crawlergo_x_XRAY
360 0Kee-Team 的 crawlergo动态爬虫 结合 长亭XRAY扫描器的被动扫描功能 (其它被动扫描器同理)
https://github.com/0Kee-Team/crawlergo
https://github.com/chaitin/xray
20201130更新,launcher_new.py增加随机http请求头,避免被扫描器识别。
注:需在pip安装 fake_useragent 库
pip install fake_useragent
20190115更新,launcher_new.py使用crawlergo提供的方法推送请求给xray
crawlergo默认推送方法有个不足就是无法与爬虫过程异步进行。使用launcher.py可以异步节省时间。
注:若运行出现权限不足,请删除crawlergo空文件夹。
如遇到报错注意将64位的crawlergo.exe和launcher.py还有targets.txt放在一个目录,将crawlergo目录删除
20190113更新,增加容错,解决访问不了的网站爬虫卡死。
介绍
一直想找一个小巧强大的爬虫配合xray的被动扫描使用,曾经有过自己写爬虫的想法,奈何自己太菜写一半感觉还没有awvs的爬虫好用
360 0Kee-Teem最近公开了他们自己产品中使用的动态爬虫模块,经过一番摸索发现正合我意,就写了这个脚本
由于该爬虫并未开放代理功能并且有一些从页面抓取的链接不会访问,所以我采用的官方推荐的方法,爬取完成后解析输出的json再使用python的request库去逐个访问
大概逻辑为:
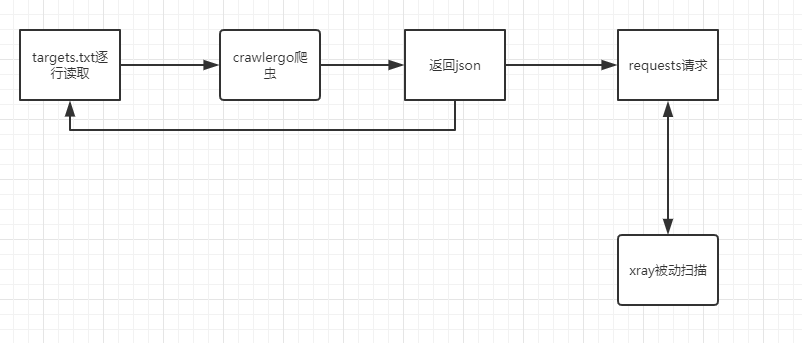
爬取和请求的过程使用了多线程和队列使得请求不会阻塞下一个页面的爬取
用法
1. 下载xray最新的release, 下载crawlergo最新的release
注意,是下载编译好的文件而不是git clone它的库
2. 把launcher.py和targets.txt放在crawlergo.exe同目录下
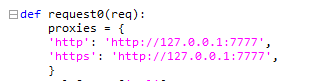
3. 配置好并启动xray被动扫描(脚本默认配置为127.0.0.1:7777)若修改端口请同时修改launcher.py文件中的proxies

配置参数详见XRAY官方文档
4. 配置好launcher.py的cmd变量中的crawlergo爬虫配置(主要是chrome路径改为本地路径), 默认为:
./crawlergo -c C:\Program Files (x86)\Google\Chrome\Application\chrome.exe -t 20 -f smart --fuzz-path --output-mode json target

配置参数详见crawlergo官方文档
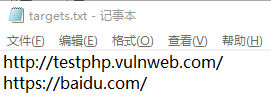
5. 把目标url写进targets.txt,一行一个url
6. 用python3运行launcher.py ( XRAY被动扫描为启动的状态 )
7. 生成的sub_domains.txt为爬虫爬到的子域名, crawl_result.txt为爬虫爬到的url
🚀 Star Trend

etc
-
开源的样本大部分可能已经无法免杀,需要自行修改
-
我认为基础核心代码的开源能够帮助想学习的人
-
本人从github大佬项目中学到了很多
-
若用本人项目去进行:HW演练/红蓝对抗/APT/黑产/恶意行为/违法行为/割韭菜,等行为,本人概不负责,也与本人无关
-
本人已不参与大小HW活动的攻击方了,若溯源到timwhite id与本人无关