mean, what is the check method you use? to compare image names is surely not a good way, right?
there are many other papers who did the same procedure - pretrain on 21K, and transfer to 1K.
i am the only one who tried to validate that there is no overlap in validation set.
According to my check - there isn't (according to names. hash is slow for such large datasets).
if you have another viable idea how to do this, you should try to validate this yourself, and share your results
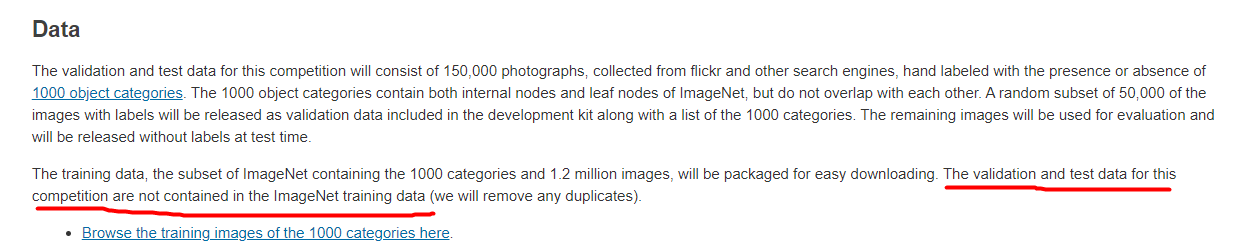
Sure, what you did is really helpful and insightful. I am just not sure if I get what you mean. The imagenet1k validation datasets images are named like this: ILSVRC2012_val_00013028.JPEG, which is not, of course, the same as training dataset image names. So if you compare these images names to in1k/in21k training dataset image names, there wont be any overlap/duplicate.
thanks for clarifying

They just say that that the ImageNet1K train data is disjoint from its validation set. This does not mean that the whole data set does not contain duplicates. They do not state anything about this there.
Also, do you make sure that no ImageNet1K training data is in your 21K-P validation data?